Matching
Introduction
The EBX® Match and Merge Add-on finds records that might be duplicates. You can run it manually and configure it to run automatically during certain operations. You can search within a table and configure it to search related tables. The results include a score that indicates how closely records match. You can resolve matches, or configure the add-on to automatically handle conflicts in different ways based on the score.
Matching configuration
This section describes how to configure add-on functions.
Matching configuration overview
Before using matching, configuration is needed to define:
The tables that are governed by the add-on.
The operations for which matching is used (create, update).
The algorithms used to perform the search for duplicate records (phonetic, distance)
Note
You can test new or existing configuration settings to ensure they returns the desired results. See Testing a matching policy for more information.
Configuration can be managed by staff that are in a 'Matching Steward' role. During day-to-day data modification, this configuration should not be modified by other staff such as those with 'Data Steward' roles.
The four main levels of matching configuration that require management include: Table configuration, Process policy, Matching policy and Survivorship policy.
A partial view of the logical data model for matching configuration is presented in EBX® Match and Merge Add-on data model section. In this user guide, both the business and logical names of each table are highlighted so that it is easy to refer to the logical data model if needed.
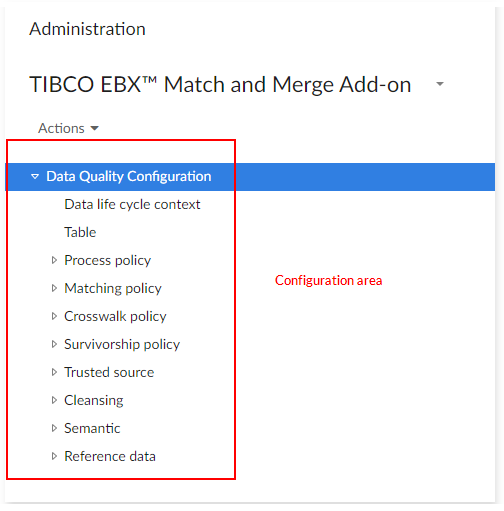
The TIBCO EBX® Match and Merge Add-on dataset located under the EBX® 'Administration' tab is used to configure matching policies, cleansing policies and crosswalk policies.
The 'Matching reference data' dataset (also located under the EBX® 'Administration' tab) contains reference data used by the add-on. The 'Matching state machine configuration' dataset must not be modified.
Special notation: | |
|---|---|
| If the matching configuration is not correct at execution time, then any creation or modification of records is set to unmatched. Even though matching configuration quality and integrity are checked when configuring the add-on, it is still possible that some matching use cases are not covered by the configuration. For example, a business context could be raised but not yet be declared in the current matching configuration. |
Concepts
EBX® Match and Merge Add-on configuration relies on these key concepts: table declaration, process policy, matching policy and survivorship policy.
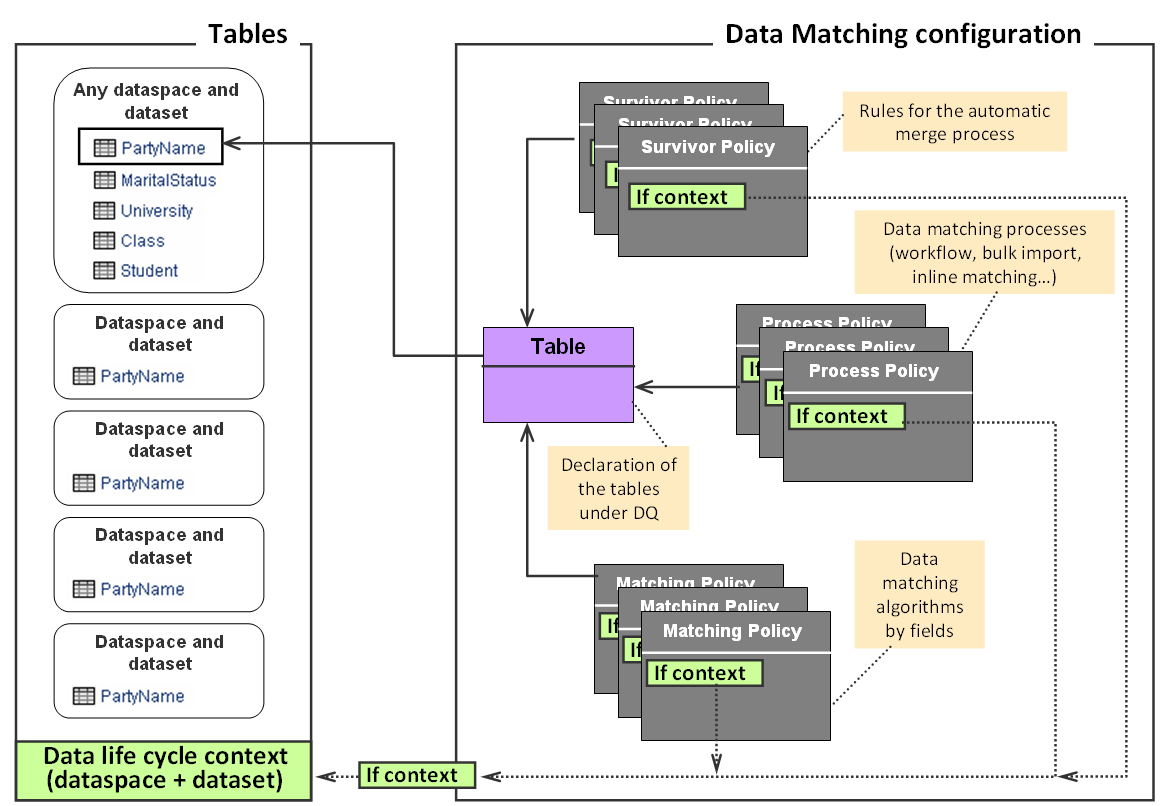
In the above illustration, the 'Table' declares which tables are under the add-on control. The list of existing tables is obtained by configuring a data model containing the targeted tables. In the figure, the 'PartyName' table is set under add-on control. The localization of this table can evolve to other dataspaces and datasets over time. It will not change this declaration. A table requires a unique declaration regardless of its localization in many dataspaces and datasets.
A process policy defines a add-on process strategy such as: use of the workflow, import mode, inline matching, etc. Multiple strategies can be configured for one table. It is possible to change the strategy by data life cycle contexts based on a dataspace and dataset.
A matching policy defines the add-on algorithms to apply on the fields involved in the matching score computation. Several matching policies can be defined by datasets and dataspace, by business contexts (values of fields in the record to match) and by workflow.
A survivorship policy defines the rules to apply when executing the automatic merge of suspect records into golden or pivot records. They can be contextualized by dataspace and dataset.
Creating a test configuration
Once the add-on metadata is included to your table (refer to Installation and first configuration section), you can create a simple configuration that helps you determine how well the add-on works in your environment.
After testing this initial configuration, you can create another to import your data or initialize an existing set of records (refer to Installation and first configuration section). Then you will be ready to create your own portfolio of matching policies.
This table highlights setting your first test configuration.
Table | Field to configure at minimum |
|---|---|
Table | Select the data model and then the table. Select the your data language. Other properties do not need to be used or modified for this minimum configuration. |
Process policy | Select your table. Other properties do not need to be used or modified for this minimum configuration. Your process policy is set up by default to run in a direct matching mode without a workflow. |
Matching policy | Select your table. Set the 'Active' property to 'Yes'. Select the Main matching algorithm. Other properties are not used or modified. |
Matching field | Select your matching policy and submit. Select the field you want to use to match your data. Other properties are not used or modified. |
Table 1: A first quick and easy configuration
The Data life cycle context, Matching policy context, Survivorship policy, Survivor field, Source, Table trusted source, Field trusted source tables are not required for your initial test configuration.
Checking the configurations
You can use the 'Check add-on configuration' operation to determine whether a table's configuration is valid. The operation can raise errors.
Checking matching configuration is available on demand. It does not prevent the add-on from executing.
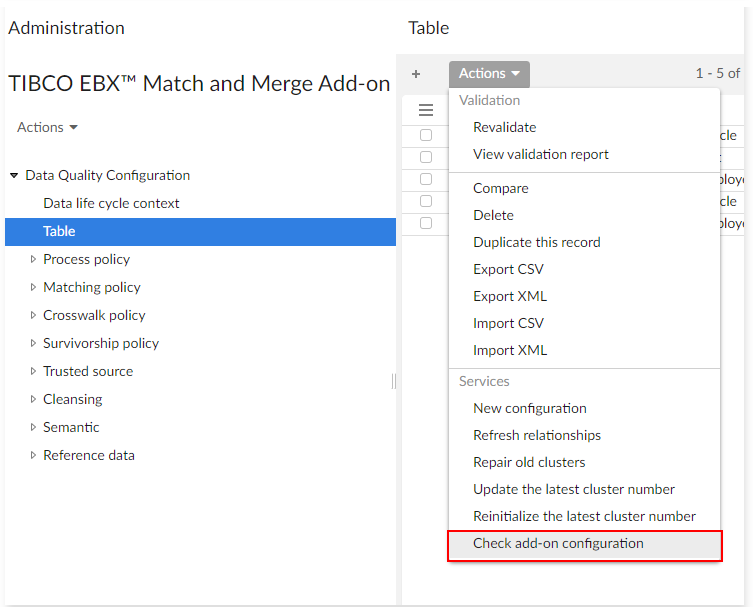
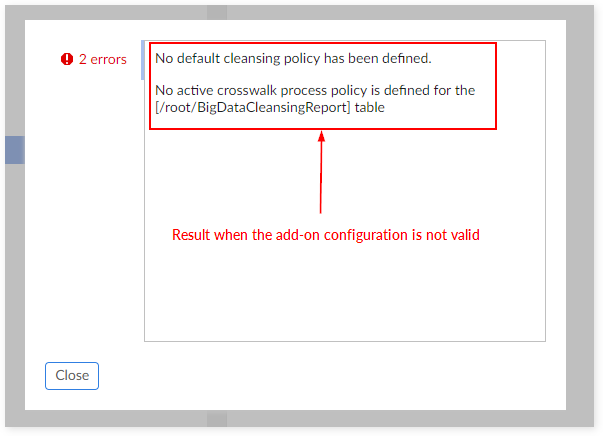
At execution time, if any errors exist, then user messages are raised and the default policy is applied: records are set to unmatched for any creation and modification.
Special notation | |
|---|---|
| Checking of Matching policies executes if the 'Use matching' ('Table' configuration) property is set to 'Yes'. Checking of Cleansing policies executes if the 'Use cleansing' property is set to 'Yes'. |
Table configuration
Use this table to register your tables with the add-on and enable desired features, such as cleansing and crosswalk.
To register a table with the add-on:
Code: Use any naming convention to enter a code. The add-on uses this code to uniquely identify this configuration.
Data model: Select the data model containing the table you want to register.
Table: Select the table you want to register with the add-on.
Once you save the configuration, other properties display to enable or disable add-on features (Matching, Cleansing, Crosswalk, language, etc.). Please note that these properties only display when the registered table includes DaqaMetaData.
Table table (logical name: TableConfiguration)
Properties | Definition |
|---|---|
Code | Any naming convention without white spaces. |
Data model | The data model that contains the table to set under the add-on configuration. |
Table | Name of table managed by the add-on. When the table has not been extended with the matching metadata type, then only the cleansing and crosswalk features are available. |
Business ID | One or more fields used as the business identifier. This identifier is used by the matching policy relying on a literal score = Exact in order to group suspect records that have identical business identifiers (no fuzzy search, see example in Matching policy with exact score section). |
Source field | Field in the table that is used for getting the record source. This parameter is optional and is used when the record selection policy is 'most trusted source'. A multi-valued field cannot be selected as a source field. To use such a field you need to create a new field with a function that aggregates the values into the accepted format. Then, this field can be used as a source field. |
Field to exclude records from match | Field in the table that is used for excluding records when the match operation is executed. This parameter is optional and is used when the matching policy 'Exclude records from matching' property is not null. |
Language | Language used by the matching procedure. The language is selected from 'ebx.locales', that is, the languages managed by EBX®. For international languages, meaning many languages, English must be selected. |
Max number of records in cluster | The maximum number of records that can be matched with the pivot in a cluster when matching is executed. Note that this number does not include the record being matched. For example, if you specify a value of 7, there can be 8 records in the cluster. Set to undefined when the maximum number of records in a cluster is unbounded. Please, note that:
|
Max number of records for group | The maximum number of records that can be matched with a random record (considered as pivot) in a cluster used by the 'Group at once (unmatched)' and 'Group at once (to be matched)' operations to group records (not including a random record selected by the add-on to). Set to undefined when the maximum number of records in a group is unbounded. |
Latest cluster number | The cluster register begins at 11 and is incremented by one to an unbounded level. Every table holds its own cluster register. The 'Latest cluster number' value is used by the add-on to keep in memory the last cluster identifier created for a table. All the datasets that come from the same data model share the same 'Latest cluster number'. |
Disable matching trigger | It is possible to deactivate the matching trigger used by the add-on. This trigger allows you to put the table under add-on control. It is embedded in the data type that contains the matching metadata. The de-activation of the matching trigger is used when it is needed to implement the invocation to the matching in a bespoke trigger (via the add-on's API) that lives together with other add-ons such as the TIBCO EBX® Insight Add-on or any other software invocation at the CRUD time. If the matching trigger is inactive and the add-on's API not implemented then the table is no longer under the control of the add-on. Every new record will get an undefined state value that will be possible to set up later with the 'Set at once' operation. If 'Yes': The matching trigger is inactive. If 'No': The matching trigger is active. Default value: 'No' |
Event listener | Java implementation listening to matching events. |
Use matching | If 'Yes': The matching feature is enabled for the selected table. If 'No': The matching feature is not enabled. The matching feature finds duplicate records and makes creation of a golden record possible. When 'Use matching' is set to 'No', created and updated records are set to the Unmatched state in the '000' cluster. Records with Merged/Deleted states cannot be modified. Records that have 'Unmatched' or 'To be matched' states can be modified; however, their state won't change. |
Use cleansing | If 'Yes': The cleansing feature is enabled for the selected table. If 'No': The cleansing feature is not enabled. The cleansing feature assesses table data quality and fixes defects, such as missing field values. |
Use crosswalk | If 'Yes': The crosswalk feature is enabled for the selected table. If 'No': The crosswalk feature is not enabled. The crosswalk feature creates cross-reference records by performing a matching process. |
Activate Monitoring | If 'Yes': The TIBCO EBX® Activity Monitoring Add-on stores execution status. If 'No': The EBX® Activity Monitoring Add-on does not store execution status. Default value: 'No' Determines whether the TIBCO EBX® Activity Monitoring Add-on stores execution status. This setting applies to 'Match at once', 'Run match', and 'Exact match' operations. |
Number of processed records to update status | Specifies the number of records the add-on must process before triggering a status update in the TIBCO EBX® Activity Monitoring Add-on. This value must be between 500 and 2000. By default, the execution status is updated in the TIBCO EBX® Activity Monitoring Add-on every time 1000 records are processed. |
Table 2: Table configuration properties
Process policy
A process policy defines a set of parameters that the add-on uses to execute matching. Multiple process policies can be defined and attached to a table controlled by the add-on. Two important concepts must be understood to configure a process policy: 'double matching' and 'user interaction & workflow'.
Double matching configuration
Every matching policy can be configured with two matching algorithms. The second algorithm is optional. It is used to deal with 'false negative' records that the first algorithm could ignore by error. A 'false negative' record is a record that should have been identified as a suspect record by the matching procedure, but was not. The second algorithm is executed if the score of the first algorithm is between 0% and the value specified by the 'Threshold second algorithm' property. All suspects that are detected by the second matching algorithm are set with a score of 'Stewardship min score' + '0.1' to put them in the right area defined for the first algorithm. Above the stewardship area an automatic record merge-based on survivorship rules-is applied. The second algorithm is not able to run an automatic merge and the score of every suspect is set to 'Stewardship min score' + '0.1'.
User and workflow interaction
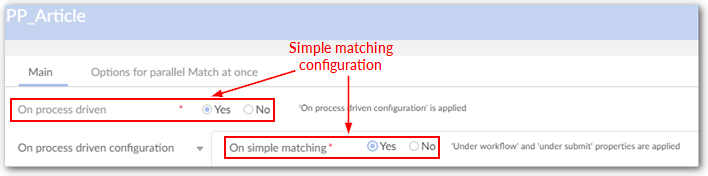
The add-on can be configured to launch automatic workflows when a duplicate record is identified. A portfolio of workflow user tasks and scripts is provided to facilitate the design of any bespoke workflows (see Workflow integration section). When the add-on is configured with no automatic workflows, it still remains possible to launch global EBX® workflows outside the scope of the add-on. These workflows can use all user tasks and scripts provided with the add-on. Two modes of matching can be configured: 'Direct matching' to compute suspect records directly (not requiring user input), or 'Simple matching' with the 'Suspicious' state management (requires user input). See Record level matching section for more information. For the 'Simple matching' mode, it is possible to configure the add-on with the 'embedded at submit' property to directly display the duplicate records at submit time without workflow execution. The possible configurations to drive the user interactions and the workflow interaction are highlighted in the figure below.
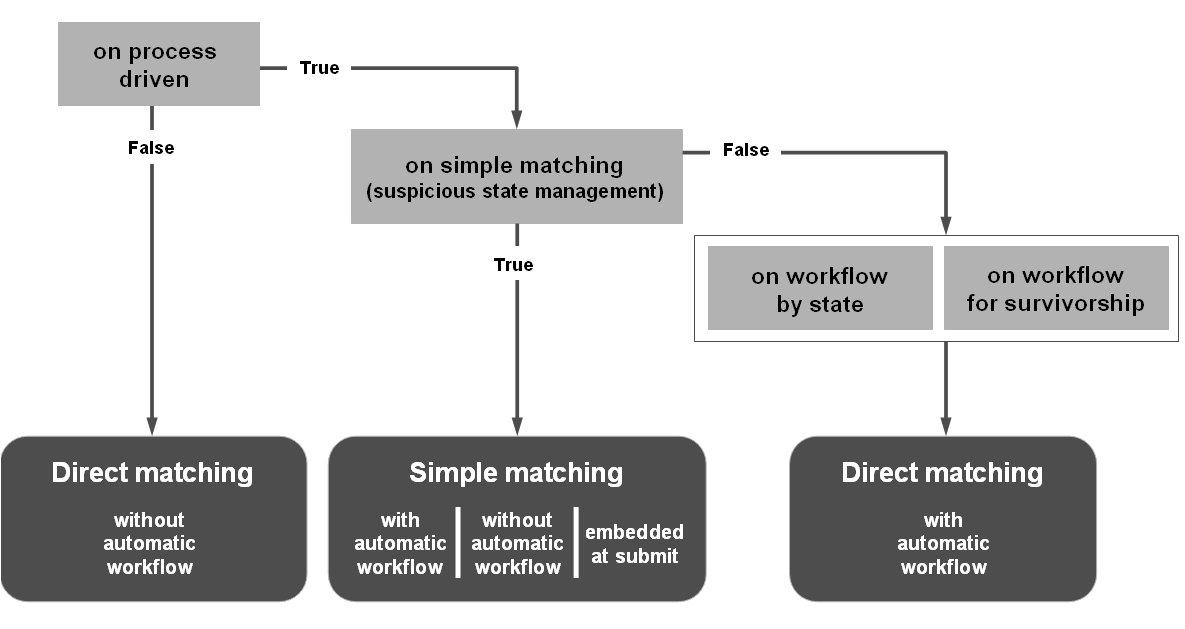
Here are some common configurations:
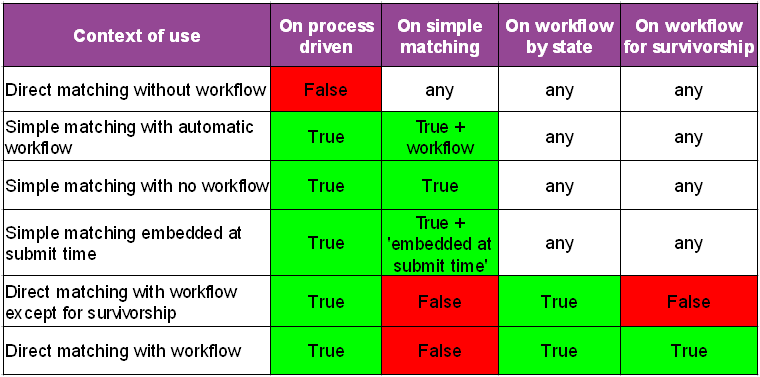
Table 3: Usual process policy configurations
Note
When creating a workflow, the Auto complete property must be set to false if you want to use the merge process output for the next step.
