Dedup Factors
The dedup results vary depending on your dedup configuration.
The following dedup factors are available to check duplicates:
| Factor | Description |
|---|---|
| Weight | Column weights are floating point values from
0.0 to
1.0.
When checking duplicates against a project or an external table that contains multiple columns, set a weight for each column to indicate the importance of the column. A weight closer to 1 indicates that the column is more important. For example, suppose a project contains catalogue data of an online bookseller and its data table contains three columns, Author, Book Title, and Book Description. If content matched in the first two columns is more significant than content matched in the third column, then retain the default weight of 1.0 for the first two columns, and assign a lower weight such as 0.8 to the Book Description column. The column weight is used to calculate a final score. The final score is calculated according to the weight and the querylet score of each column. Suppose there are two columns, the final score is calculated as follows: (weight1 * querylet1 + weight2* querylet2)/2. |
| Ignore empty | When you select this check box, an empty value is considered to be a duplicate of any specified values. In this case, the
querylet score for this column is ignored when calculating the final score.
For example, suppose there is an empty value in the LastName column and the Ignore empty check box is selected for this column, as shown in the following figure, the first row and the second row is considered duplicates, and the final score is calculated using the FirstName column. 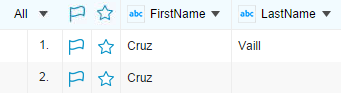
|
| Reject score | A value of
1 indicates when cell values match exactly, the rows can be considered as duplicates. Reject score is used to refine your dedup process. If the
querylet score is less than the reject score set for this column, the detected rows are not in the same duplicated group, even if the final score is greater than the score threshold.
For example, suppose there are two columns: SSN and FirstName. If the values in the FirstName are the same, and the values in the SSN column are very similar, the TIBCO Patterns considers these two data rows as duplicates. However, if you set the Reject score of the SSN column to 1, only if the SSN values match exactly, the data can be considered as a duplicate. When you set the Reject score of the SSN column to 1, the first row and the second row in the following figure are not considered as duplicates. 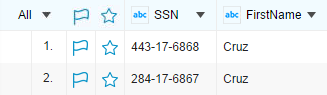
|
| Thesaurus names | A thesaurus table specifies sets of terms (words or phrases) that match the algorithm detects and are considered as equivalent.
Suppose there is a thesaurus table that specifies a set of countries. When checking duplicates against a Country column, a thesaurus table is defined for the Country column, then the cell values, US, America, and United States of America are considered as match exactly. That is, the dedup_score of these cell values is 1. For details about how to create a thesaurus table, see Managing Thesaurus Tables. |