Creating Input Map
You can create input maps within or across repositories.
- Procedure
- In the
Project Explorer window under
Repository Models, right-click a repository on which you want to define the input map and select
.
 The Input Map wizard is displayed.
The Input Map wizard is displayed. - In the
Input Map wizard fields, enter the relevant details.
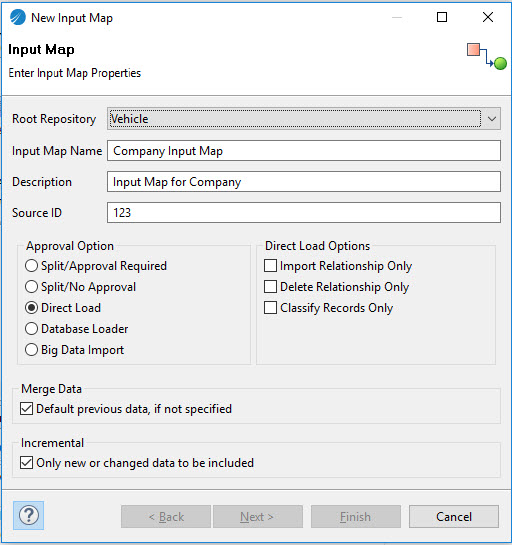
The following table lists the fields and their description: Field Description Root Repository The name of the repository for which you want to create the input map is displayed. Input Map Name Enter the Input Map name. The Name is unique and case insensitive for a input map. The name can contain A-Z, 0-9 and _. Description The description for the Input Map. Source ID Specify a Source ID. The source ID allows you to associate the data with an external system. The source ID can used in workflow and business process rules to customize business processes. Approval Option Select one of the following approval options: - Split/Approval Required: When you select this option, the records are split into batches before processing, but the system waits for an approval before confirming changes for each record bundle. Conflicts, if any, must be resolved for each record bundle separately.
- Split/No Approval: If you select this option, the records are split into batches before processing, but the system continues to process the record bundles without waiting for a confirmation. Conflicts, if any, must be resolved for each record bundle separately. The bundle is saved as a confirmed record, without initiating any approval workflows.
- Direct Load: If you select this option, all records are processed in one go in multiple bundles and no events are created for each bundle. Changes are confirmed without approval. In case of conflicts, imported data take precedence and the conflict must be resolved separately.
- Database Loader: If you select this option, the records are uploaded using the Database Loader.
- Big Data Import: If you select this option, all records are processed in the Apache Spark cluster without any workflow.
Big data import feature has a few limitations. For information, see ibi MDM User's Guide.
Important:- To use the Big Data Import option, you must have installed and configured Apache Spark and Apache Hadoop File Distributed System. For configuration, see ibi MDM Installation and Configuration Guide.
- To use the big data import feature through ibi MDM UI, see ibi MDM User's Guide.
Merge Data Select the Merge Data check box. When checked, it indicates that any previous child relationships must be retained. By default, Merge Data check box is selected on New Input Map wizard. Incremental Select the Incremental check box if you want to include only new data or make changes to the existing data. By default, Incremental check box is selected on New Input Map wizard. Direct Load Options If you select Direct Load Approval option then Direct Load Options is displayed. - Import Relationships Only: If you select this check box, relationships are created for existing records.
- Delete Relationships Only: If you select this check box, relationships between records are deleted for existing records.
- Classify Records Only: If you select this check box, classification records are created for existing records.
Fresh Data/ Mode If you select Database Loader Approval option then Freshdata and Mode option is displayed. - Freshdata: If you select this option, it indicates data is clean and initial version records need to be imported.
- Mode: If you select this option, it displays Load Records and Load Relationships in the drop-down list. Select Load Records to load record data with relationship. Similarly select Load Relationships to load relationship between existing records.
- Click
Next.
The Datasource Selection wizard is displayed.
- in the
Select Data Source section, select a data source by selecting the check box next to it.
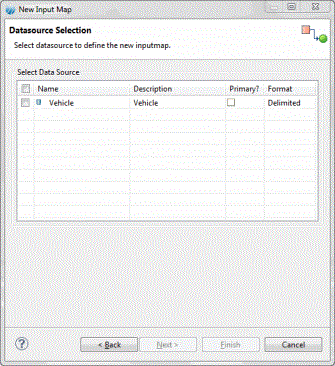
- In the Primary column, select the check box if you want to define the data source as primary data source.
- Click
Next.
The Select Relationships wizard is displayed.
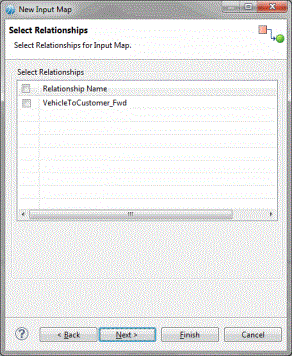
- If you want to define cross-repository or self-relationship (related input map), select the check box corresponding to the relationship name.
- Click
Next.
The Select Classifications wizard is displayed.
- If you want to include classification scheme, select the check box corresponding to the classification scheme.
Note: You can select the Classification Scheme for only for Manual extraction type.
- Click
Finish.
The Input map is created and displayed in the Input Map editor.
If the input map is created by selecting relationships, the related input maps are created under the related repositories. Similarly, if the input map is created by selecting classification scheme, the category specific attributes are displayed in the Input Map editor.