If the 'On process driven' policy is set to 'Yes' and something is not correct in the workflow configuration, either at the 'Simple matching' level or the 'Workflow by state' level, then the 'Direct matching and no workflow' configuration is used by default.
In addition to these configurations, it is possible to deactivate matching either on creation or modification of any record (see Processes applied to the creation and modification of records section). It is also possible to deactivate survivorship execution (automatic merge).
The services applied to a set of records, such as 'Match at once', do not create workflows no matter what configuration is used.
Description | Application | Example |
|---|---|---|
Direct matching without workflow | ||
Any creation or modification of a record entails a matching execution against the table. The states of the impacted records are immediately updated. The workflow is not used. | Suitable when cleansing an existing table, importing bulk data and mass data entry. This method is useful when a company does not need workflows or prefers to manage workflows outside of add-on control (*). (*) All components of the matching UI (light and full views) can be easily integrated in any workflow, with a data context providing a record or cluster identifier. | Creation of a record that moves to the pivot state in a cluster that contains suspect records. Creation of a record that becomes a golden record in the '001' reserved cluster. |
Simple matching (human decision required when suspect records are detected) | ||
Any creation or modification of a record executes a search for matching records. This search does not entail modification of the impacted record's states that are identified by the add-on. These records are presented to the user who decides to keep the new/updated record as a golden record, to cancel the new/updated record or to manage a merge procedure applied to the matching records. When there are no matching records, then the new/updated record is automatically considered a golden record. A workflow for creation and modification can be configured. | Suitable in real-time data entry when creation or modification of a record must be matched against the table to determine whether or not it is a suspicious record. Based on a human decision applied on the suspicious record, either the new/updated record is canceled or confirmed as a golden or a pivot record. Note: it is possible to create any bespoke workflow with a first step for record creation and modification. Then, the second step is the simple matching view. In this case the workflow properties must be set to none. | Creation of a record that is flagged as a suspicious record. Then a workflow is launched to display all potential suspect records. The user decides how this suspicious record must be managed: golden record directly, cancel, merge with other potential suspect records. |
Direct matching with workflow | ||
The creation or modification of a record executes matching on the table. The states of the impacted records are directly updated. Depending on the state of the new/updated record a workflow can be configured. The add-on executes this workflow automatically. | Suitable in the same use case as 'Direct matching without workflow'. | Automatic creation of a workflow when a record moves to the pivot state. |
Table 4: On process driven configuration
Processes applied to the creation and modification of records
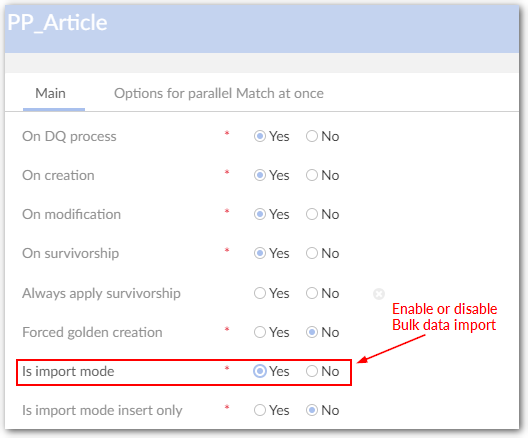
The configuration of a process policy allows you to define different options applied to the creation and modification of records. The properties used are as follows: 'On matching process', 'On creation', 'On modification', 'Forced golden creation', 'Is import mode', 'Is import mode only' and 'On simple matching'.
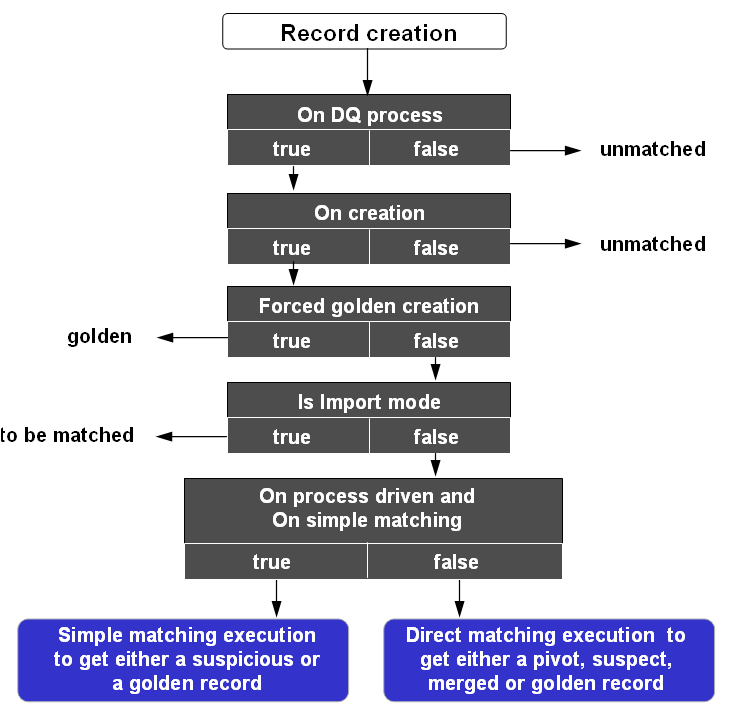
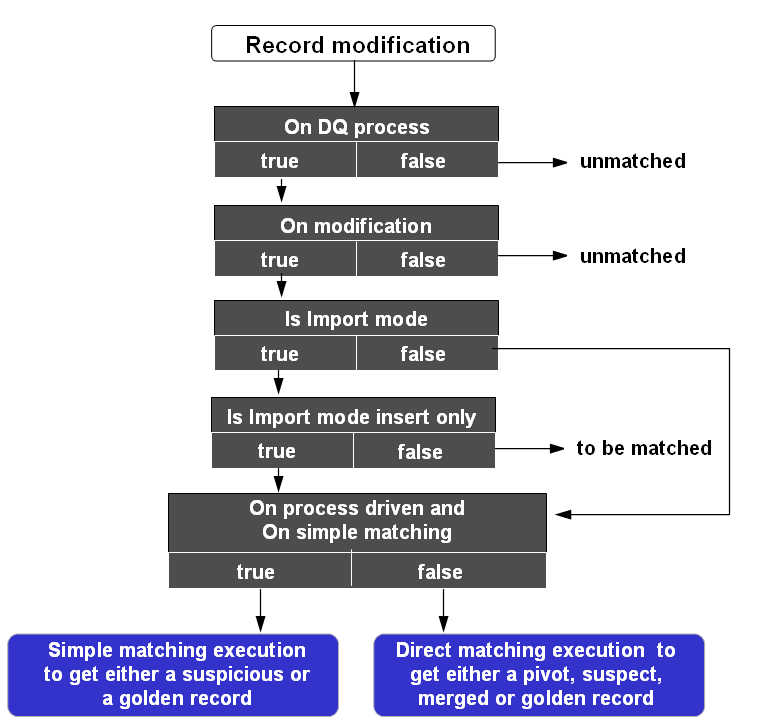
The following, shows common use contexts and their corresponding configurations:
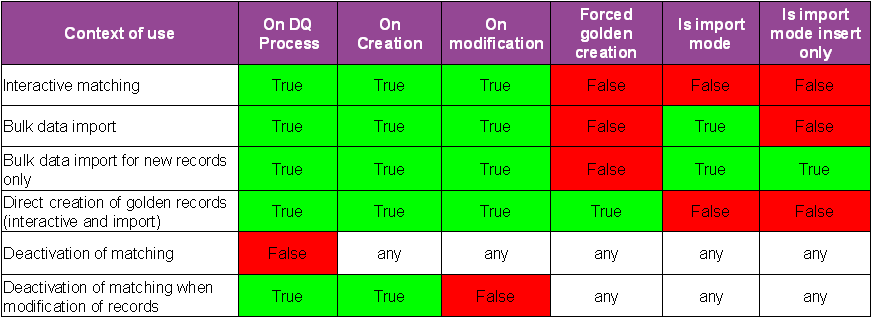
Table 5: Example of processes applied to the creation and modification of records
Process policy configuration
A table's configuration must declare one active process policy with no context. When several process policies are active at the same time for different contexts, then the policy with no context is used by default for every execution that is not related to a defined context.
Process policy table (logical name: ProcessPolicy)
Properties | Definition |
|---|---|
Code | Any naming convention without white spaces can be used. |
Short description | The policy description. |
Long description | Long description of the policy |
Table | Link to the table used for this policy. |
Active | If 'Yes': This process policy is used. If 'No': This process policy is not used. This field indicates whether or not the policy is used when running matches. Since the add-on manages the process policy context, one or more process policies can be active at the same time for a given table. To disable a process policy, set the active field to 'No'. Only one process policy can be active for each context and a table. One active process policy with no context must be configured. It is used by default process policy at execution time. Default value: 'Yes' |
Data life cycle context | A process policy can be defined for a specific dataspace and/or dataset. This property is a link to a data life cycle context (dataspace and/or dataset). Leave the value undefined to deactivate the use of a context (any dataspace and dataset). The priority of contexts is as follows:
In this example, the process policy P003 has the highest priority, then process policy P002 and P001. |
On matching process (See use case in this user guide to understand the way of the add-on works depending on this parameter.) | If 'Yes': The table benefits from matching in the context defined by the 'Data life cycle context' property (any data space and data set if 'Data life cycle context' is undefined). If 'No': Matching is inactive for the table in the context. The states of created records and modified records without a state are still systematically set to 'Unmatched'. Default value: 'Yes' |
On creation | If True: Matching is run at record creation. If No: Matching is not run at record creation. The state of created records is systematically set to unmatched. Default value: 'Yes'. |
Search before create | When you enable Search before create, users can search existing records to avoid creating a potential duplicate. |
On modification | If 'Yes': Matching is run at record modification. For Simple matching process (creation of suspicious records), the matching is run when matching fields are modified only. For all other cases, the matching is run when the record is modified whatever the fields. If 'No': Matching is not run at record modification. If a modified record's state was not set, it will be set to Unmatched. Default value: 'Yes'. |
On survivorship | If 'Yes': The add-on merges records automatically when the match score is above the threshold set in the 'Stewardship max score' property. Note that any existing Merged records will be taken into account when performing the merge operation. If 'No': Survivorship is disabled. Default value: 'Yes' |
Always apply survivorship | If 'Yes': The add-on merges records automatically when the match score is above the threshold set in the 'Stewardship min score' property. It means that every cluster created will be merged automatically. If 'No': The add-on merges records automatically when the match score is above the threshold set in the 'Stewardship max score' property. Default value: 'No' |
Forced golden creation | If 'Yes': Record creation is set to a golden state in the '001' cluster without any matching execution. This property has no impact on procedures applied on modification and deletion of records. This property makes the 'Is import mode' property inactive. When the 'Forced golden creation' property is set to 'Yes' then the workflow is deactivated. If 'No': Forced creation of golden records is deactivated. Default value: 'No' |
Is import mode | If 'Yes': The policy is used in the context of bulk data import. On creation and/or modification record states are set to 'to be matched' (refer to the next property 'Is import mode insert only'). If 'No': The policy is used in the context of interactive creation and modification of records. When the 'Is import mode' property is set to 'Yes' then the workflow is deactivated . Default value: 'No' |
Is import mode insert only | This property is used only if 'Is import mode'='Yes' If 'Yes': Only new records move to 'to be matched'. If 'No': Updated and new records move to 'to be matched' Default value: 'No' |
Merged record is recycled | If 'Yes': Modification of merged records is enabled. When a merged record is modified behavior depends on property settings as follows:
If 'No': Modification of merged records is disabled. This option is disabled when 'Is import mode' is set to 'Yes'. Default value: 'No'. |
Stewardship min score (%) | When a match score is lower than this threshold then the add-on does not consider the record as a suspect record. |
Stewardship max score (%) | When a match score is higher than this threshold, the add-on enforces an automatic merge of this record into the corresponding pivot or golden record. This procedure is also known as 'survivorship'. It is important to select this value carefully. If it is set too low, records may be automatically merged with pivot and golden records that are not actually related. When scores fall between the 'Stewardship min score' and the 'Stewardship max score' values, human interaction is needed to decide how to manage the suspect record (stewardship process). |
Threshold second matching(%) | When the score computed by the first algorithm is between 0% and the value specified by the 'Threshold second matching(%)' property, then the second algorithm is applied to detect potential false negative records. For example, if 'Threshold second matching' is set to '5%' then the second algorithm is executed each time the score of the first algorithm is lower than '5%'. Constraint: 'Threshold second matching' is lower than or equal to 'Stewardship min score'. This property is used when 'Second matching algorithm' in the matching policy is not empty. Default value: '0' |
Second level stewardship min score (%) | When the second matching level is configured to find false negative records from a first level matching, then this threshold is used to evaluate the matching score and whether or not it provides a suspect record. This property is used when 'Second matching algorithm' in the matching policy is not empty. |
Not suspect with threshold (%) | When a record 'A' is 'Not suspect with' a record 'B', the score of 'B' against 'A' is kept by the add-on. When a new matching is executed, if the variance (new score - former score > 'Not suspect with threshold') then 'B' is no longer considered as 'Not suspect' and becomes a suspect of 'A'. For instance, 'Not suspect with threshold'=10% and score of 'B'=60% when it was stated 'Not suspect with'. If the new score of 'B' against 'A' is higher than or equal to 70% then it comes back as suspect otherwise it remains 'Not suspect with' the record 'A'. |
On not suspect with | Allow to deactivate the 'not suspect with' feature. Case 1: 'On not suspect with' = 'Yes' and new score - old score < 'Not suspect with threshold' (note: new score is the score of current matching, old score is the score of suspect record in the list of not suspect of pivot record):
Case 2: 'On not suspect with' = 'Yes' and new score - old score >= 'Not suspect with threshold':
Case 3: 'On not suspect with' = 'No' and new score - old score < 'Not suspect with threshold':
Case 4: 'On not suspect with' = 'No' and new score - old score >= 'Not suspect with threshold':
If 'Yes': When a match is executed the 'not suspect with' records participate in the matching only if the 'not suspect with threshold' is reached. If 'No': When a match is executed the 'not suspect with' records participate in the matching as regular records. Default value: 'No' |
Bidirectional not suspect with | If you enable this property and run the 'Not suspect with' service on a Suspect record, the add-on saves any 'Not suspect with' records in the Pivot and Suspect record's metadata tabs. |
On suspect record retention | If you set this property to 'Yes', when suspect records no longer match with their Pivot records, the score of the impacted cluster will be recalculated. A new pivot is selected based on the 'Pivot selection mode' property setting. Survivorship is not applied; only the score is recalculated. This strategy can be changed by setting the 'On suspect record retention' property to 'No'. With this configuration, the suspect records that no longer match with the pivot record will be moved to the unmatched state. Default value: 'Yes' |
Cluster retention on matching suspect | You can use this property when running a 'Match at once' in full mode, 'Match table' or 'Modify' operation on Suspect records. For the following examples, consider Suspect record A as the Pivot. The add-on matches A against all other records in the table. However, when running a 'Match at once in full mode' or 'Match table' operation, the match excludes records in A's cluster.
Default value: 'No' |
On process driven | If 'Yes': The configurations defined with 'On simple matching', 'On workflow by state' and 'On workflow for survivorship' are used. If 'No': Direct matching without workflow is executed. Default value: 'No' |
On simple matching | 'On simple matching'
'Under workflow'
'Under submit'
If a workflow is configured for creation (or modification) then the embedded property at creation time (or modification) is no longer possible. When no workflow and no embedded properties are configured then the add-on does not provide any information to the user when a suspicious record is raised. This is the responsibility of the application to manage (or not) a process to inform the user. The embedded mode is possible only through the regular EBX® view, not from the light and full matching views since they already provide a full inline integration. |
On workflow by state | To make this property active: 'On process driven'='Yes' and 'On simple matching'='No'. This property allows you to declare a workflow that the add-on will launch automatically depending on the matching result. For example, if [suspect, myWorkflowToManageSuspect] is configured, then this workflow will be created after the creation or modification of any record moving to the 'Suspect' state. An undefined value is used to deactivate this configuration. Default value: 'undefined' 1. State: This property allows you to declare the state that records become after a matching operation. 2. Workflow name: Name of the workflow launched when a record moves to the state defined by the 'State' property after a matching operation. When the add-on launches a workflow due to record creation or modification, the following variables must be declared in the data context. - branch: Reference of the data space. - instance: Reference of the data set. - tablePath: Path of the table. - xpath: XPath of the record. - workflowIdentifier: Unique identifier to track the record. |
On workflow for survivorship | To make this property active: 'on process driven'='Yes' and 'On simple matching'='No'. Name of the workflow launched by the add-on in case of survivorship (at least one automatic merge has been executed). An undefined value is used to deactivate this configuration. Default value: 'undefined' When the add-on launches a workflow due to record creation or modification, the following variables must be declared in the data context. - branch: Reference of the data space. - instance: Reference of the data set. - tablePath: Path of the table. - xpath: XPath of the record. - workflowIdentifier: Unique identifier to track the record. |
Options for Parallel Match at once: In the 'Match at once' screens, you can configure properties to divide records into groups and execute matching on these groups simultaneously. After matching completes, results are merged into the original data. If the number of groups is bigger than the number of threads, groups are evenly distributed in the different dataspaces/threads. This technical setting is equivalent to configuring the Filter by property in the Matching policy. It has no impact on the returned result, but improves the performance(memory and speed). | |
Filter by | The add-on uses the fields in 'Filter by' to group records containing the same value into a thread. When you add a filter occurrence, you select one or more fields within the table:
|
Number of threads | Specifies the number of threads executed in parallel. For each thread, the add-on creates a dedicated temporary dataspace inside the original dataspace on which the Match at once operations are executed. Default value: 4 |
Commit threshold | The add-on commits results of Match at once operations in temporary dataspaces to the original dataspace when the number of executed records reaches this threshold. This threshold must be tuned according to your database. Default value: 100000 |
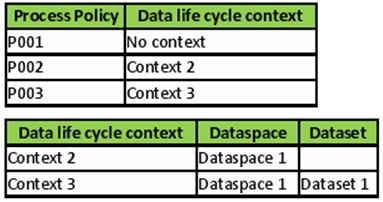
Table 6: Process policy properties
Examples - Process policy configurations
In these examples a table called 'Articles' is considered. You can configure your own table.
