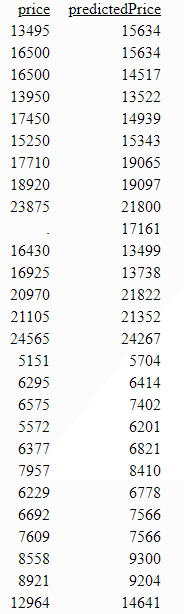Syntax: How to Calculate an Extreme Gradient Boosting Regression
REGRESS_XGB('options',
predictor_field1[, predictor_field2, ...] target_field)where:
- 'options'
-
Is a dictionary of advanced parameters that control the model attributes, enclosed in single quotation marks. Most of these parameters have a default value, so you can omit them from the request, if you want to use the default values. Even with no advanced parameters, the single quotation marks are required. The format of the advanced parameter dictionary is:
'{"parm_name1": "parm_value1", ... ,"parm_namei": "parm_valuei"}'The following advanced parameters are supported:
- "trees"
-
Is the number of decision trees in the forest. Allowed values are integers greater than 10. The default value is "300".
- "train_ratio"
-
Is a value between 0 and 1 that specifies the fraction of data used for training the model. The default value is "0.8".
- "test_ratio"
-
Is a value between 0 and 1 that specifies the fraction of data used for testing the model. The default value is "0.2".
- "early_stopping_rounds"
-
Specifies the number of added trees such that if the algorithm has not improved its performance in this many added trees, it stops. Allowed values are integers between 1 and the number of trees. The default value is "10".
- "l2_grid"
-
Is a grid consisting of comma-separated positive numbers to be used as L2-regularization strengths. The default value is "0,1,1,10". The optimal value is chosen by cross-validation.
- "kfold"
-
Is the number of folds used in the grid-search with cross-validation. Suggested values are integers between "2" and "10". The default value is "4".
- "max_depth_grid"
-
Is the maximum depth of each decision tree. A grid in the form "4,5,6" is allowed. The default value is "5". The optimal value is chosen by cross-validation.
- predictor_field1[, predictor_field2, ...]
-
Numeric or Alphanumeric
Are one or more predictor field names.
- target_field
-
Numeric
Is the target field.
Example: Predicting Price Using REGRESS_XGB
The following procedure uses REGRESS_XGB to predict price, using 400 trees and default values for the other advanced parameters, and with predictors number of doors, body style, height, horsepower, peak RPM, city MPG, and highway MPG.
TABLE FILE imports85
PRINT price
COMPUTE predictedPrice/I5 = REGRESS_XGB('{"trees":"400","early_stopping_rounds":"10",
"kfold":"4","test_ratio":"0.2"}',
numOfDoors, bodyStyle, height, horsepower,
peakRpm, cityMpg, highwayMpg, price);
WHERE price LT 30000
ON TABLE SET PAGE NOLEAD
ON TABLE SET STYLE *
GRID=OFF,$
ENDSTYLE
ENDPartial output is shown in the following image.