|
|
| Copyright © Cloud Software Group, Inc. All Rights Reserved |
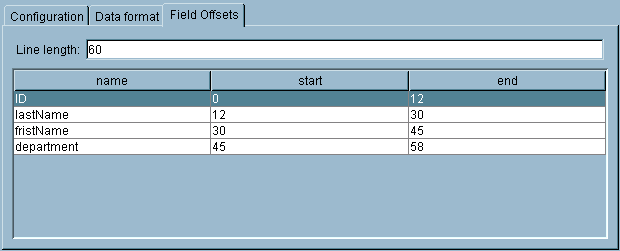
The Data Format resource contains the specification for parsing or rendering a text string using the Parse Data and Render Data activities. This shared configuration resource specifies the type of formatting for the text (delimited columns or fixed-width columns), the column separator for delimited columns, the line separator, and the fill character and field offsets for fixed-width columns. You must also specify the data schema to use for parsing or rendering the text.
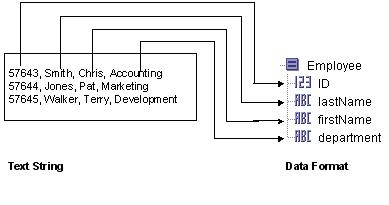
Figure 19 illustrates how an input text string is parsed into a specified data schema.Figure 19 Parsing a text string into a data schemaWhen rendering text, each record in the input data schema is transformed into a line of output text. The first item of the data schema is transformed into the first column of the text line, the second item is transformed into the second column, and so on. Each record in a repeating data schema is transformed into a separate line in the output text string. Rendering a data schema into a text string is exactly the opposite process of parsing a text string into a data schema. Rendering is the reverse of the process illustrated in Figure 19.
|
|
| Copyright © Cloud Software Group, Inc. All Rights Reserved |