Direct matching without workflow

Simple matching
Set the 'On process driven' property and 'On simple matching' to 'Yes' to enable it.
Bulk data import
Bulk data import for new records only

Direct creation of golden records (interactive and import)

Deactivation of the matching
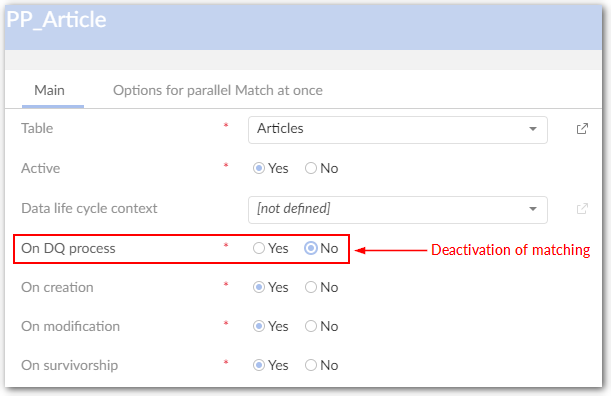
Deactivation of the matching when modification of records

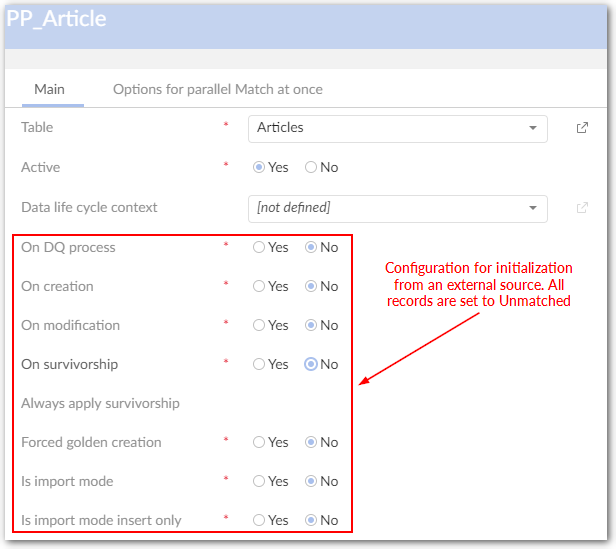
Initialization from an external source. All records are set to unmatched
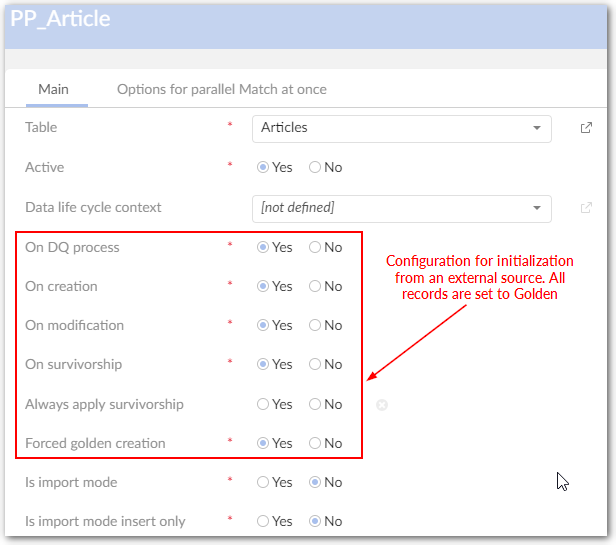
Initialization from an external source. All records are set to golden
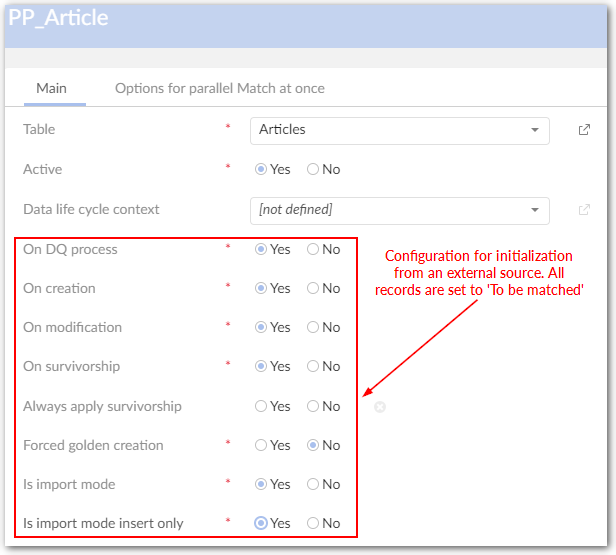
Initialization from an external source. All records are set 'to be matched'
User interface
In this section, you will find information on how to configure the user interface and detailed descriptions of all properties under the User interface tab. This tab allows you to regroup all user interface settings for a given table. They are organized by service available to the end user.
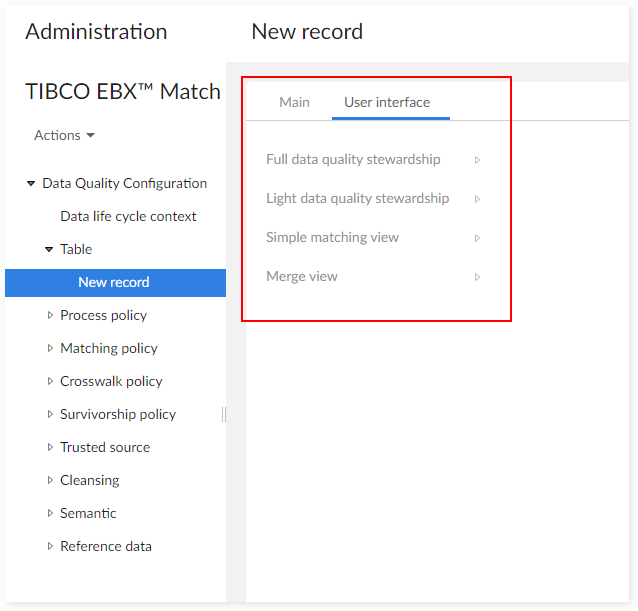
Properties | Definition |
|---|---|
Full data quality stewardship | |
Default view - top part | The add-on provides the matching view for the top part by default. You can customize it to fit your needs. To configure a custom view:
|
| Default view - bottom part | The add-on provides the matching view for the bottom part by default. You can customize it to fit your needs. To configure a custom view:
|
View by user profile | You can bind views to specific user profiles. This enables a user, or set of users to access specific matching views. To configure custom views for specific user profiles:
|
State(s) to filter from selection | You can hide any unwanted states from the State button on the top right corner of the matching view. |
Light data quality stewardship | |
Default view | The add-on provides the matching view by default. You can customize it to fit your needs. To configure a custom view:
|
View by user profile | You can bind views to specific user profiles. This enables a user, or set of users to access specific matching views. To configure custom views for specific user profiles:
|
State(s) to filter from selection | You can hide any unwanted states from the State button on the top right corner of the matching view. |
Simple matching view | |
Default view | The add-on provides the matching view by default. It can be changed for every table depending on the need. To configure a custom view:
|
View by user profile | You can bind views to specific user profiles. This enables a user, or set of users to access specific matching views. To configure custom views for specific user profiles:
|
Available actions | Determines availability of options in the simple matching view. |
Merge view | |
Default view | The add-on provides the merge view by default. It can be changed for every table depending on the need. To configure a custom view:
|
View by user profile | You can bind views to specific user profiles. This enables a user, or set of users to access specific merge views. To configure custom views for specific user profiles:
|
Apply EBX permission | Determines whether EBX® permissions apply. If a user does not have permission to view a field, it does not display. However, it is good to keep in mind that users in charge of merging must have access to all record fields. |
Allow the pivot to be modified | Determines whether users can change the Pivot record in the Merge view by selecting its primary key. |
Merge option | Defines the options available to merge records manually. The options are described below:
Default value: Set Golden |
Table 7: User interface
Matching policy
A matching policy is applied to a table and a matching context (optional) in order to declare how the add-on executes matching. For example, a matching policy can define which fields are used to compute the matching score and which algorithm is used.
To configure a matching policy:
Create a record in the 'Matching policy' table and specify a table and which algorithms you want to apply.
Create a record in the 'Matching field' table that determines which field the add-on uses during matching.
A matching context is required when the fields to match depend on the nature or type of records.
Below is an example with a table named 'Party', structured as follows:
Field | Definition |
|---|---|
Code | Any naming convention without white spaces |
Organization type | {Company, Individual} |
Nature | If Organization type = Company: {Domestic, Overseas} If Organization type = Individual: {Prospect, Customer, Employee} |
Name | |
Address | |
Country | For Overseas company only |
Social number | For Employee only |
Sales representative | For Customer only |
Table 8: Example: 'Party' table
For this table, depending on the values of Organization type and Nature, specific fields are used to drive the matching process. The matching policy contexts needed are as follows:
Matching policy context | Matching policy (fields used for matching) | |
|---|---|---|
Organization type | Nature | |
Company | Domestic | Name, Address |
Company | Overseas | Name, Country |
Individual | Employee | Name, Social number |
Individual | Customer | Name, Sales representative |
Individual | Prospect | Name, Address |
Null | Null | Name |
Table 9: Example of matching policy contexts for the table 'Party'
In this example, six different matching policy contexts are defined and associated with five different matching policies: (the policy '(Name, Address)' is used twice).
The add-on relies on three tables to manage the configuration of matching policies:
Matching policy context
Matching policy
Matching field
The relationships between these tables are as follows:
A matching policy is linked to the table for which matching is configured (mandatory) and to a matching policy context (optional).
A matching field is linked to a matching policy (mandatory).
You can also define contexts per dataspace and dataset to execute matching policies depending on the data life cycle. This configuration is done directly in the 'Matching policy' table.
Matching policy configuration
In this section, you will find information on how to configure Matching policy and detail description of all properties under Matching policy group.
Note
You can test a new or existing matching policy configuration to ensure it returns the desired results. See Testing a matching policy for more information.
Matching policy context
Matching policy context table (logical name: MatchingPolicyContext).
Properties | Definition |
|---|---|
Code | Any naming convention without white spaces can be used. |
Table | A link to a table under the add-on's control. |
Name | Name of the matching policy context. |
Field contexts | Field context: a field in the table used as the context. Use foreign key value: when enabled, the foreign key's value is used instead of its label. This option only displays when the chosen 'Field context' is a foreign key field. Value: value of the field. The value is case sensitive.
A multi-valued field cannot be selected as a field context. To use such a field, you need to create a new field with a function that aggregates the values into the excepted format. Then, this field can be used as a field context. When a foreign key field is defined, the 'Default label' is used to compare by default. If there is no 'Default label' set, 'Programmatic label' is used. In case neither 'Default label' nor 'Programmatic label' set, the field value is considered empty. |
Context Java class | A Java class you define to extend the MatchingPolicyContextChecker.java API.
|
Table 10: Matching policy context properties
The use of matching policy contexts is optional. A matching policy can be configured without a context (see field 'Is context') in the Matching policy table below.
Any number of fields can be defined as part of a context. Fields are combined using the 'and' operator. Defining a context with only one field is possible. A 'field context' can be a value function that dynamically computes a record's context based on business rules. For instance, depending on a list of countries, the 'Language' context field can be computed automatically.
Matching policy
Special Notation: | |
|---|---|
| The configuration for a table must declare one active matching policy with no context. When several matching policies are active for different contexts, then the policy with no context is used by default for every execution not related to a context. |
Matching policy table (logical name: MatchingPolicy)
Properties | Definition |
|---|---|
Code | Any naming convention without white spaces can be used. |
Short description | A description of the policy. |
Long description | Long description of the policy. |
Table | Table for which this policy is defined. |
Active | If 'Yes': This matching policy is used. If 'No': This matching policy is not used. This field indicates whether or not the policy will be used when running matches. Since the add-on manages the matching policy context, it means that one or more matching policies can be active at the same time for a given table. To disable a matching policy, set the active field to 'No'. Only one matching policy can be active for each matching context. One active matching policy with no context must be configured. It is used by default matching at execution time when a matching execution has no relation to a defined context. |
Is forced to void | If 'true': The matching policy short-circuits upon execution. This allows you to have an active matching policy for which matching does not execute. If 'No': The matching policy executes per its configuration. When set to 'No', the property 'Is forced to void' has no effect on normal matching execution. Default value: 'false' |
Funneling matching | If 'Yes': The funneling matching mode is activated. If 'No': The funneling matching mode is deactivated. Default value: 'No'
|
For match at once | The matching policy used for 'Match at once' operations. A table can have only one matching policy active at a time for this type of operation. If no 'For match at once' policy is specified, then the default policy is used by 'Match at once' operations. |
Modify Merged without match | When a Merged record is modified with 'Merged record is recycled' activated, you can decide whether to re-run the 'Match table' operation. If the target record (Pivot or Golden) is auto-created: Survivorship applies to merge data from all Merged records which have the same target record and cluster as the modified Merged record. The 'No match when modifying Merged record' option is ignored by the add-on. If 'Yes': When the Merged record and its target (Pivot or Golden) are in the same cluster, the merged retains in the current cluster and the Survivorship is applied to merge data from all Merged records in the cluster to the target record, 'Is forced to void' is ignored. Otherwise, the Merged record is untouched. If 'No': The add-on keeps the current behavior when 'Merged record is recycled' is activated. Default value: 'No' |
For group at once | The Matching policy used for 'Group at once' operations. A table can have only one matching policy active at a time for this type of operation. If no 'For group at once' policy is specified, the default policy is used by 'group at once' operations. |
For search before create | The matching policy used for the 'Search before create' feature. A table can only have one active matching policy with 'Search before create' enabled at a time. If the 'For search before create' policy is not specified, the default policy will be used. |
Keep not matched records untouched | Determines whether records keep their current state after a matching operation produces no matches. This setting applies to the following 'Match at once' services: Match at once, Match at once full mode, Parallel match at once and Exact match at once. If set to 'Yes': The Unmatched, To be matched, and Suspicious records remain in their current state when no matches are found. If set to 'No' or not defined: Records that do not have any matches become Golden in cluster 01. Default value: 'No' |
Automatically create new golden | If 'Yes': The add-on automatically creates a new golden record when it identifies a positive match between records. This property is only applied in the case of record creation, modification or a 'Match table' operation. It is used only if the survivorship property is 'On' and if survivorship rules are defined. The process used by the add-on for golden creation is as follows:
If 'No': A new golden record is not automatically created when there is a match. Default value: 'No' Note that if there is already an 'Auto-created' record in the cluster, that record will be chosen as the new golden. |
Auto create new golden in match at once | If set to 'Yes': The 'Automatically create new golden' service applies when running a 'Match at once' service including 'Exact match at once' and 'Exact match at once in memory'. It is used only when you set the survivorship property to 'On' and define survivorship rules. If set to 'No': The 'Automatic create new golden' is not applied when running a 'Match at once' service. Default value: 'No' Note that if there is already an 'Auto-created' record in the cluster, that record will be chosen as the new golden. |
Auto create new golden for single golden | If set to 'Yes': When a match results in the creation of a single Golden, the add-on duplicates the record and moves both records into a new cluster. The auto-created record becomes Golden, and the former single Golden becomes Merged targeted to the new auto-created record. The newly created Golden record has the same behavior as other records as it is modified or under a matching operation. This property is applied:
If set to 'No' or not defined: The 'Automatic create new golden' is not applied. Default value: 'No' |
Customize source value for new golden | If 'Yes': When the 'Automatically create new golden' property is activated, the value specified by the 'Source value' property updates the source field's value in the newly created golden record. The 'Source value' property is configured in the matching policy. If 'No': The source field value in the newly created golden record isn't updated. Default value: 'No'. |
Source value | A source identifies a system that provides data either at the record or field level. The source is selected from the 'Source' table. |
Is context | If 'Yes': This policy is executed for a matching context defined by the link to the 'Data life-cycle context', the 'Matching policy context' table and/or the 'Workflow context'. When several matching policies are candidates for a composite context based on two or three values among 'Data life-cycle context', 'Matching policy context', and 'Workflow context' then a priority is applied as follows, based on a weight average: 'Data life-cycle context' = '2', 'Matching policy context' = '1', 'Workflow context'='4'. The selection procedure is as follows:
If 'No': This matching policy is not related to any matching context. Default value: 'No' |
Data life cycle context | A matching policy can be defined for a specific dataspace and/or dataset. This property is a link to a data life cycle context (dataspace and/or dataset). An undefined value deactivates this context. |
Matching policy context | Matching policy context for which this matching policy is defined. An undefined value deactivates this context. |
Workflow context | When executing a workflow you can define a property (cf. Workflow User tasks) that specifies execution of a specific matching policy. Then, the 'Workflow context' property is set to the same value as the one used in the user task. An undefined value here deactivates this context. |
Pivot record selection mode | This rule is applied by the add-on (Match table and Match at once operations) to decide which of the suspect records is the pivot record (see Record selection policy section for further information on the different strategies that the add-on can apply). This policy is disabled when 'Golden is preserved for selection' or 'Automatically create new golden' is applied. Default value: 'New update' Note that auto-created records are given the highest priority. |
Golden is preserved for selection | If 'Yes': The Pivot record selection mode will prioritize a record identified as 'Golden' or 'was golden' if it exists in the cluster. If many records with the 'Golden' or 'was golden' identifier exist, the 'Most recently acquired' record is used. If there is no record with 'was golden' marker or no 'Golden' record, then the 'Pivot record selection mode' executes normally. This property is used to select the pivot record in case of record creation and modification only. It is not used with the 'Match table' and 'Match at once' operations. If 'No': The 'Pivot record selection mode' does not use the 'was golden' indicator or 'Golden' state. Default value: 'No' A record is identified as 'was golden' when its state was golden but has been changed because of a new matching. |
Main matching algorithm | The default algorithm for matching all fields that use this matching policy. If required, the matching policy algorithm can be changed at the field-level (see table Matching field). You can refer to the Matching strategies section for information that will help you decide which algorithm to use. The selection of the main algorithm is mandatory. |
Second matching algorithm | The algorithm used to manage records that could be false negative results after main algorithm execution. It is used after the first matching procedure to ensure that no suspect records have been missed. It is not possible to override this matching algorithm at the field-level. You can refer to the Matching strategies section for information that will help you decide which algorithm to use. |
Ignore case | If set to 'Yes': All algorithms and the following 'Exact matching' operations ignore case sensitivity: - Filter by - Business ID - Exact match at once - Filtering field rule - Synonym If set to 'No': All algorithms and 'Exact matching' operations will be case sensitive. Default: 'No' |
Exclude records from matching | If you want matching to ignore records when a field contains specific values:
When one of these values is equal to the field value of record then the record is ignored by the matching operation. When a record is created and has excluded value, then its state moves to 'To be matched'. When a record is modified and has excluded value, then its state is not modified. To declare an empty value, use the following constant: osd:is-empty |
Filtering record rule | A business rule can be applied to filter records that must be excluded when matching against the pivot record. This feature is used when the matching policy's 'Exclude record from match table' property is not sufficient (based on a direct equal value of string). The applied rule is configured in the 'Filtering record rule' table. The bespoke parameters group of fields passes parameter values to a rule when needed. Then, the rule needs to be able to manage these parameters. When a record is created and matches with the filtering rules, then its state moves to 'To be matched'. When a record is modified and matches with the filtering rules, then its state is not modified. |
Filter by | When matching a large volume of records, perhaps numbering in the millions, you can improve fuzzy match response time by using a fast filter that returns a subset of records to match. The filter used a 'Exact' query. The fuzzy match is then applied on this subset of records only. You can combine multiple fields in the filter, the 'And' operator is then applied. To guarantee the best performance, you must declare the filter field(s) as index (see EBX® documentation). The 'Match at once' operation uses the 'Filter by' property. However, the 'Exact match at once' operation does not because it acts as a filter on its own. |
Handle null value for filter by |
Default value: [Not defined] |
Literal score | 'Exact' value is available. When using the 'Exact' matching policy, this property means that two records are considered as potential duplicates when at least one business identifier field value is equal. This business identifier is defined in the 'Table' (See Matching policy with exact score example in the Matching policy section.) configuration. |
No match records when same source | If 'Yes': Two records from the same source will never match. You can use this option if the 'Source field' is configured at the 'Table' level. The add-on checks to ensure no records from the same source exist in the target cluster prior to moving a record. If there is any record from the same source detected, the record remains in its state in the current cluster. Source field value of suspect records will never be merged into the pivot record. If 'No': The matching is achieved in a normal way when the records come from the same source that is based on the 'Source field' configuration at the 'Table' configuration level. Default value: 'No' |
Narrow search | Activate this option to reduce the memory usage for matching. When this option is activated for matching policies that have low stewardship min scores, only records that are closely similar are included during matching. Default value: 'No' |
Threshold matching | These threshold matching values are not mandatory. They are used instead of the corresponding values that are defined at the process policy level. If one field is provided then the add-on will use all of them rather than the values specified at the process policy level. In this case, the four values become mandatory. Stewardship min score (%): If undefined, the value configured at the Process policy level is used. When a match score is lower than this threshold then the add-on does not consider the record to be a suspect record. Stewardship max score (%): If undefined, the value configured at the Process policy level is used. When a match score is higher this threshold, the add-on enforces an automatic merge of this record into the pivot or golden record. This procedure is also known as 'survivorship'. Above this value, the record is merged automatically. It is important to select this value carefully, as if it too low, records may be automatically merged with pivot and golden records that are not actually related. When scores fall between the 'Stewardship min score' and the 'Stewardship max score' values, a user decision is needed to determine how to manage the suspect record (stewardship process). Threshold second matching(%) If undefined, the value configured at the Process policy level is used. When the score computed by the first algorithm falls between 0% and the specified 'Threshold second matching(%)' then the second algorithm is applied to detect potential false negative records. For example, if 'Threshold second matching' is set to '5%' then the second algorithm is executed each time the score of the first algorithm is lower than '5%'. Constraint: 'Threshold second matching' is lower than or equal to 'Stewardship min score'. This property is used when the 'Second matching algorithm' property in the matching policy is not empty. Default value: '0' Second level stewardship min score (%) If undefined, the value configured at the Process policy level is used. When the second level of matching is configured to seek false negative records from the first matching, then this threshold is used to evaluate if the matching score provides a suspect or not. This property is used when the 'Second matching algorithm' property in the matching policy is not empty. |
Matching through a relation | |
Use matching through a relation(s) | 'Relation matching' allows the add-on to match data through existing table or join table relationships. If 'Yes': For the matching operation, the add-on combines the table on which this policy is configured with any table related to it either by join or by relationship. If 'No': The relational matching configuration is ignored. Default value: 'No' |
Relation record score weight | This property allows you to configure the matching score weight that is computed for the 'Relation table'. The matching score obtained for the 'Relation table' is combined with the score computed on the 'Table to match' through a weighted average. Default value: '1' |
Relation record stewardship min score | This is used when the 'Funneling mode' property in the matching policy is active. If the score of the field is lower than the 'Field stewardship min score' then there is no match. By default the value is set to 100 to make the threshold inactive. Default value: '100' |
Use join table | If 'Yes': The relation match is configured through a join table between the 'Table to match' and the 'Relation table'. If 'No': The relation match is configured with a direct relation between the 'Relation table' and the 'Table to match'. Default value: 'No' |
Relation match with join table | Join table
Link: Join table → Table to match
Relation table
Link: Join table → Relation table
Matching policy on Relation table
|
Relation match without join table | Relation table
Link: Relation table → Table to match
Matching policy on Relation table
|
Table 11: Matching policy properties
Matching field
Configuration of the fields used in matching execution time.
