Distance Measures
The joining or tree clustering method uses the dissimilarities or distances between objects when forming the clusters. These distances can be based on a single dimension or multiple dimensions. For example, if we were to cluster fast foods, we could take into account the number of calories they contain, their price, subjective ratings of taste, etc. The most straightforward way of computing distances between objects in a multi-dimensional space is to compute Euclidean distances. If we had a two- or three-dimensional space this measure is the actual geometric distance between objects in the space (i.e., as if measured with a ruler). However, the joining algorithm does not "care" whether the distances that are "fed" to it are actual real distances, or some other derived measure of distance that is more meaningful to the researcher; and it is up to the researcher to select the right method for his/her specific application. The Cluster Analysis module will compute various types of distance measures, or the user can compute a matrix of distances him or herself and directly use it in the procedure.
Euclidean Distance:
This is probably the most commonly chosen type of distance. It simply is the geometric distance in the multidimensional space. It is computed as:
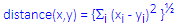
Note that Euclidean (and squared Euclidean) distances are computed from raw data, and not from standardized data. This is how it is usually computed and this method has certain advantages (for example, the distance between any two objects is not affected by the addition of new objects to the analysis, which may be outliers). However, the distances can be greatly affected by differences in scale among the dimensions from which the distances are computed. For example, if one of the dimensions denotes a measured length in centimeters, and you then convert it to millimeters (by multiplying the values by 10), the resulting Euclidean or squared Euclidean distances (computed from multiple dimensions) can be greatly affected, and consequently, the results of cluster analyses may be very different. Of course, you can implement any desired standardization or scaling using the data management features of STATISTICA.
Squared Euclidean Distance:
One may want to square the standard Euclidean distance in order to place progressively greater weight on objects that are further apart. This distance is computed as (
):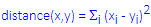 .
.
City-Block (Manhattan) Distance:
This distance is simply the sum of difference across dimensions. In most cases, this distance measure yields results similar to the simple Euclidean distance. However, note that in this measure, the effect of single large differences (outliers) is dampened (since they are not squared). The city-block distance is computed as:
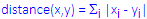
Chebychev distance:
This distance measure may be appropriate in cases when one wants to define two objects as "different" if they are different on any one of the dimensions. The Chebychev distance is computed as:
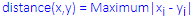
Power distance:This measure is particularly useful if the data for the dimensions included in the analysis are categorical in nature. This distance is computed as:
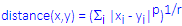
where r and p are user-defined parameters. A few example calculations may demonstrate how this measure "behaves." Parameter p controls the progressive weight that is placed on differences on individual dimensions, parameter r controls the progressive weight that is placed on larger differences between objects. If r and p are equal to 2, then this distance is equal to the Euclidean distance.
Percent disagreement:This measure is particularly useful if the data for the dimensions included in the analysis are categorical in nature. This distance is computed as:
For an overview of the other two methods of clustering, see Two-way Joining and K-means Clustering.