Troubleshooting
High CPU Usage in NoSQL Container
It has been observed that nodes where NoSQL container run are showing high CPU usage on some Linux platforms, despite limited use of Cassandra inside NoSQL per container. Although there are various known reasons of high CPU usage by Cassandra, one possible general cause of high CPU usage on Linux platform is Transparent Hugepages. Many Linux distributions come with Transparent Hugepages enabled by default. When Linux uses Transparent Hugepages, the kernel tries to allocate memory in large chunks (usually 2 MB), rather than 4K. However, some applications such as Cassandra, still allocate memory based on 4K pages. This can cause noticeable performance problems when Linux tries to defrag 2 MB pages.
To confirm this behavior and to reduce the CPU usage, follow the steps below. If the reason is confirmed as described below, you should stop the TIBCO Cloud™ API Management - Local Edition cluster, if possible, as it requires restarting the nodes.
- SSH in the node.
cat /sys/kernel/mm/transparent_hugepage/enabled
You should get the following output:[always] madvise never
- If you see this output, open the file
/etc/rc.local for editing. It will have only one statement (exit 0):
sudo vi /etc/rc.local
- Add the following lines before the last statement (exit 0):
if test -f /sys/kernel/mm/transparent_hugepage/enabled; then echo never > /sys/kernel/mm/transparent_hugepage/enabled fi if test -f /sys/kernel/mm/transparent_hugepage/defrag; then echo never > /sys/kernel/mm/transparent_hugepage/defrag fi
The file should have the following content after the modification.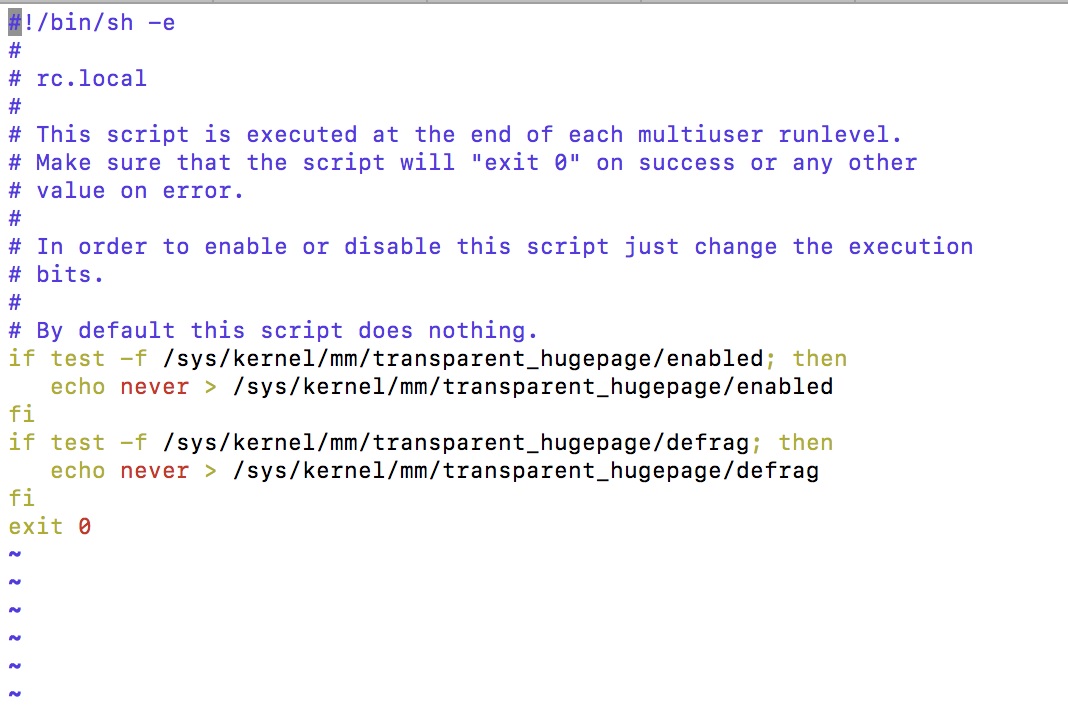
- Save and exit.
- Restart the node. Please perform steps 1-5 on all the nodes.
- After successful restart, SSH into the node and run the command from step 1.
You should get the following output:
[always] madvise never
- Once all nodes are restarted, you can redeploy the API Management - Local Edition cluster.
TML-installer Image Build Failure
If you encounter the following error message while building a new TM image through the tml-installer/jenkins in Local Edition:
Cannot retrieve metalink for repository: epel/x86_64. Please verify its path and try again [0m"yum_install initscripts.x86_64" command filed with exit code 1. The command '/bin/sh -c /home/builder/docker-build/tm-install.sh' returned a non-zero code: 1
If issues for creating images still exist, check with your network team for any firewall rules that need to be less restrictive.