Matching field table (logical name: MatchingFieldRule)
Properties | Definition | |
|---|---|---|
Code | Any naming convention without white spaces can be used. | |
Matching policy | Reference to the 'Matching policy' table. | |
Field | A field in the table that is analyzed by the referenced matching policy. This field is used during the matching procedure. If the field value is empty at execution time, then matching is not enforced. It is possible to match inside a list. Two lists of values will match when at least one value matches the two lists. For instance (John, Carl, Paul) will match with (Frank, Theo, John). | |
Foreign key | A list of foreign key fields. You define a path to another field—an alternative to the one defined by the 'Field' property—to execute matching on by creating hops to navigate the relationships. The add-on uses the value from the last hop during the matching procedure. The foreign key 'Default label' is used to compare by default. If there is no 'Default label' set, 'Programmatic label' is used. In case neither 'Default label' nor 'Programmatic label' set, the field value is considered empty. | |
Handle null value matching | Provides null value matching strategies using the following options:
In case the returned matching result is 0%, the Surrogate field (if exists) is used to match instead of the configured matching field. Note that an undefined foreign key matching field will be considered as null, and this property does not support multi-hop foreign key. | |
Matching algorithm | By default, the algorithm used is the one defined as the main algorithm in the table's matching policy. This default value can be changed to select another algorithm. | |
Score weight | When several fields of a source table are used for matching, the score weight is used to give a weight to each field score that the add-on uses to compute a weighted average. Example: '0.5' means the score of the field is worth half (50%). If a matching field is empty then the weighted average does not take into account this field. Default value: '1' | |
Score calculation | Defines how the score is calculated: - Real score: The exact score returned by the algorithm. - Normalize score: The score will be the maximum score of the maximum stewardship defined minus 0.1. This strategy can be used to avoid auto merge of records when they are not strictly identical. - Default value: Real score | |
Field stewardship min score (%) | Used when the 'Funneling mode' property in the matching policy is active or in a surrogate field matching. - When the 'Funneling mode' property is active: If the score of the field is lower than the 'Field stewardship min score' then there is no match. By default the value is set to 100 to make the threshold inactive. - If the field score is lower than 'Field stewardship min score', surrogate field (if exists) is used to match instead of the configured matching field. | |
Filtering field rule | A business rule can be applied to filter the field value in order to ignore characters such as N/A, Inc., *, $, etc. before the match execution. A rule can perform any type of filter. One example is removing all figures in a string. The filter is applied to the pivot record and the records involved in the match. It is performed in memory and does not change the actual value of the data in the repository. Only string fields can be filtered. Foreign key values cannot be filtered. The bespoke parameters group of fields is used to pass parameter values to a rule when needed. Then, the rule must be able to manage these parameters. The filtering field rule must depend on the record's fields. | |
Use synonym group | A group of synonyms can be selected. If a field value in the suspect record does not match with the pivot, then a new matching is achieved with the synonym values rather than the initial value in the suspect field. The first positive match is used to get the final score. When values are the same with any case difference, the score will be max score - 0.1. | |
Check synonym in all groups | If 'true': When matching uses the synonym mechanism, it searches through all child synonym groups. If 'false': When matching uses the synonym mechanism, it searches through each separate child synonym group. | |
Smart synonym matching | When matching uses the synonym mechanism, it checks whether strings from the specified field match with values in the list of synonyms. If a value matches, the add-on replaces it with the shortest value before running match. If it matches 100% then the record score is equal to the maximum score -0.1. When there are several synonyms with the same length, the first value in the list will be taken to replace for other synonyms. | |
Use smart synonym matching: If set to 'Yes': The Smart synonym matching is applied. If set to 'No': The Smart synonym matching is not applied. Default value: 'No' | ||
Ignore case: If set to 'Yes': Ignores case when Smart synonym matching is activated. If set to 'No': Smart synonym matching is case sensitive. Default value: 'No' | ||
Surrogate fields | Defines the fields and comparison mode applied in a matching when the returned score on the configured matching field is lower than the 'Field stewardship min score'. | |
Field | List of fields in the matching table with the same data types which can be configured as alternative matching fields. | |
Comparison mode |
| |
Table 12: Matching field properties
Special notation: | |
|---|---|
| Configuration of the weighted average to take into account an empty field. |
Matching algorithm
The add-on provides several predefined algorithms.
Matching algorithm table (logical name: MatchingAlgorithm)
This table is located under the EBX® Administration Tab in the 'Matching reference data' dataset.
Properties | Definition |
|---|---|
Name | Algorithm name (Eg. DoubleMetaphone, FuzzySearch, Levenshtein, etc.) |
Description | Context of use. |
Is prebuilt | If 'Yes': The algorithm is provided by the add-on. If 'No': The algorithm is not provided by the add-on. |
Is percentage score | If 'Yes': The algorithm provides a similarity score. If 'No': The algorithm provides a binary score (Match=1, Unmatch=0). When the score is equal to Match, then the add-on systematically overwrites the score to 'Stewardship min score + '1' '. |
Java class | Specifies a Java reference to provide a custom algorithm. |
Table 13: Matching algorithm properties
Predefined algorithms
The add-on provides these predefined matching algorithms.
Algorithm | Default parameters | Description and Parameter configuration (if applicable) |
|---|---|---|
Chinese | Allows matching in Chinese. | |
Double metaphone | Max code length = 4 | This phonetic algorithm works best on short strings, such as proper names. It is especially adept at returning words or names whose actual pronunciation may be different than the search text entered. The Max code length property limits the code length used to find possible matches. When you enter a search string, the algorithm encodes it as a key and returns words with matching keys. You should set this property to a value that reflects the length of text being searched. For example: If you specify a value of 4, the algorithm encodes the three words "cricket", criket" and cricketgame" as "KRKT". The algorithm considers the three words a match. If you changed the value to 8, "cricket" and "criket" are still encoded as "KRKT". However, it encodes "cricketgame" as "KRKTKM". In this case, "cricketgame" no longer matches. Note that this algorithm cannot be used to search numeric, date/time, or special character formats. Also, due to the way the algorithm processes phonetic structures, a search for "www" returns no result. |
Double metaphone Levenshtein | Max code length = 4 | Being a phonetic algorithm, Double Metaphone may fail to match misspelled words when the misspelling substantially alters the phonetic structure of a word. The Double Metaphone Levenshtein algorithm can compute distance between two long strings, but at the cost to compute it, which is roughly proportional to the product of the two string lengths. So, a combination of these algorithms reduces their limitations. Levenshtein may find similarity between encoded strings, and the length of encoded strings is limited by Double Metaphone. |
Exact | This algorithm returns a matching score of 100% for empty field values. Even though this algorithm runs an exact match on the specified field(s), other fields can use different matching algorithms. This means one matching operation may include multiple algorithms. If you want to improve response time by executing a purely 'Exact' match, refer to the matching policy's 'Filter by' property. Alternatively, you can use the 'Exact match at once' service. | |
Full text | This algorithm finds a non-case sensitive, exact match of the entered keyword in data of longer strings. | |
FuzzyFullText | Similarity = 0.7 Prefix length = 0 | This algorithm works best for general strings like those contained in descriptions. This algorithm finds a similar, or fuzzy, match of the keyword text entered. The Similarity parameter determines how similar results have to be before they are returned. The higher you set the value, the fewer results and vice versa. The Prefix length parameter specifies that a number of characters from the beginning of the keyword must exactly match data being searched in order to return a result. For example, if you set the value to 2 and use the keyword "Automotive", the algorithm only considers words that begin with "au" as potential matches. |
FuzzyJapanese | Similarity = 0.7 Prefix length = 0 | This algorithm performs a search on Japanese text and finds a similar, or "fuzzy" match. This algorithm allows you to use the following character types or any combination thereof: Kanji, Katakana and Hiragana. The Similarity parameter defines a value between 0 and 1, which is used to set the required similarity between the query terms and the matching terms. The similarity level is calculated based on the Levenshtein algorithm. For example: For a similarity of 0.5, a term of the same length as the query term is considered similar to the query term if the edit distance between both terms is less than length(term)*0.5. The Prefix length parameter specifies the number of characters-from the beginning of the search term-that must exactly match in order to return a result. For example: The keyword 'クリニク' will match 'クリニック' if the Prefix length < 4 and Similarity = 0. |
FuzzyRussian | Similarity = 0.7 Prefix length = 0 | Performs a search on Russian text and finds a similar, or "fuzzy" match. The Similarity parameter defines a value between 0 and 1 to set the required similarity between the query term and the matching terms. The similarity level is calculated based on the Levenshtein algorithm. For example: For a similarity of 0.5, a term of the same length as the query term is considered similar to the query term if the edit distance between both terms is less than length(term)*0.5. The Prefix length parameter specifies the number of characters-from the beginning of the search term-that must exactly match in order to return a result. |
Japanese | Performs search on Japanese text. This algorithm allows you to use the following character types or any combination thereof: Kanji, Katakana and Hiragana. | |
Jaro Winker | threshold = 0.7 (a condition to add Winkler distance or not. Value is from 0 to 1) | This algorithm works best on short strings, such as proper names. It tallies the number of characters in common and places a higher emphasis on differences at the start of the string. Therefore, the lower you set the Threshold parameter, the more impact differences at the beginning of strings have. Threshold parameter values should be from 0.0 to 1.0. |
Levenshtein | This algorithm works best for short strings where you expect few differences between the keyword and the data being searched. For example, this works well for dialects spoken in a particular part of the country, or by a specific group of people. | |
NGram | Item size (n) = 2 | This algorithm partitions search criteria into subsets of a specified length called NGrams. You set this length using the Gram size property. For example, if you set this property to a value of 3, the algorithm splits the word PHASED into the following N-Grams: PHA, HAS, ASE and SED. PHASED is then added to the lists of words containing those N-Grams. Keep in mind that if you set the size too small, the algorithm may not capture important differences and return too many terms. If the size is too large, the opposite is true and may result in few returned results. Therefore, when used for names, a value of 3 or 4 is recommended. For phone numbers, a value of 7. |
Russian | This algorithm allows you to search text in Russian. | |
SearchDate | Threshold = 5 | This algorithm allows you to search on fields with date or, date-time data types. In order for a date to match, it must be in the range specified by the search input plus/minus the number of days specified in the Threshold parameter. The closer the search input is to the data being searched, the higher the score. When you increase the Threshold parameter's value, the score decreases: Score = 100-(distance*100/threshold) |
SearchNumber | Threshold = 5 | This algorithm allows you to search on fields with a numeric data type. In order for a number to match, it must be in the range specified by the search input plus/minus the value set in the Threshold parameter. The closer the search input is to the numbers being searched, the higher the score. In order for a number to match, it must be in the range specified by the search input plus or minus the value set in the Threshold parameter. If the Threshold value increases, the score decreases. Score = 100-(distance*100/threshold). |
Soundex | This phonetic algorithm works best on proper names. It returns similar-sounding words or names by converting the string being searched to a four-character code and returning words with the same code. Note that you cannot use this algorithm to search numeric, date/time, or special characters. | |
Korean | Perform search on Korean text. | |
FuzzyKorean | Similarity = 0.7 Prefix length = 0 | This algorithm performs a search on Korean text and finds a similar, or "fuzzy" match. The Similarity parameter defines a value between 0 and 1, which is used to set the required similarity between the query terms and the matching terms. The similarity level is calculated based on the Levenshtein algorithm. For example: For a similarity of 0.5, a term of the same length as the query term is considered similar to the query term if the edit distance between both terms is less than length(term)*0.5. The Prefix length parameter specifies the number of characters-from the beginning of the search term-that must exactly match in order to return a result |
Table 14: Predefined algorithms
Filtering
Filtering record rule
Filtering record rule table (logical name: FilteringRecordRule)
This table is located under the EBX® Administration Tab in the 'Matching reference data' dataset.
Properties | Definition |
|---|---|
Name | Name of the filtering record rule. |
Description | Context of use. |
Java class | Specifies a Java reference to provide the rule implementation. |
Is prebuilt | If 'Yes': This function is provided by the add-on. If 'No': This function is not provided by the add-on. |
Table 15: Filtering record rule properties
Filtering field rule
This table allows you to remove field values from a matching operation to improve results. For example, depending on configuration settings, the values 'Holding Company Inc.' and 'Holding Company' may not register as a match. You could specify that the value of 'Inc.' gets filtered out during the operation, which would then result in a match.
Filtering field rule table (logical name: FilteringFieldRule)
This table is located under the EBX® Administration Tab in the 'Matching reference data' dataset.
Properties | Definition |
|---|---|
Name | Name of the filtering field rule. |
Description | Context of use. |
Value filter | The field to exclude during matching. |
Java class | Specifies a Java reference to provide the filtering rule. Two built-in classes are available: com.orchestranetworks.addon.daqa.RemoveWordFilter - The add-on applies all values specified in the 'Value filter' property to whole words only. Note that using this class may impact performance. com.orchestranetworks.addon.daqa.RemoveValueFilter - All values configured in 'Value filter' will be applied every time the value is found without taking into account the context. You can define a custom filter by extending the 'MatchingFieldValueFilter' API. |
Is prebuilt | If 'Yes': This function is provided by the add-on. If 'No': This function is not provided by the add-on. |
Table 16: Filtering field rule properties
Matching on several tables
The EBX® Match and Merge Add-on can be configured to match data sourced from several tables using their relationships, namely the foreign keys.
Special notation: | |
|---|---|
| See also the 'Using matching through relation(s)' property in the matching policy configuration. This property allows the add-on to use indirect FK (including join table) and not only direct FK. |
The matching value of a foreign key is its label-in the language of the current EBX® session-rather than its language in the 'Table configuration'.
In the example below, a matching policy is configured to match the name of a 'Party' through his foreign key to the 'Company name' table:
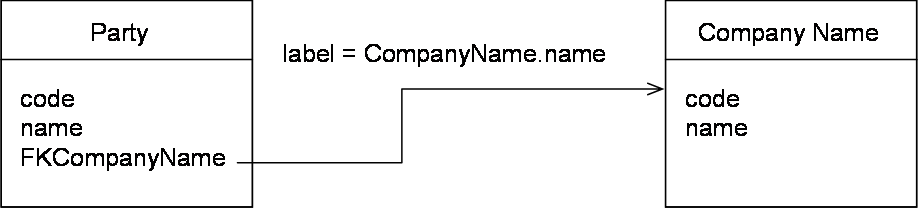
The add-on uses the pivot record on the 'Party' table to get the associated pivot record in the 'Company Name' table, then performs matching on the list of company names. All records of the 'Company Name' table with a score higher than the 'stewardship min score' are used to set up a cluster of related 'Party' records.
Here is an example:
Party name | Company name |
|---|---|
David | Orchestra |
Durand | IZX |
Bonnais | Delta |
Albert | Delttaz |
Bonney | Delttaz |
When a match is executed on the pivot record 'Bonney' with a matching policy applied on the company name, then here is the list of suspect records. In this example, the company Delta and Delttaz is considered with a score higher than the minimum threshold to be a suspect.
Bonnais | Delta |
|---|---|
Albert | Delttaz |
Bonney | Delttaz |
When the foreign key label relies on many fields, the add-on uses the average score of these fields.
Matching through relation tables
'Relation matching' allows the add-on to match data through related tables. The matching results on related tables are then used to calculate the score of data on the source table.
