Storing a Segment in a Different Location: LOCATION
|
How to: |
By default, all of the segments in a FOCUS data source are stored in one physical file. For example, all of the EMPLOYEE data source segments are stored in the data source named EMPLOYEE.
Use the LOCATION attribute to specify that one or more segments be stored in a physical file separate from the main data source file. The LOCATION file is also known as a horizontal partition. You can use a total of 64 LOCATION files per Master File (one LOCATION attribute per segment, except for the root). This is helpful if you want to create a data source larger than the FOCUS limit for a single data source file, or if you want to store parts of the data source in separate locations for security or other reasons.
There are at least two cases in which to use the LOCATION attribute:
- Each physical file is individually subject to a maximum file size. You can use the LOCATION attribute to increase the size of your data source by splitting it into several physical files, each one subject to the maximum size limit. (See Defining a Join in a Master File to learn if it is more efficient to structure your data as several joined data sources.)
- You can also store your data in separate physical files to take advantage of the fact that only the segments needed for a report must be present. Unreferenced segments stored in separate data sources can be kept on separate storage media to save space or implement separate security mechanisms. In some situations, separating the segments into different data sources allows you to use different disk drives.
Divided data sources require more careful file maintenance. Be especially careful about procedures that are done separately to separate data sources, such as backups. For example, if you do backups on Tuesday and Thursday for two related data sources, and you restore the FOCUS structure using the Tuesday backup for one half and the Thursday backup for the other, there is no way of detecting this discrepancy.
Syntax: How to Store a Segment in a Different Location
LOCATION = filename [,DATASET = physical_filename]
where:
- filename
-
Is the ddname of the file in which the segment is to be stored.
- physical_filename
-
Is the physical name of the data source, dependent on the platform.
Example: Specifying Location for a Segment
The following illustrates the use of the LOCATION attribute:
FILENAME = PEOPLE, SUFFIX = FOC, $ SEGNAME = SSNREC, SEGTYPE = S1, $ FIELD = SSN, ALIAS = SOCSEG, USAGE = I9, $ SEGNAME = NAMEREC, SEGTYPE = U, PARENT = SSNREC, $ FIELD = LNAME, ALIAS = LN, USAGE = A25, $ SEGNAME = HISTREC, SEGTYPE = S1,PARENT = SSNREC, LOCATION = HISTFILE, $ FIELD = DATE, ALIAS = DT, USAGE = YMD, $ SEGNAME = JOBREC, SEGTYPE = S1,PARENT = HISTREC,$ FIELD = JOBCODE, ALIAS = JC, USAGE = A3, $ SEGNAME = SKREC, SEGTYPE = S1,PARENT = SSNREC, $ FIELD = SCODE, ALIAS = SC, USAGE = A3, $
This description groups the five segments into two physical files, as shown in the following diagram:
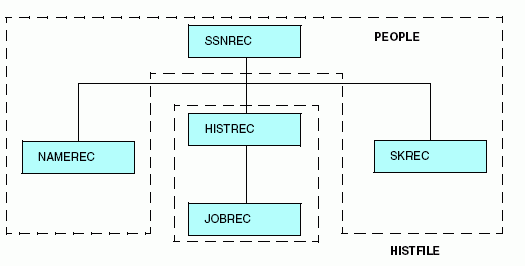
Note that the segment named SKREC, which contains no LOCATION attribute, is stored in the PEOPLE data source. If no LOCATION attribute is specified for a segment, it is placed by default in the same file as its parent. In this example, you can assign the SKREC segment to a different file by specifying the LOCATION attribute in its declaration. However, it is recommended that you specify the LOCATION attribute, and not allow it to default.