Usecase 1: Using File as the Input Type for Parse Data Activity
Use Case 1: A customer in the banking domain observed that the time taken to parse records was increasing with every record.
Testing and Measurement
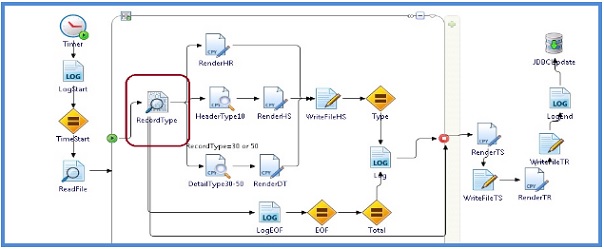
The project is designed to parse data in an iterative manner from a file in the text format. This data is converted into a schema which is then evaluated against certain conditions, by the transitions. Based on specific values, the data is rendered in a particular format using the data conversion ActiveMatrix BusinessWorks plugin. This parsed data is written to files and then eventually updated to the database.
Initial analysis showed that the overall high latency was due to the Parse Data activity highlighted in the above image.
Further analysis revealed that the time taken to parse the records was high since the input type of the Parse Data activity was configured to string, as displayed in the image below. When the input type is set to string, the entire contents of the source are read. For accessing specific records the search operation is performed in such a way that the entire source file is scanned.
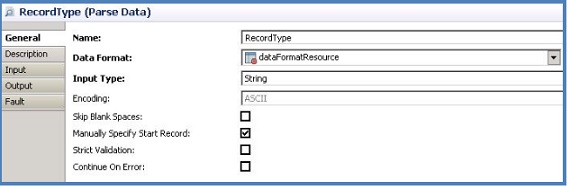
The other option to configure the input type is file. When the input type is file the data is read from the source by means of a pointer. While accessing a specific range of records the search is performed based on the position of the pointer which makes the operation faster.
The testing was focused on the aspects listed below:
- Comparative tests were conducted with input type for the Parse Data activity configured to string and file. The tests were performed to parse records in multiple iterations.
- The latency, memory and CPU utilization was measured.
- The overall latency was reduced by almost 10 times when the input type for the Parse Data activity was set to file.
- It is recommended that for faster processing, use the input type as file.
- In case of both the options, the input for Parse Data activity is placed in a process variable and this consumes memory. Hence large memory will be required to read large number of records. To reduce memory usage, it is recommended that a small set of records are read, parsed and processed before moving on to the next set of records.