Types of relation matching:
Matching using join table: Matches data of the table defined in the current Matching policy through a join table.
Matching without join table: Matches data of the table defined in the current Matching policy through a related table.
Special notation: | |
|---|---|
| Both the source and target table must be registered with the add-on. |
Properties | Definition |
|---|---|
Relation record score weight | This property allows you to configure the 'Relation table's matching score weight. The add-on combines this table's score with the 'Table to match' score using a weighted average. Default value: '1' |
Relation record stewardship min score | This is used when the 'Funneling mode' property in the matching policy is active. If the score of the field is lower than the 'Field stewardship min score' then there is no match. By default the value is set to 100 to make the threshold inactive. Default value: '100' |
Using join table | If 'Yes': The relation match is configured through a join table between the 'Table to match' and the 'Relation table'. If 'No': The relation match is configured with a direct relation between the 'Relation table' and the 'Table to match'. Default value: 'No' |
Relation match with join table group | The Relation match with join table group contains the following options:
Please note that if the join table does not come from the same data model as the source table, it must be located in the same dataset as the relation table. |
Relation match without join table | The Relation match without join table group contains the following options:
|
Table 17: Relation properties
To apply matching through relation(s):
Register the desired table with the add-on
Create a Process policy for the registered table.
Create a Matching polity for the registered table.
In the Matching policy :
Activate 'Using matching through relation(s)'.
Enable 'Use join table' based on your needs.
Fill in the corresponding properties for each option.
Testing a matching policy
After creating or editing a matching policy, you might want to use the Check similarity service to test whether the policy produces the expected scores. One advantage of testing is that it operates on a small subset of records; you can see results immediately. Also, the Check similarity service does not change the matching metadata for the records involved. Therefore, you can try different configurations without having to update matching states after each test.
The Check similarity service allows you to compare the similarity of two records in the same table. To test, you choose one of the matching policies configured for the table. The policy specifies which fields to compare and the algorithms to use. You can look at the resulting scores to get a preview of how the add-on would handle these records during a matching operation with this policy.
The results returned by the service include the following information for each field:
The field name.
The matching Score weight shows how much importance is assigned to the field's score when calculating a weighted average.
The Algorithm score shows how closely the fields compare using each algorithm listed. Each algorithm configured for the field is listed here.
The add-on translates the algorithm's score into the Similarity percentage score. Refer to Using matching algorithms with the add-on for more information regarding similarity percentages.
The Final score displays an average of the similarity percentages.
To run the service:
Navigate to the table containing the records you want to compare and select two records.
From the table's Actions menu, select Match and Merge > Check similarity.
Use the Matching policy drop-down menu to choose the matching policy you want to test and select Launch.
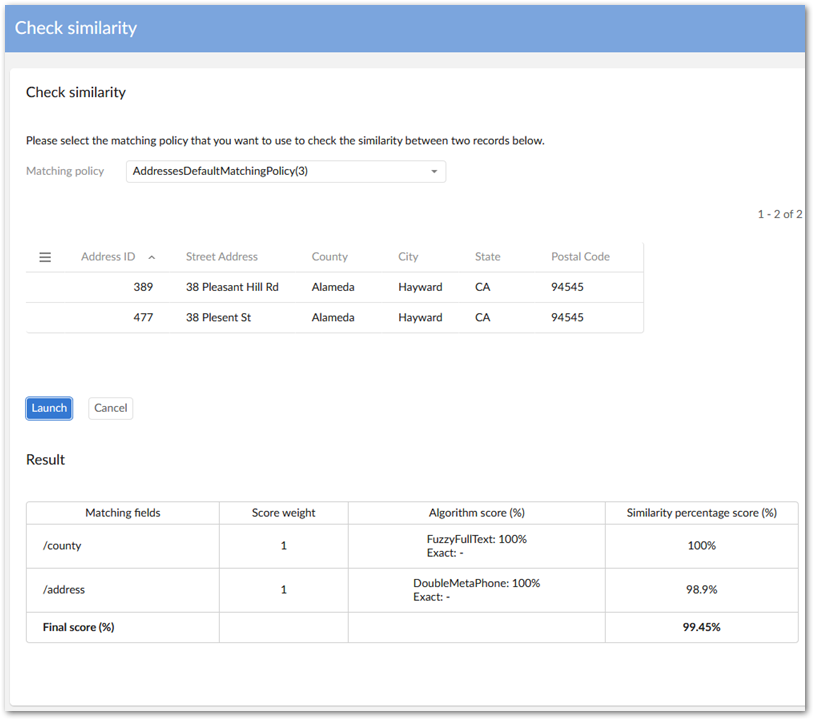
Examples
The sections below show examples of configuring and applying a Matching policy.
Matching policy with exact score
When the configuration literal score = 'Exact' is declared on a matching policy, the business identifier of the table is used as the main criteria for grouping suspect records. This business identifier is not necessarily the primary key, but is one or more fields defined in TIBCO EBX® Match and Merge Add-on → Table → Business ID.
When more than one Business ID field is configured, two records are considered as Suspect if any of the Business ID field values are equal.
The following is an example with an Employee table containing the 'Social number' business identifier. The primary key is a technical object identifier (oid).
Two policies are configured: PO1 and PO2 use the metaphone algorithm on the 'Last name' field, and PO1 is configured with literal score = 'Exact'.
When applying PO1, all suspects share the same business identifier value. PO2, however, does not take the business identifier into consideration as it does not specify literal score = 'Exact'.
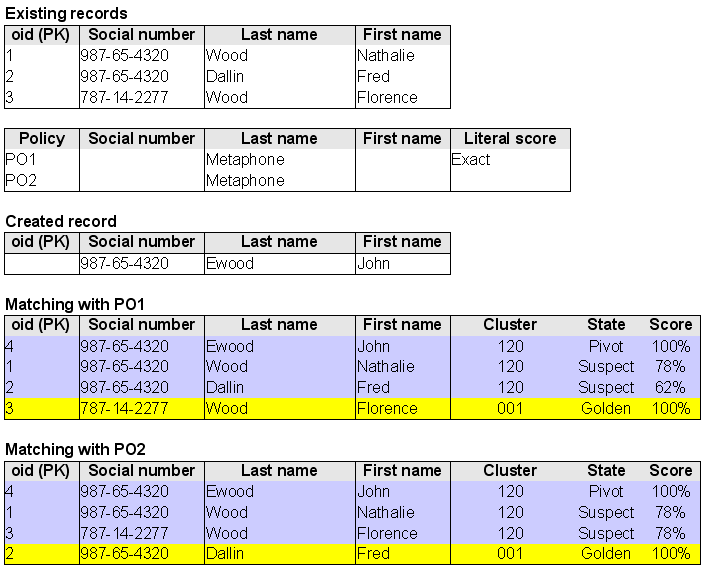
The results are different depending on whether PO1 or PO2 is used.
Matching using Join table
In the Article model, 'Supply points' table is the join table of 'Articles' and 'Suppliers' table.
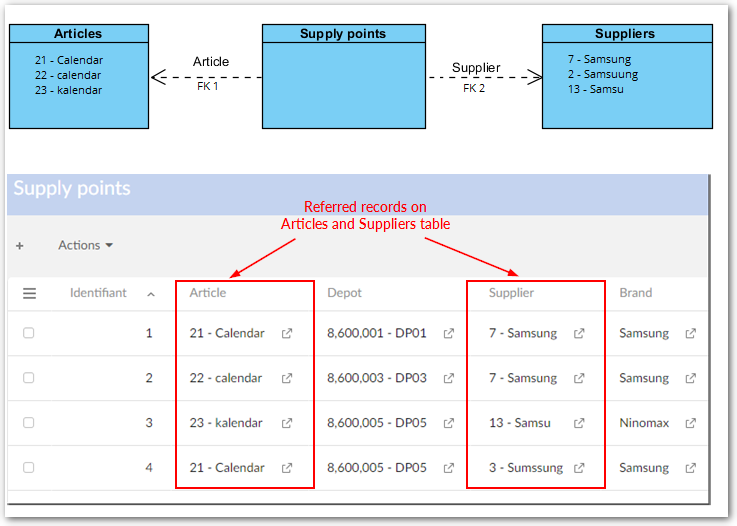
In order to apply matching through the Supply points join table , configure as below:
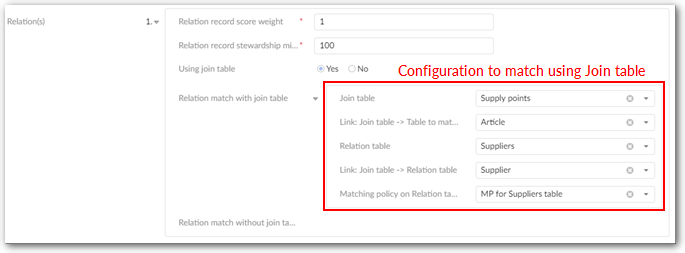
When you modify record '21-Calendar' on Articles table, the add-on firstly finds records (7-Samsung and 3-Samssungg) in the 'Suppliers' table ('Relation table') that link to the modified record via the 'Supply points' table('Join table'). Those records are considered as the Suppliers table's pivots. The add-on then executes matching on those pivots using the Matching policy configured for the Suppliers table. The higher scores between two matches are taken as the final score of records in the 'Suppliers table.
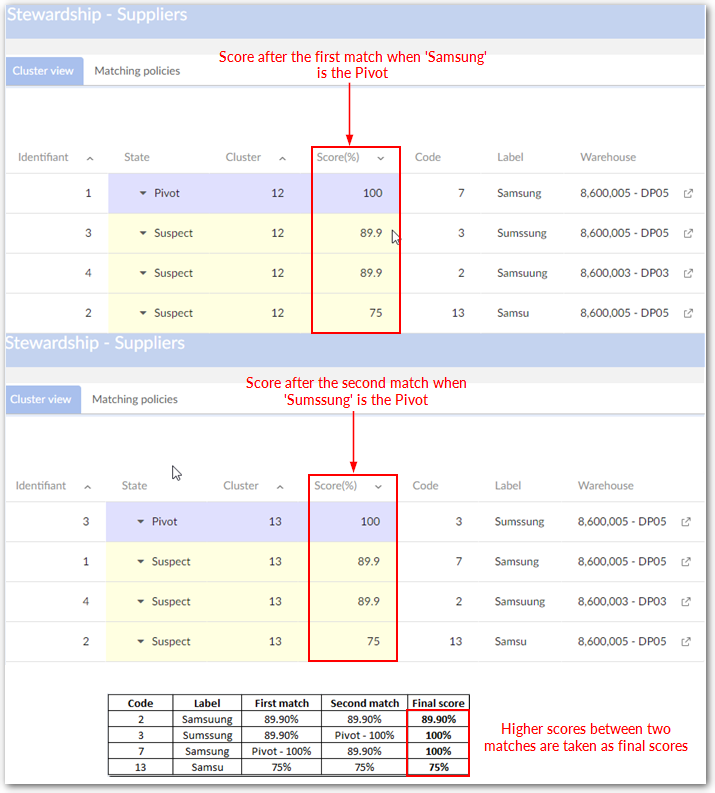
Once matching finishes on the Suppliers table, the add-on performs a reverse look up to find Suspect records (22-calendar and 23-kalendar) in the Articles table based on the foreign key. Matching then executes using the Matching policy configured for the Articles table.
If there is no Matching field is configured, scores of the Suspect records in Articles table are scores of the corresponding records in Suppliers table.
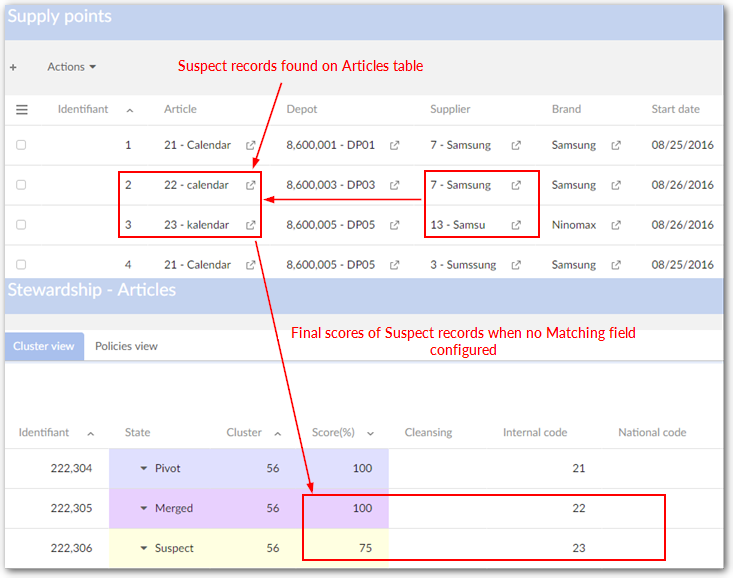
In case 'Reduced label' is configured as the Matching field, the scores of Suspect records on Article are calculated as below:

The add-on then combines results and calculates final score of Suspect records in the Articles table using matching field score weights:

Smart synonym matching
In the following example, the Articles table is configured to use smart synonym matching with the SmartSynonym - Pennsylvania Avenue synonym group.
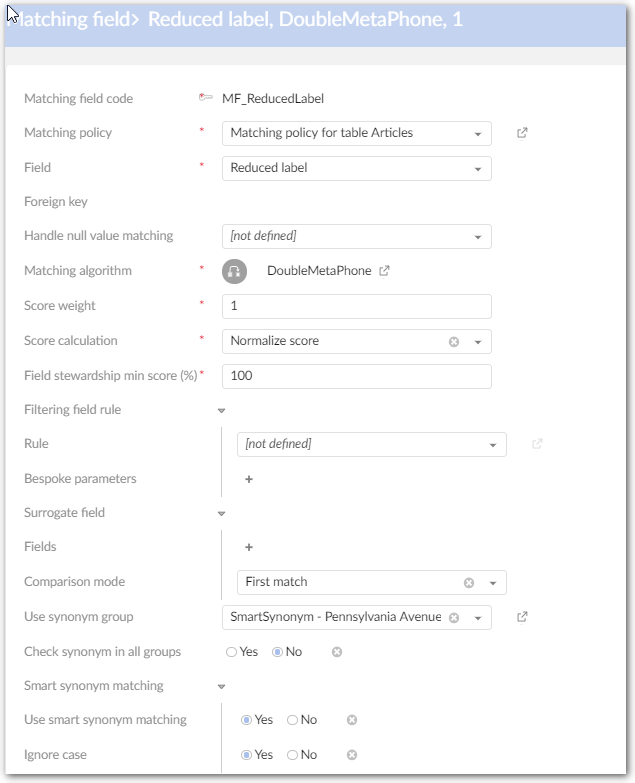
In the Articles table, there are two records with reduced labels '400 Pennsylvania Avenue' and '400 Penn Ave'. The 'SmartSynonym - Pennsylvania Avenue' group contains two child groups naming 'Pennsylvania' and 'Avenue' as shown below:
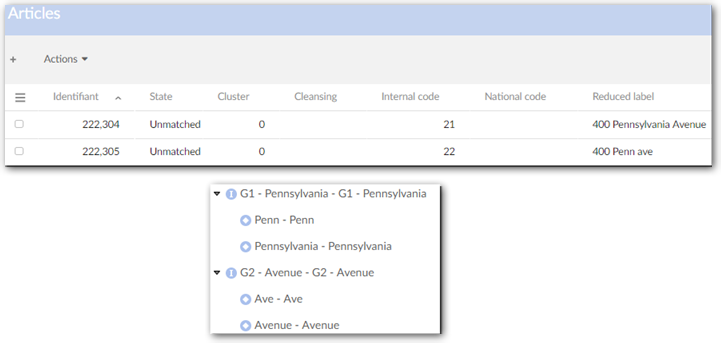
When you execute matching on the Articles table, the add-on checks if any strings of '400 Pennsylvania Avenue' existing in recursive child and parent groups of 'SmartSynonym - Pennsylvania Avenue'. If the string exists, the add-on replaces the original string with the shortest value before matching. '400 Pennsylvania Avenue' now becomes '400 Penn Ave' before matching and after matching returns a final score of 89.9% (max score - 0.1).
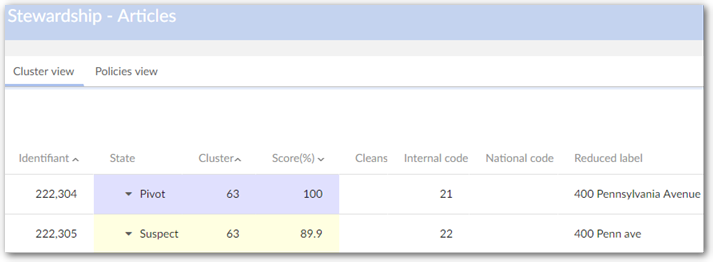
Matching with an alternative field - Surrogate matching
When the matching result on a record is lower than the configured 'Field stewardship min score (%)', you can use another field to match with the current matching field. Make sure that the current matching field is not a complex field, foreign key field, multiple-value field or enumeration field.
In matching field table → Surrogate field → Fields, select alternative fields in the drop-down list of fields which have the same data type as the current matching field in the matching table. You can configure more than one field to be the alternative matching fields.
As the following example, on Article table, executes 'Match table' on the record with 'Identification' 222305:
When the 'Surrogate field' is not defined: no record matches and both become Golden.
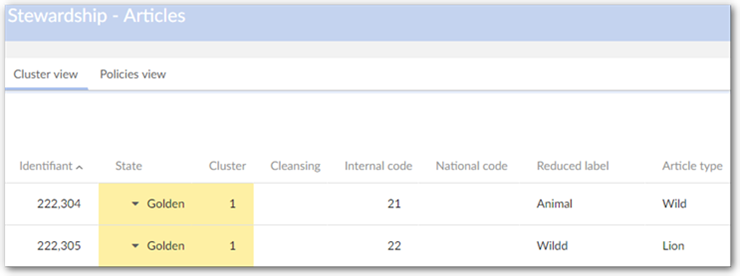
When 'Article type' is configured as surrogate field with the 'First match' comparison mode:
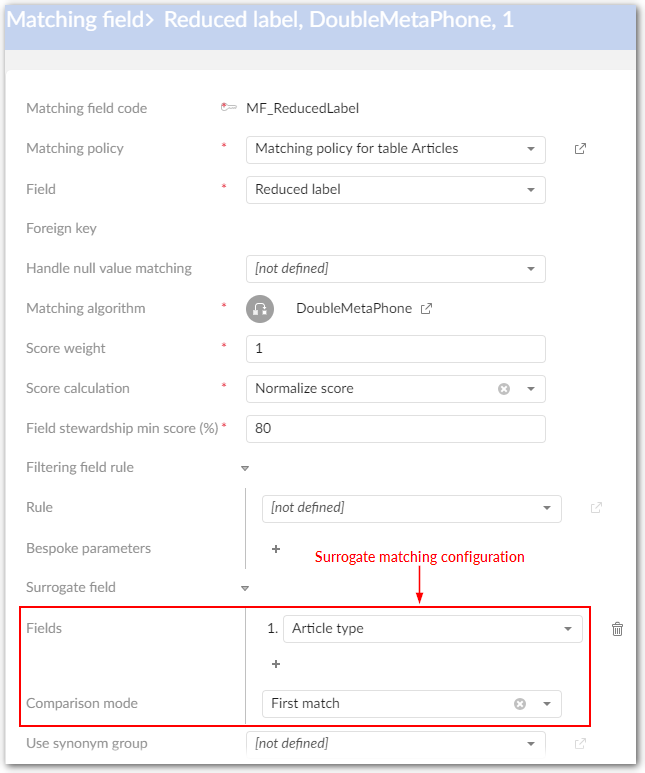
'Article type' value of record 222304 is used to match with 'Reduced label' value of record 222305. Record 222304 then becomes Suspect with the returned matching score of 89.9%.
