|
|
| Copyright © Cloud Software Group, Inc. All Rights Reserved |
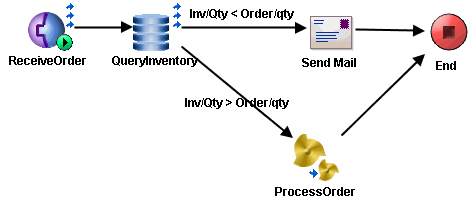
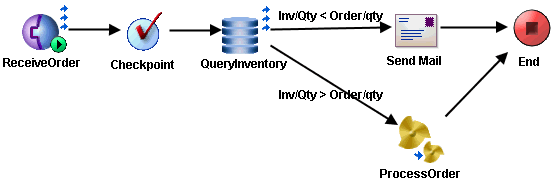
Duplicate messages should be detected and discarded to avoid processing the same event more than once. Duplicate detection is performed when a process instance executes its first Checkpoint activity. You must specify a value for the duplicateKey element in the Checkpoint activity input schema. This value should be some unique key contained in the event data that starts the process. For example, the orderID value is unique for all new orders.
|
|
| Copyright © Cloud Software Group, Inc. All Rights Reserved |