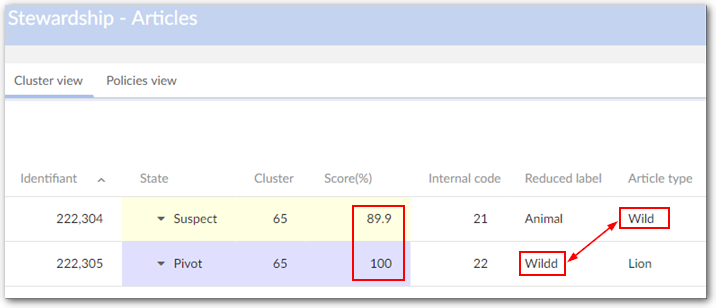
All information of the surrogate matching is stored in DaqaMetadata.
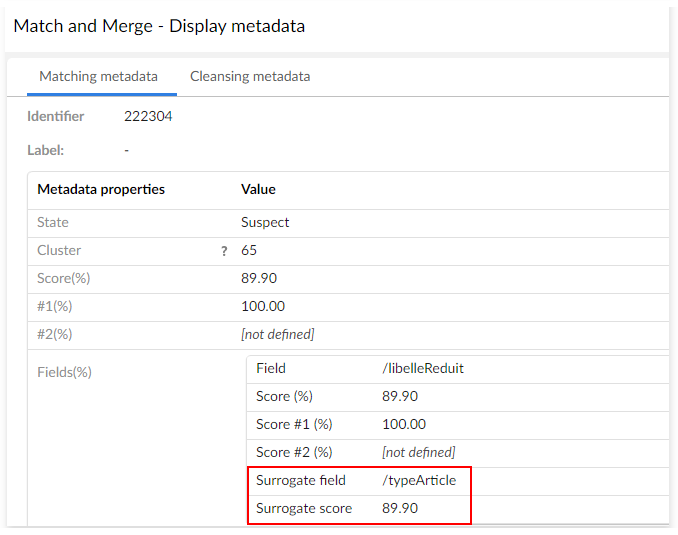
Survivorship policy
Introduction
A survivorship policy is applied to a table in order to define how the add-on performs automatic merging of suspect records into a target record.
Once the survivorship target record is identified by applying a 'survivor record selection mode', the add-on executes an automatic merge from suspect records to this target record based on the following rule: only suspect records with a score higher than the stewardship maximum value defined in the process policy are merged.
The add-on relies on four tables to manage the configuration of survivorship policies:
Survivorship policy context.
Survivorship policy.
Survivorship field.
Survivorship function (in the 'Reference data' part of the configuration).
The relationships between these tables are as follows:
A survivorship field must be linked to a survivorship policy and a survivorship function.
A survivorship policy must be linked to the table on which matching is configured.
A survivorship policy can be linked to a context.
Fields with data types 'value function', 'password' and 'uda' are not merged.
Special notation: | |
|---|---|
| At execution time, depending on the 'On survivorship' property configured in the 'Process policy', the automatic merge procedure is as follows:
|
Survivorship configuration
Survivorship policy context
Survivorship policy contexts ensure that automatic merge occurs only when field values meet certain conditions. Each context can apply to one or more fields. In turn, you can specify multiple values as conditions to satisfy for each field.
Survivorship policy context table (logical name: SurvivorshipPolicyContext)
Properties | Definition |
|---|---|
Code | Any naming convention without white spaces. |
Table | Link to a table under the add-on's control. |
Name | Name of the survivorship policy context. |
Field contexts | Field context: a field in the table used as the context Use foreign key value: when enabled, the foreign key's value is used instead of its label. This option only displays when the chosen 'Field context' is a foreign key field. Value: value of the field For an empty value this constant must be used: osd:is-empty A multi-valued field cannot be selected as a field context. To use such a field, you need to create a new field with a function to aggregate the values into the excepted format. Then, this field can be used as a field context. |
Table 18 :Survivorship policy context properties
Survivorship policy
When defining this type of policy, you can use the Default survivor field to apply conditions for survivorship to all of a table's fields (excluding the primary key and source field). To define these conditions, the add-on allows you to:
Choose a function from the Survivorship function list to specify how the add-on selects the most likely duplicate record from a list.
Use the Condition for field value survivorship to enter an expression that defines a condition that must be met for survivorship.
Specify that the add-on merges values into the golden or pivot record depending on whether the field in the survivorship record is empty.
When you define conditions in the Default survivor field, a record must satisfy the record must satisfy the function and condition to be survived.
Special notation: | |
|---|---|
| When several survivorship policies are active at the same time for different contexts, then the policy with no context is used by default for every execution not related to a defined context. If no survivorship policy is declared, then the pivot will be considered as survivor record and no automatic merge of fields is performed. |
Survivorship policy table (logical name: SurvivorshipPolicy).
Properties | Definition |
|---|---|
Code | Business code of the survivorship policy. Any naming convention is possible. |
Short description | Description of the survivorship policy. |
Long description | Long description of the policy |
Table | Table for which this survivorship policy is defined. |
Active | If 'Yes': This survivorship policy is used. If 'No': This survivorship policy is not used. At execution time, depending on the 'On survivorship' property configured in the 'Process policy', the automatic merge procedure is as follows:
|
Is context | If 'Yes': This policy is executed for the context defined by the link to the 'Survivorship policy context'. When creating multiple context-based survivorship policies, you can define a default survivorship policy. When conditions do not meet those specified in the context(s), the add-on uses the default survivorship policy. If you choose to not define a default policy and conditions do not meet those specified in the context(s), the add-on takes no survivorship action. If 'No': This survivorship policy is not related to any matching context. Default value: 'No' |
Survivorship policy context | Survivorship policy context for which this survivorship policy is defined. |
Survivor record selection mode | Rule applied by the add-on to decide which record will be the survivor amongst a set of suspect records: refer to 'Record selection policy'. The add-on still automatically chooses a record based on the current settings if no survivor field is configured. Note that auto-created records are given the highest priority. |
Merge all records in cluster | If 'Yes': The add-on merges all data in the cluster including records with a score of -1. Their states then become 'Merged'. Note that this property is ignored when executing a 'Run survivorship on clusters' operation. If 'No': The add-on merges data whose matching score against the Golden or Pivot record is higher than or equal to max score. In case of 'Automatic merge', data of Merged (-1) is not merged into Pivot or Golden record. Default value: 'No' |
Default survivor field | Function that will be applied for every attributes of the table (except the primary key that is selected with the 'Survivor record selection mode') to select the value to be survived in the golden record. The default merge function will be overwritten if a survivor field is defined. |
Survivorship function | A function that is applied to the field to select the best value amongst a list of records. These functions take into account any conditions specified in the 'Condition for field value survivorship' property. |
Condition for field value survivorship | The condition is defined as a predicate expression. The Survivorship function will be checked first before moving on to Condition for field value survivorship. A record must satisfy both the Survivorship function and the predicate expression to be survived. If the value of this field is empty or invalid, it will be ignored by the add-on. In case, the predicate expression is invalid, it will be logged in the add-on log file. For example:osd:is-not-null(./AddressLine1) and osd:is-null(./AddressLine2) |
Execute if empty only | Decision on whether to apply survivorship function to merge data to Golden/Pivot record or not based on the field value of the survivorship record. If set to:
|
Table 19: Survivorship policy properties
Survivorship field
Configure field merges.
Survivorship field table (logical name: SurvivorFieldRule).
Properties | Definition |
|---|---|
Survivorship field code | Any naming convention without white spaces can be used. |
Survivorship policy | A reference to the 'Survivorship policy' table. |
Field | A field in the table for which a survivorship function is defined. |
Survivorship function | A function that is applied to the field to select the best value amongst a list of records. For example, in an 'Employee' table, a maximum value function can be applied to the age field to automatically select the greatest age amongst the related suspect records. These functions take into account any conditions specified in the 'Condition for field value survivorship' property. For a list of survivorship functions along with their description, please see Predefined survivorship functions. |
Condition for field value survivorship | The condition is defined as a predicate expression. The Survivorship function will be checked first before moving on to Condition for field value survivorship. A record must satisfy both the Survivorship function and the predicate expression to be survived. If the value of this field is empty or invalid, it will be ignored by the add-on. In case, the predicate expression is invalid, it will be logged in the add-on log file. |
Executed if empty only | Decision on whether to apply survivorship function to merge data to Golden/Pivot record or not based on the field value of the survivorship record. If 'Yes': The survivorship function is executed only if the field value in the survivorship record is empty. If 'No': The survivorship function is executed even if the field value in the survivorship record is not empty. Default value: 'Yes' |
Table 20: Survivorship field properties
Survivorship field function
Survivorship function table (logical name: SurvivorshipFunction).
This table is located under the EBX® Administration Tab in the 'Matching reference data' dataset.
Properties | Definition |
|---|---|
Name | The function's name. |
Description | The function's objective. |
Is prebuilt | If 'Yes': This function is provided by the add-on. If 'No': This function is not provided by the add-on. |
Java class | Specifies a Java reference to provide a custom algorithm. |
Table 21: Survivorship function properties
Special notation: | |
|---|---|
| Currently for survivorship functions, if there are more than one value can be survived, the value of the record with the latest timestamp will be selected by default. |
Predefined survivorship functions
The add-on provides predefined survivorship functions to drive the merge at the field level. When no function is defined, the 'Best score' function is used by default.
Survivorship function | Description |
|---|---|
Best score | The field value used is that of the record with the best score amongst all related suspects. |
Constant | The field value used is set to value defined as constant, whatever merged records values. |
Most trusted source | The field value is taken from the record with the best trusted source amongst all related clusters. If there are two sources with the same priority, the add-on will determine the most trusted based on latest timestamp. If this field is not declared in the 'Field trusted source' table, then the merge for this field is not executed. |
Longest | This field value is taken from the record with the biggest field value size (string). The length of a multi-value field is counted as the number of elements in the list. |
Max | The field value used is the maximum value amongst all related suspects. |
Min | The field value used is the minimum value amongst all related suspects. |
Most frequent | The field value used is the value found most frequently amongst all related suspects. Note that this function ignores the value from an auto-created record. |
Most recently acquired | The field value is taken from the last timestamps record. |
No merge | The field value is not merged |
Table 22: Predefined survivorship functions
Record selection policy
Introduction
A record selection policy defines the method used to select a pivot record for the matching procedure and to select a survivorship record.
Pivot selection
A pivot record selection policy is specified when configuring a matching policy.
By default, the add-on uses the new or updated record as the pivot record for computing the match score. This is called the 'newUpdate' policy.
If a policy other than 'newUpdate' is selected, that policy will be enforced after the 'newUpdate' policy has been applied.
Special notation: | |
|---|---|
| The survivorship will override 'Pivot selection mode'. |
Survivorship record selection
When the survivorship process is started, the add-on has to select the record used as the survivorship, or target record. When the record selection policy is 'newUpdate', all suspects to be merged will be merged into the pivot. If another policy is then executed, the pivot is no longer the survivorship record.
Record selection policy
Record selection (logical name: RecordSelection).
This table is located under the EBX® Administration Tab in the 'Matching reference data' dataset.
Properties | Definition |
|---|---|
Name | The record selection policy name. |
Description | The record selection policy description. |
Is prebuilt | If 'Yes': This record selection policy is provided by the add-on. If 'No': This record selection policy is not provided by the add-on. |
Java class | Specifies a Java reference to provide a custom algorithm. |
Table 23: Record selection properties
Predefined record selection policies
The add-on provides these ready-to-use selection policies. When a record selection policy does not provide any records, then the policy 'newUpdate' is used by default except if another one is mentioned in the table below.
Record selection policy | Description |
|---|---|
Best score | Record with the best score after the pivot record |
Longest | Record with most information (size). All fields (string data type) are taken into account except matching metadata. The length of a multi-value field is the length of longest element in the list. |
Most complete | The record with fewest empty fields. |
Most complete and longest | Record with the fewest empty fields and with the most information (size). All fields are taken into account except matching metadata. Most complete takes priority over the longest. |
Most recently acquired | The record with the latest timestamp managed through the matching metadata tab. |
Most trusted source | The record with most trusted source. |
New update | The record created or modified. |
Was golden | The record is selected amongst 'Was golden' records and current 'Golden'. If many records with the 'Golden' or 'Was golden' identifier exist, the 'Most recently acquired' record is used. |
Table 24: Predefined record selection policies
Trusted sources
A source identifies a system that provides data either at the record or field level.
For instance, in a company, the employee's records are provided either by the human resources system (source 1) or a manufacturing system (source 2). For every record, the salary field can be also provided by the accounting system (source 3). Based on these three sources, it is possible to declare trusted levels such as:
Amongst duplicate records, it is better to select the record stemming from the human resources (source 1) rather than the manufacturing (source 2).
To select the salary field between duplicate records, it is better to use one stemming from the accounting system (source 3) in priority, and then human resources (source 1) and manufacturing (source 2).
The add-on uses the trusted level mechanism in these procedures:
When selecting a record (record selection policy is 'Most trusted source').
When merging a field by the automatic merge (survivorship field policy is 'Most trusted source').
The field stating the source depends on each table under add-on control. The configuration of this field is set in the 'Table' table (logical name: TableConfiguration) through the 'Source' parameter field.
Trusted source configuration
Note
If no specific fields are defined as a trusted source, the add-on applies the trust level set for the table to all of its fields.
Source
Source (logical name: Source).
Properties | Definition |
|---|---|
Name of source | Business source name – any naming convention can be used and the add-on compares this value with a record's source field value. |
Description | Description of the source |
Table 25: Source properties
Table trusted source
Table trusted source table (logical name: TableTrustedSource).
Properties | Definition |
|---|---|
Table | A table under the control of the add-on. |
Trusted source list | List of sources ordered by trust |
Table 26: Table trusted source properties
Field trusted source
Field trusted source table (logical name: FieldTrustedSource).
Properties | Definition |
|---|---|
Table | A table controlled by the add-on. |
Field | A field in the table controlled by the add-on. |
Trusted source list | List of sources ordered by trust |
Table 27: Field trusted source properties
Language management
Each table under add-on control is associated with one of the languages defined in 'ebx.locales' (the languages managed by the EBX®). The matching process uses this language.
The language configuration is declared in the table configuration.
Synonym configuration
The configuration of synonyms is available in the 'Semantic' data domain.
When configuring a matching field policy, you can refer to a group of synonyms used for the de-duplication process. The add-on provides some sample synonyms.
Synonym
A synonym is any phrase that will be considered as another's synonym. The synonym items are synonyms with each other within a group of synonyms (refer to the table 'Synonym group'). To attach synonyms to a group, the data hierarchy view 'Synonym by group' is used.
Source (logical name: Item).
Properties | Definition |
|---|---|
Code | Any naming convention except the prefix '[ON]' that is reserved for the synonyms provided by the add-on can be used. |
Name | The name of the synonym. |
Table 28: Synonym
Synonym group
The synonym items that are synonym with each other are grouped into a Synonym group.
Source (logical name: Synonym group).
Properties | Definition |
|---|---|
Code | Any naming convention except the prefix '[ON]' that is reserved for the synonyms provided by the add-on can be used. |
Name | The name of the synonym group. The 'Synonym by group' data hierarchy view on the 'Synonym' table, is used to attach the items to a group. |
Parent group | Groups of synonyms can be arranged through a parent relationship. At the time you use a synonym group for matching a field, you can configure the matching policy to look for synonyms through the parent relation. |
Table 29: Populate synonym group
Populate synonym group
This table shows the relationships between synonym items and synonym groups. A synonym group may contain many synonym items.
Properties | Definition |
|---|---|
Synonym group | A record of Synonym group table. |
Synonym | A record of Synonym table. |
Table 30: Populate synonym group
Matching operations
In this section, you can find information on matching operations and their contexts for use. Sections are divided into operations that apply to a single record and to those that apply to a set of records.
Operations applied to a single record
List of operations | Type and context of use |
|---|---|
Match cluster | Matching operations applied to a single record are not available if the process policy is incorrectly configured or the 'On matching Process' property is set to 'No'. EBX® standard services remain available from the EBX® view. It is possible to duplicate, compare and delete a record. Because the deletion is physical, it can entail integrity constraint failures. For example, if a merged record holds a foreign key to the record that has been deleted, then EBX® will raise integrity errors. You can make the EBX® delete service inaccessible based on user permission levels. This helps to ensure that a logical deletion with the add-on is always used. Note that if a suspect record is manually removed from a cluster using one of these operations and the cluster contains only pivot and merged records, the pivot becomes golden. |
Match table | |
Match suspicious | |
Create new golden | |
Set golden | |
Set back golden | |
Set definitive golden | |
Unset golden | |
Not suspect | |
Merge | |
Automatic merge | |
Unmerge | |
Switch pivot | |
Remove from cluster | |
Remove and set golden | |
Add into cluster | |
Set merged (ignore) | |
Cancel ignore | |
Delete | |
Undelete | |
Align foreign key of merged record | |
Push out suspect (-1) | |
Display meta-data (also available at the table view ) | UI action applied to single record. |
Manage cluster | |
Show cluster | |
Show cluster for merge | |
Display merged records, Display relation records | |
Display record | |
Hide cluster | |
Modify record | |
Fix relation records (for pivot and golden when under matching) | |
Clean up merged fields log |
Table 31: List of operations applied to single record
On suspicious
Suspicious records are located into the '004' cluster.
Suspicious | |
|---|---|
Match cluster | N/A |
Match table | Matching against all records in the table with unmatched state (in the '000', not in groups), suspect, pivot and golden. Other states that are not used to execute the match include: to be matched, suspicious, definitive golden, merged and deleted. New scores are computed. |
Match best cluster | Matching against Pivot and Golden (with cluster ids > 10). The record will be moved to the cluster that has the best score. The current Pivot or Golden is still prioritized as Pivot and Golden. A Match table operation will be initiated if no Pivot or Golden record matches the record. |
Match suspicious | Simple matching against all records in the table with unmatched state (in the '000' cluster, not in groups), suspect, pivot and golden. Other states that are not used to execute the match include: to be matched, suspicious, definitive golden, merged and deleted. New scores are computed. The suspicious record is then either associated to one to many potential suspect records or directly considered a golden record. |
Create new golden | N/A |
Set golden | Record is declared as golden and moves to the '001' cluster. |
Set back golden | N/A |
Set definitive golden | Same as 'Set golden' but the record moves to the '003' cluster. |
Unset golden | N/A |
Not suspect | N/A |
Merge | N/A |
Automatic merge | N/A |
Unmerge | N/A |
Switch pivot | N/A |
Remove from cluster | N/A |
Remove and set golden | N/A |
Add into cluster | The record becomes a suspect record. It is integrated into a selected cluster along with its merged records and its score is computed against the pivot or golden record. Regardless of the result of this score, the record is kept in the cluster. If there is no pivot or golden record in the selected cluster, then the new record becomes the pivot record. If a pivot already exists, the new record is put into the suspect state. If a golden record already exists, the golden record becomes the pivot record and the new record is put into the suspect state. No automatic merge is executed. It is not possible to add the record into a cluster that is used to group unmatched (to be matched) records.Note that if you move a record other than Merge into a new cluster, its state will be changed to Golden. |
Set merged (ignore) | N/A |
Cancel ignore | N/A |
Delete | Set to deleted and remains in the current cluster. |
Undelete | N/A |
Align foreign key | N/A |
Push out suspect (-1) | N/A |
On suspect
Suspect | |
|---|---|
Match cluster | N/A |
Match table | Matching against all records in the table with unmatched state (in the '000' cluster, not in groups), suspect, pivot and golden. Other states that are not used to execute the match include: to be matched, suspicious, definitive golden, merged and deleted. New scores are computed. |
Match suspicious | N/A |
Create new golden | N/A |
Set golden | The record is declared golden. All other records in the cluster (except merged and deleted) are marked as merged without a merge operation. The score is recomputed for each record in the cluster against the new golden record. Records are kept in the cluster. |
Set back golden | Available only if 'Was golden'= 'Yes'. The record becomes golden and is placed into the '001' cluster without any matching or merging. If the Auto create new golden for single golden property is active, the add-on creates a new golden record and updates the current record to merged. The remaining records in the impacted cluster will be fixed. |
Set definitive golden | Same as 'Set golden' but the record moves to the '003' cluster. The current cluster can have only merged records since the golden record has moved to the '003' cluster. |
Unset golden | N/A |
Not suspect | Record is no longer a suspect against the pivot or golden record. The record becomes unmatched and is moved to the '000' cluster. |
Merge | Record is merged into the pivot using selected fields in the suspect record (selected in the merge UI). One record is merged at a time. No survivorship rules are applied. |
Automatic merge | N/A |
Unmerge | N/A |
Switch pivot | The current record becomes the pivot. The former pivot becomes a suspect record. New scores are recomputed for all records in the cluster against the new pivot. These records are kept in the cluster regardless of the new results (score='-1' is no match). Automatic merge is not executed. |
Remove from cluster | The record is removed from the cluster, set to unmatched, and placed into the '000' cluster. The cluster may have a pivot with no suspects. |
Remove and set golden | The record is removed from the cluster, set to golden, and placed into the '001' cluster. If the Auto create new golden for single golden property is active, the add-on creates a new golden record and updates the current record to merged. The remaining records in the impacted cluster will be fixed. |
Add into cluster | N/A |
Set merged (ignore) | The record is set to a merged state without performing any merge operations. This is one way of rejecting records (ignore). The link to the target record is set to null. |
Cancel ignore | N/A |
Delete | The record is set to deleted and remains in the current cluster with its current score. If there are no remaining Suspects in the cluster, the Pivot becomes Golden. |
Undelete | N/A |
Align foreign key | N/A |
Push out suspect (-1) | N/A |
On pivot
Pivot | |
|---|---|
Match cluster | Matching against suspect records in the cluster. No automatic merge. Suspects are kept in the cluster regardless of the score ('-1' if the minimum threshold to be considered as a suspect). |
Match table | Matching against all records in the table with unmatched state (in the '000' cluster, not in groups), suspect, pivot and golden. Other states that are not used to execute the match include: to be matched, suspicious, definitive golden, merged and deleted. New scores are computed. |
Match suspicious | N/A |
Create new golden | A new pivot record is created if all primary key fields are auto-incremented or done manually from a pop-up. It replaces the existing pivot and the existing pivot becomes a suspect. The Merge view automatically displays. |
Set golden | The record becomes golden. All other records in the cluster (except merged and deleted) are set to merged without any merge. Score is recomputed for each record in the cluster against the new golden record. |
Set back golden | Available only if 'Was golden'= 'Yes'. Record becomes golden and is placed into the '001' cluster without any matching or merging. The pivot then becomes the most recently updated record. New scoring is executed. All existing suspect records are kept in the cluster whatever the score. If the Auto create new golden for single golden property is active, the add-on creates a new golden record and updates the current record to merged. The remaining records in the impacted cluster will be fixed. |
Set definitive golden | Same as 'Set golden' but the record moves to the '003' cluster. The current cluster can have only merged records. |
Unset golden | N/A |
Not suspect | N/A |
Merge | N/A |
Automatic merge | All suspect records in the cluster are merged into the pivot using defined survivorship policies. The record becomes a golden record. |
Unmerge The EBX® Data history function must be active on the table. | Value changes revert to that of the pivot record before its last merge, but only if the last merged record's timestamps are still equal to the pivot record timestamp. If these timestamps differ, unmerging is no longer possible. Merged records become suspect records and the pivot record remains in its state. |
Switch pivot | N/A |
Remove from cluster | N/A |
Remove and set golden | N/A |
Add into cluster | N/A |
Set merged (ignore) | N/A |
Cancel ignore | N/A |
Delete | The record's state is set to deleted, the record remains in the current cluster. The cluster can have no pivot. Every suspect is set to '-1'. If On suspect record retention is activated:
|
Undelete | N/A |
Align foreign key | Realign foreign keys of merged records of the pivot in the dataspace. |
Push out suspect (-1) | All suspect (-1) records of the cluster move to the unmatched cluster. If there are no remaining Suspect record, the Pivot becomes Golden. |
On golden
Located either in non-predefined clusters or in '001' (golden) or '003' (definitive golden).
Golden | |
|---|---|
Match cluster | N/A |
Match table | Matching against all records in the table with unmatched state (in the '000' cluster, not in groups), suspect, pivot and golden. Other states that are not used to execute the match include: to be matched, suspicious, definitive golden, merged and deleted. New scores are computed. If matching does not find a potential duplicate record, the golden record remains in its current cluster. |
Match suspicious | N/A |
Create new golden | N/A |
Set golden | N/A |
Set back golden | N/A |
Set definitive golden | Available only if the record is not in the '003' cluster. The record moves to the '003' cluster. The current cluster (if different from '001') can have only merged records since the golden has moved to the '003' cluster. |
Unset golden | Record becomes pivot. All other merged records in the cluster have 'Target record' field points to the Golden are set to suspect and the target record is set to 'null'. For a golden record in the '001' and '003' clusters, the record moves to the '000' cluster as unmatched. For golden from '003' former merged records are set to suspect with a score set up to '-1'. |
Unset golden recursively | Record becomes pivot. All other merged records in the cluster are set to suspect with scores before being merged. |
Not suspect | N/A |
Merge | N/A |
Automatic merge | N/A |
Unmerge The EBX® Data history function must be active on the table. | Changes the value back to that of the golden record before its last merge, but only if timestamps of the last merged records are still equal to the timestamp of the golden record. If these timestamps differ, unmerging is no longer possible. Merged records become suspect records and the golden record becomes a pivot record. |
Switch pivot | N/A |
Remove from cluster | N/A |
Remove and set golden | N/A |
Add into cluster | Record becomes the new pivot in the cluster, match cluster is executed, all suspects are kept and merge is not executed. Its merged records are also moved to the new cluster without changing states. It is not possible to add the record in a cluster that is used to group unmatched (to be matched) records. Note that if you move a golden record into a new cluster, its state will remain the same. |
Set merged (ignore) | N/A |
Cancel ignore | N/A |
Delete | The record's state is set to deleted and the record remains in the current cluster with its current score. The cluster can have merged records only. |
Undelete | N/A |
Align foreign key | Realigns foreign keys of the merged records in the dataspace. |
Push out suspect (-1) | N/A |
On merged
A merged record is located in a cluster different from reserved clusters ('000' to '010').
Merged | |
|---|---|
Match cluster | N/A |
Match table | N/A |
Match suspicious | N/A |
Create new golden | N/A |
Set golden | N/A (even if Was golden = yes) |
Set back golden | N/A |
Set definitive golden | N/A |
Unset golden | N/A |
Not suspect | N/A |
Merge | N/A |
Automatic merge | N/A |
Unmerge | N/A |
Switch pivot | N/A |
Remove from cluster | N/A |
Remove and set golden | N/A |
Add into cluster | The record is integrated into a selected cluster a long with its merged records without changing states and scores. |
Set merged (ignore) | N/A |
Cancel ignore | Available only if the link to the target record is null. The record becomes a suspect record and remains in the current cluster with its current score. |
Delete | N/A |
Undelete | N/A |
Align foreign key | N/A |
Push out suspect (-1) | N/A |
On unmatched
An unmatched record is located in the '000' (unmatched) predefined cluster or located in a normal cluster through the 'Group at once unmatched' operation.
Unmatched | |
|---|---|
Match cluster | N/A |
Match table | Matching against all records in the table with unmatched state (in the '000' cluster, not in groups), suspect, pivot and golden. Other states that are not used to execute the match include: to be matched, suspicious, definitive golden, merged and deleted. New scores are computed. Depending on the record scores in the table, the unmatched record may move to another cluster, including the '001' cluster if it directly becomes a golden record. Not available for unmatched records that have been grouped by the 'Group at once unmatched' operation. |
Match best cluster | Matching against Pivot and Golden (with cluster ids > 10). The record will be moved to the cluster that has the best score. The current Pivot or Golden is still prioritized as Pivot and Golden. A Match table operation will be initiated if no Pivot or Golden record matches the record. |
Match suspicious | N/A |
Create new golden | N/A |
Set golden | The record becomes golden and moves to the '001' cluster. |
Set back golden | N/A |
Set definitive golden | The record becomes golden and moves to the '003' cluster. |
Unset golden | N/A |
Not suspect | N/A |
Merge | N/A |
Automatic merge | N/A |
Unmerge | N/A |
Switch pivot | N/A |
Remove from cluster | N/A |
Remove and set golden | N/A |
Add into cluster | The record becomes a suspect record. It is integrated into a selected cluster a long with its merged records and its score is computed against the pivot or golden record. Regardless of the result of this score, the record is kept in the cluster. If there is no pivot or golden record in the selected cluster, then the new record becomes the pivot record. If a pivot already exists, the new record is put into the suspect state. If a golden record already exists, the golden record becomes the pivot record and the new record is put into the suspect state. No automatic merge is executed. It is not possible to add the record to a cluster that is used to group unmatched (to be matched) records. Note that if you move a record other than Merge into a new cluster, its state will be changed to Golden. |
Set merged (ignore) | N/A |
Cancel ignore | N/A |
Delete | The record's state is set to deleted; the record remains in the current cluster. |
Undelete | N/A |
Align foreign key | N/A |
Push out suspect (-1) | N/A |
On deleted
A deleted record can be located in any cluster.
Deleted | |
|---|---|
Match cluster | N/A |
Match table | N/A |
Match suspicious | N/A |
Create new golden | N/A |
Unmatch | N/A |
Set golden | N/A |
Set back golden | N/A |
Set definitive golden | N/A |
Unset golden | N/A |
Not suspect | N/A |
Merge | N/A |
Automatic merge | N/A |
Unmerge | N/A |
Switch pivot | N/A |
Remove from cluster | N/A |
Remove and set golden | N/A |
Add into cluster | N/A |
Set merged (ignore) | N/A |
Cancel ignore | N/A |
Delete | N/A |
Undelete | The record is set to unmatched state in the '000' cluster with the score '-1'. |
Align foreign key | N/A |
Push out suspect (-1) | N/A |
On to be matched
A record that is ready to be matched is located in the '002' predefined cluster, or located in a normal cluster through the 'Group at once to be matched' operation.
To be matched | |
|---|---|
Match cluster | N/A |
Match table | Matching against all records in the table with unmatched state (in the '000' cluster, not in groups), suspect, pivot and golden. Other states that are not used to execute the match include: to be matched, suspicious, definitive golden, merged and deleted. New scores are computed. Depending on the scores of the records in the table, the record in the 'To be matched' state may move to another cluster including the '001' cluster if it directly becomes a golden record. Not available for 'To be matched' records that have been grouped by the 'Group at once unmatched' operation. |
Match best cluster | Matching against Pivot and Golden (with cluster ids > 10). The record will be moved to the cluster that has the best score. The current Pivot or Golden is still prioritized as Pivot and Golden. A Match table operation will be initiated if no Pivot or Golden record matches the record. |
Match suspicious | N/A |
Create new golden | N/A |
Unmatch | N/A |
Set golden | N/A |
Set back golden | N/A |
Set definitive golden | N/A |
Unset golden | N/A |
Not suspect | N/A |
Merge | N/A |
Automatic merge | N/A |
Unmerge | N/A |
Switch pivot | N/A |
Remove from cluster | N/A |
Remove and set golden | N/A |
Add into cluster | N/A |
Set merged (ignore) | N/A |
Cancel ignore | N/A |
Delete | The record's state is set to deleted and it remains in the current cluster. |
Undelete | N/A |
Align foreign key | N/A |
Push out suspect (-1) | N/A |
UI operation applied to single record
UI operation applied to single record | Description |
|---|---|
Display metadata | Opens a pop-up window showing record metadata values. This service is also available at the table view level. |
Manage cluster | Opens the cluster with all its records. |
Show cluster | Displays all records contained in the cluster in the bottom window. The bottom window is a cumulative view. One to many clusters can be displayed. |
Show cluster for merge | Displays all records contained in the cluster in the bottom window so that the 'Merge' button is readily available. |
Clean up the list of 'Not suspect with' | Removes all records in the metadata tab's 'not suspect with' property. You can only see this service when at least one record holds the 'not suspect' designation with the current record (except Merged and Deleted). |
Display merged records | Displays all merged records. |
Fix relation records | Allows you to fix the relation records |
Clean up merged field log | Removes all merged field information logged in Metadata. This service is only visible when at least one record merged into the current record (except Merged and Deleted). |
Align foreign key of merged records | Updates foreign key references from Merged records to Pivot or Golden records. This service can be used to align the foreign key of a recursive merged record if the 'Was golden' field value is set to 'True' on the target record. |
Hide cluster | Empties the bottom window. |
Modify record | Opens the record tabular view. |
Display relation records | When a relation match is configured, this service allows you to display the 'Relation table' records. |
Fix relation records
The sections below show how to fix related records and which operations to apply.
Enabling the fixing of relation records
When a table holds the matching metadata type, the 'Fix relation records' service is available. This service allows you to arrange and clean records that are considered 'relation records' to this table across dataspaces and datasets. These records hold a direct or indirect (through a join table) relation to this table.
For instance, a join table 'EmployeeCompany' is used to define the relations between employees and companies. Once the 'Employee' table has been extended with the matching metadata type, the 'Fix relation records' service becomes available in the light and full matching view menu (see below, Stewardship UI).
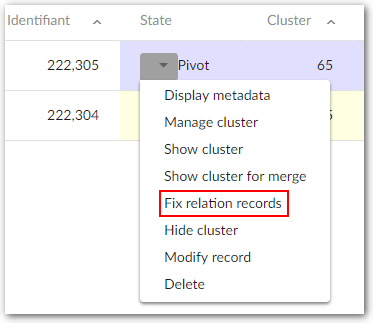
When the table is under the matching process the 'Fix relation records' service is available for records with 'Pivot' and 'Golden' matching states only. The add-on process is then fully applied. When the table is not under the matching process, the 'Fix relation records' service is available for all matching states. In this situation the add-on process is no longer applied.
Operations to fix the relation records
You can apply one of these actions to the "relation record":
'Delete' — Physically removes the "relation record" when the relation table does not have matching metadata. If the relation table has matching metadata, a logical deletion is performed (the "relation record" moves to the 'deleted' state).
'Align' — Forces the "relation record" to link with the parent record. This situation can happen when a add-on operation has collected a set of "relation records" that are not linked to the "parent record".
'Set target' — allows you to select one "relation record" as the pivot record on which a merge process will be applied. The 'Merge relation' button appears if you have selected one record as 'Set target' and at least one other "relation record" exists.
'Reset' - Reverses action applied on the record.
Not suspect with
The 'Not suspect' service is only available for suspect records.
Once this service is executed on a record, the record is no longer considered as a suspect compared to its pivot or golden record. This has an effect not only for the current match procedure, but for future ones as well.
The add-on keeps a list of non-suspect records for each pivot and golden record. The 'Not suspect with' matching metadata is populated automatically by the add-on.
Records can manually be removed from this list. Records must only be added using the 'Not suspect' service.
This is an example of the 'Not suspect' mechanism.

The records 3, 4 and 5 will never be considered as a suspect against record 1 during matching. Record 4 is now a pivot, but was previously a suspect against record 1.
When record 1 subsequently changes states, it maintains its 'Not suspect with' list.
'Not suspect with' lists are not modified when referenced records are modified or logically deleted. When a physical deletion is executed then the list is updated to avoid the risk of breaking integrity.
The score of the record against its 'Not suspect with' record is kept by the add-on so that future scoring can be compared with previous scores. If the difference between a former score and a new score is higher than the 'notSuspectComeBackSuspectThreshold' value (Process Policy) then the record is removed from the 'Not suspect with' list and its state returns to suspect.
Operations applied to a set of records at once
Types of operations
Type and context of use | List of operations |
|---|---|
These operations are not available when a process policy has an incorrect configuration. However, they remain usable when the 'On matching Process' is set to 'No'. | Match at once (suspicious) |
Match at once (to be matched) | |
Match at once (unmatched) | |
Exact match at once (to be matched) | |
Exact match at once (unmatched) | |
Group at once (to be matched) | |
Group at once (unmatched) | |
Group collapse (to be matched) | |
Group collapse (unmatched) | |
Align foreign key of all merged records |
Table 32: List of operations applied to a set of records at once

'Unmatched' records are created either when matching is deactivated for a table through the 'On matching process' parameter in the table configuration, or when the 'Remove from cluster' operation is performed.
'To be matched' records are created when importing bulk data. Then, a policy should be configured with the 'Is import mode' property set to 'Yes'. This allows the add-on to set every imported record to 'To be matched'.
'Suspicious' records are created when the simple matching configuration is used.
Match at once
Four operations are available for launching matches on a set of records at once:
Match at once (on clusters)
Match at once (unmatched)
Match at once (to be matched)
and Match at once (suspicious).
For the 'unmatched' and 'to be matched' records, two execution levels are available:
either on the whole scope of a table for certain states,
or a subset of records collected in 'groups' by the 'group at once' operations.
Special notation: | |
|---|---|
| It is highly recommended to configure a special matching policy to use for the 'Match at once' operation ('For match at once' property in the 'Matching policy' table). If this policy is not configured, then the matching policy will be selected based on the context of records (the field values configured in table 'Matching policy context'), it can entail defect in the matching results. |
In case the 'Record creation matching state' and 'Record modification matching state' indicators of the EBX® Insight Add-on are configured, their automatic execution may affect 'Match at once' performance. | |
Match by states
By default, matching is applied solely on the scope unmatched records (to be matched, unmatched or suspicious depending on the operation).
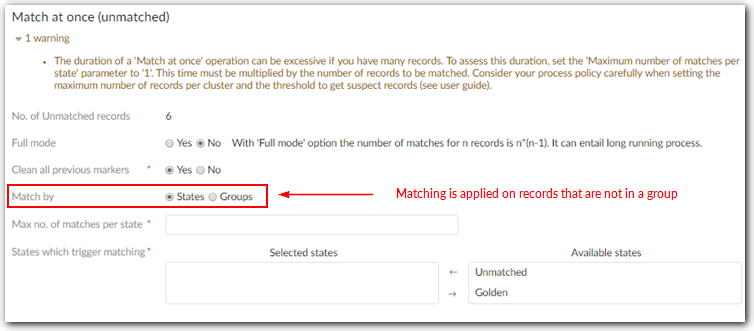
Using a 'base' configuration allows you to define from which record states the 'Match at once' operation is driven. For example, if the base is 'Golden', then golden records are matched against the unmatched (or to be matched, suspicious) records. The order of the selected states is significant since matching is executed for the first state, then the second, etc.
The 'Maximum number of match per state' parameter is used to limit the number of records matched for each state configured in the base. It allows you to avoid executing the 'Match at once' operation on all existing records in the table.
Special notation: | |
|---|---|
| The 'Match at once' operation ignores the records that are located in the groups. |
Example of match at once | List of operations |
|---|---|
Match at once (unmatched) with base = golden, unmatched | All golden records are matched against all unmatched records. Once this match is terminated, the rest of the unmatched records are matched with each other. |
Match at once (unmatched) with base = golden | Same as the previous example but the rest of unmatched records are no longer matched. |
Match at once (unmatched) | All unmatched records are matched with each other. |
Table 33: Examples of match at once operations
Special notation: | |
|---|---|
| The 'Match at once' operations handle the records to be matched as a stack of records. In other words, a record is matched only one time during the whole process. |
| To streamline the process of the 'Match at once' operation, it is recommended to:
|
Match by groups
It is possible to execute the 'Match at once' operation on a subset of unmatched records (or to be matched) that have been collected by the 'Group at once' operations.
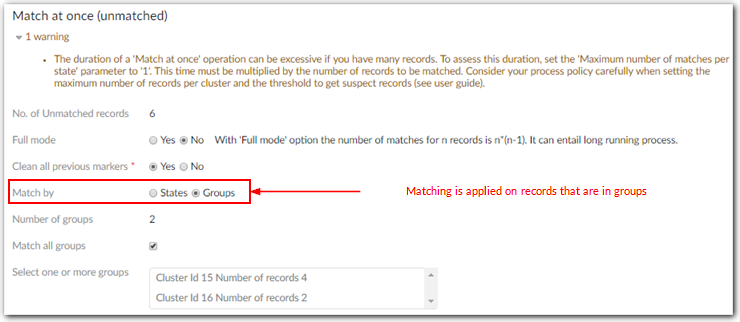
Special notation: | |
|---|---|
| The match by groups option is available if there are existing groups (see the 'Group at once' operation to create groups of records). |
When a large set of records must be matched, it is recommended to apply a rough matching policy to create groups. This requires a shorter execution response time. For example, using an Exact algorithm on a 'postal code' field to group customers by department. After that, the 'Match at once' operation is executed on the groups as explained above.
Special notation: | |
|---|---|
| Parallel matching on several groups. |
Match at once (on clusters)
You can execute the 'Match at once' operation on a single cluster or a set of clusters. Only clusters that have a ClusterID greater than 11 and do not contain a golden record display in the list of clusters.
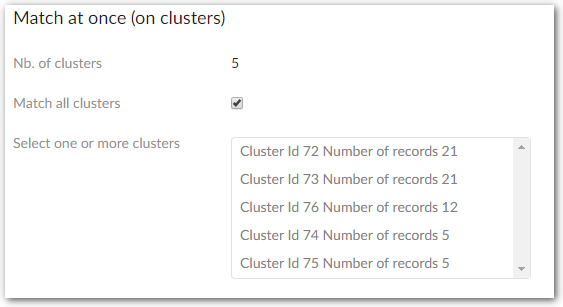
Special notation: | |
|---|---|
| Matching policy for 'Match at once' is not applied when executing 'Match at once (on clusters)'. |
Match with the 'Full mode' option
When you execute the 'Match at once' service and enable the 'Full mode' option, a match is run against every record in the table, regardless of any existing 'Match at once' configuration settings. This means that any property values which make up a "base" configuration are ignored. The number of matches executed is n*(n-1) for n involved records. This improves matching result relevance, but increases execution time.
In 'Full mode', the 'Force orphans golden' option is active as default. In this mode, all lone suspect or lone pivot records in a cluster are forced to golden.
When this option is not active, a record is matched only if its state value is within the 'Match at once' base configuration's parameters.
Using match at once without the 'Full mode' option | |
|---|---|
First step of the service A, Unmatched B, Unmatched C, Unmatched D, Unmatched | Match at once on A. The A record is a pivot and matched with B, C, and D. If a record becomes Suspect it is no longer used for the match. This is considered a "stack mechanism" to facilitate rapid matching. Applying an additional match on a Suspect record could entail new duplicates that are ignored in the current 'Match at once' operation. |
Second step of the service (executed automatically) A, Pivot B, Suspect C, Unmatched D, Unmatched | The next match is done on C. The B record is not used to launch a match. This stack process streamlines the response time and results in a fast matching process. |
Using match at once with the 'Full mode' option | |
|---|---|
First step of the service A, Unmatched B, Unmatched C, Unmatched D, Unmatched | Match at once on A. In 'Match at once' with the 'Full mode' option enabled all records in the table are matched one time and only one time, even if they are suspect, pivot or golden. The base configuration is not used. |
Second step of the service (executed automatically) A, Pivot B, Suspect C, Unmatched D, Unmatched | Next match is done on B by applying the service 'Match table' on the suspect. |
Special notation: | |
|---|---|
| The 'Unmatched' records created during match at once with 'Full mode' option are matched against other records in the new cluster. |
Match at once in 'Parallel mode'
When you activate Parallel mode, the add-on divides records into groups and executes matching on these groups simultaneously. This method can reduce matching response time. The options when running Match at once in parallel mode are defined in 'Process policy' table's 'Options for Parallel Match at once' tab. Please refers to Process policy section for more details. Note that the Parallel mode is hidden when replication is activated (only in commit mode).
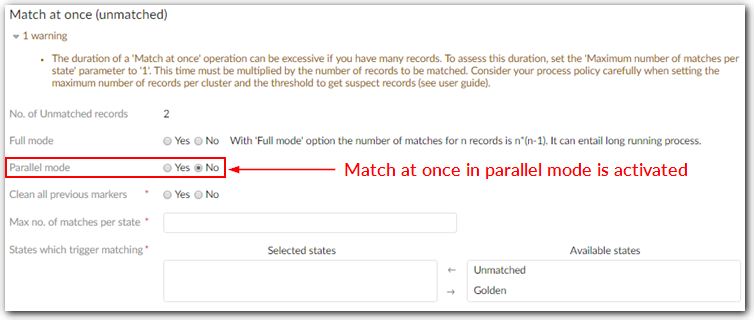
Note
The parallel matching option does not display on a historized table, or an existing replication table on submit mode.
Special notation: | |
|---|---|
| Match at once parallel does not work on a historized table or a table which is configured a 'On submit' mode replication. |
| Parallel matching is in beta mode, it is highly recommended that you work on a working dataspace instead of real data. |
Follow the result of a match at once execution
The 'Clean all previous markers' parameter is used to retrieve records that have been handled by the match at once execution.

When a record's state is modified during a 'match at once' operation, the add-on flags it. Then, it is possible to get the list of all records impacted by match at once operation execution(State button).
A record is considered as stemming from a 'match at once' operation until it is modified by any other operations or if the 'Clean all previous makers' option is set to 'Yes' when executing a 'match at once' operation (figure below).

Response time
When a table contains a large set of records, it is recommended to apply an incremental matching procedure (see Incremental matching procedure section). The following table describes three properties that have an impact on a match at once operation's response time.
Property | Description |
|---|---|
Max number of records in cluster (Table configuration) | When a set of records contains many suspect records, setting the 'Max number of records in cluster' property to a higher value improves response time. When the 'Max number of records in cluster' property is set lower and the 'Maximum number of match table for each state' is higher, a match operation creates more clusters containing fewer records. |
Stewardship min score (Process policy) | The lower this threshold is, the faster the match at once operation will be. The pace of feeding clusters depends on the ability to make a record suspect as quick as possible. If this threshold is too high it means that likelihood of a record to be a suspect is lower. This configuration can raise many matches of the same record against many other records in the table because of a lack of suspect detection. |
Maximum number of match table for each state ('Match at once' operation) | The match at once operation is executed as many times as records are available to match. When an unbounded value is used for this property, it means that all records in the table will be impacted by the operation. |
Table 34: Properties having an impact on the response time of match at once operations
This table gives some examples of possible response times for the match at once operation. The assumptions are as follows:
100,000 records are set to unmatched.
Execution of the 'match at once unmatched' operation.
Match on one field.
Note: obviously the response time depends on the quality of the execution platform as well. For this reason the following table remains just an example.
Property | Example |
|---|---|
Max number of records in cluster=5 Stewardship min score=15% Maximum number of match table for each state=10 | Quick match to get an idea for response time on a limited matching coverage Result in: 5 seconds |
Max number of records in cluster=5 Stewardship min score=15% Maximum number of match table for each state=100 | Higher number of records to match. The response time should be about 10 times the previous one Result in: 40 seconds |
Max number of records in cluster=5 Stewardship min score=15% Maximum number of match table for each state=10,000 | For 10,000 records it should take about one hour (40 seconds * 100) |
Max number of records in cluster=50 Stewardship min score=15% Maximum number of match table for each state=100 | With the 'Max. number of records' property set to a higher number, suspect record collection time improves. Example: 3 minutes |
Max number of records in cluster=50 Stewardship min score=15% Maximum number of match table for each state=10,000 | The same configuration as the previous one but applied to 10,000 records should take about 5 hours (3 minutes * 100) |
Table 35: Example of possible response time for a table with 100,000 records
Incremental matching procedure
Because there are many parameters that influence the 'Match at once' service execution time (see Response time section), it is recommended to run matching on successive subsets of records. This is achieved on all records directly in the table, or by creating groups of records (operations Group at once).
No use of groups of records
The following table shows an example for the execution of a 'match at once' operation applied on a set of 400,000 records.
Records | Matching Execution |
|---|---|
| Matching stage #1 All table records are set to 'unmatched' when importing data for the first time. On this table, a 'match at once (unmatched)' operation is executed with a limit of records set to 100,000. The stewardship for these records is then applied. Some of these records move to merged and can be deleted. Other are set to golden, pivot and suspects. |
| A second 'match at once (unmatched)' operation is executed on the next 100,000 records. Only records with an unmatched state are used, meaning that all records that have been analyzed during the first matching execution are ignored. |
| Matching stage #2 After the execution of four 'match at once (unmatched)' operations by sets of 100,000 records, there are 150,000 records holding merged and deleted states. To execute a second matching stage, all other records must be set to 'unmatched' (see the 'set at once' service). When applied to the 250,000 remaining records, the second matching execution stage is performed. The 'match at once (unmatched)' operation is directly executed on the scope of all 250,000 records, or on a smaller set depending on the matching strategy. |



Table 36: Example of an incremental matching procedure
Use of groups of records
Rather than matching 100,000 records directly (see No use of groups of records section) with a fine grained matching policy, it is recommended to first apply a rough matching policy that groups all unmatched (or to be matched) records without changing their states. This rough policy can rely on the fastest matching procedure such as an Exact algorithm with one field only.
Once groups are created, then the match at once operation can be executed on every group to keep the response time to a minimum.
To create a group the 'Group at once' operations are available to apply to 'unmatched' or 'to be matched' records (see next section).
Synthesis of possible approaches to match large volumes of data
Different types of match
The same process can be applied to 'to be matched' and 'Suspicious'.
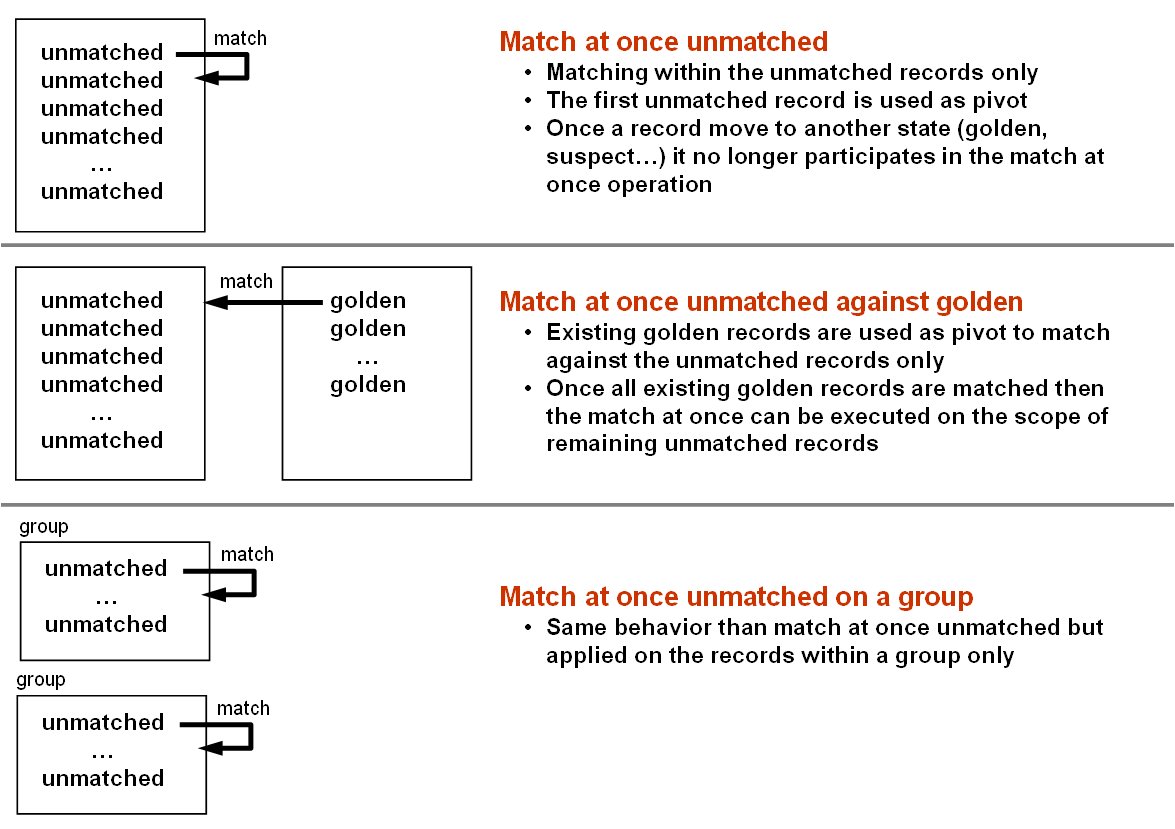
The whole process of matching large set of data
The same process can be applied to 'to be matched' and 'Suspicious'.
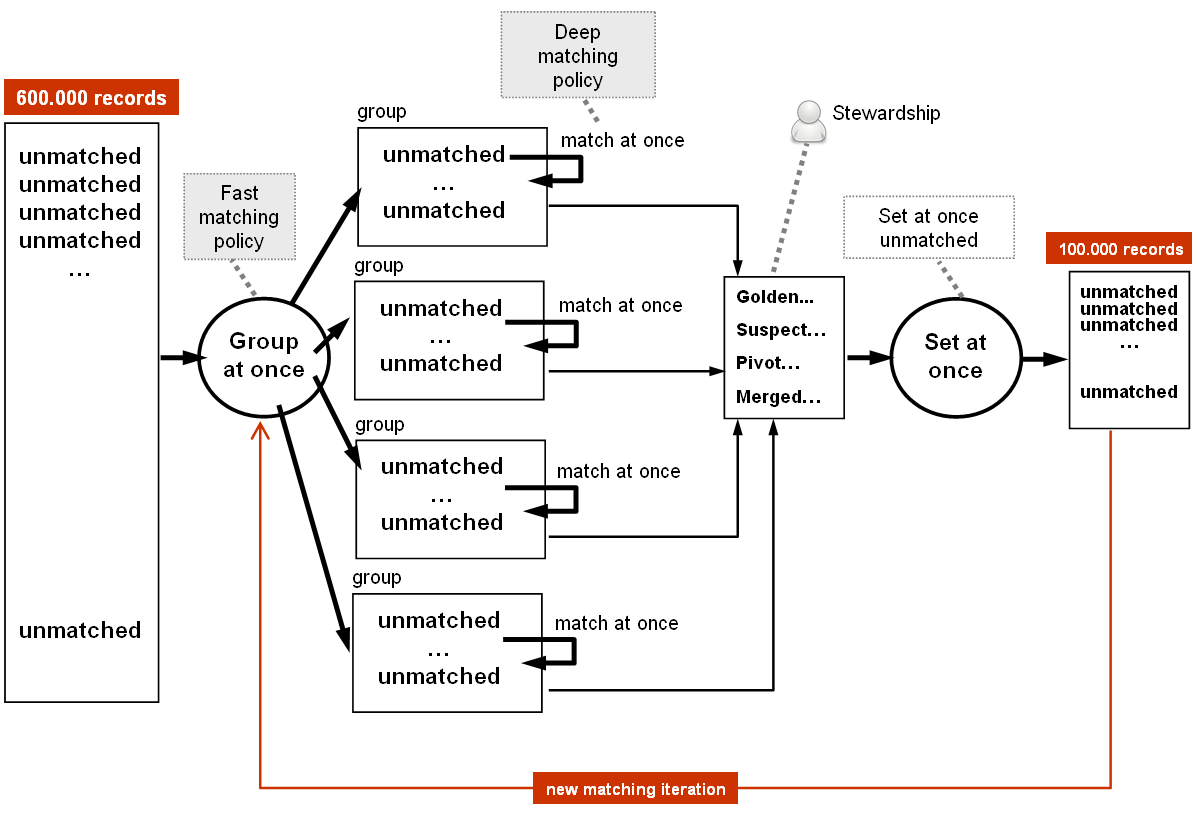
Special notation: | |
|---|---|
| When you are dealing with a large volume of data, it is also possible to use the 'Exact match at once' operation to apply a direct data query in order to get groups of records based on exact data values (see Exact match at once section). |
| You can filter data at the time the matching policy is executed. Fuzzy matching is then applied to the subset of records retrieved through the filter. Please see the 'Filter by' property. |
Exact match at once
The 'Exact match at once' operation is executed on 'To be matched' or 'Unmatched' records.
This operation applies a full 'exact' matching based on the matching fields that are configured in the active matching policy. This means that the algorithms configured in the matching policies are bypassed to apply an exact matching.
Similar to the 'Exact' algorithm in the matching field configuration, the 'Exact match at once' operation, runs a direct data query that is not based on a fuzzy algorithm. Therefore the response time is dramatically improved but the matching results cannot be mixed with a fuzzy search. When many fields are configured to use matching then the 'Exact match at once' operation computes the record's score by using a direct 'and' operator.
The 'Exact match at once' operation creates clusters of records that match.
The records used to match come from the cluster reserved for the 'To be matched' records (or 'Unmatched') and the records that are pivot, suspect and golden. In other words, 'To be matched' and 'Unmatched' records that are already grouped are not used. The suspicious records are not used.

The 'In memory' option forces the execution of the matching in a full memory mode for which all data is managed within a unique transaction. It improves the response time dramatically (more than ten times faster) but requires more memory use. This option is strongly recommended for large volume of data with million of records.
At the end of the execution, you can still have 'To be matched' or 'Unmatched' records when they have empty values for the exact matching fields or they are located already in existing groups.
Special notation: | |
|---|---|
| 'Exact match at once' is a fast matching operation that can be used on large set of records to easily create initial clusters of records that share exact values on certain fields. |
| The 'Exact match at once' operation does not work in conjunction with the 'Relation match' operation. With a direct foreign key relationship, the exact match is applied using the foreign key raw value not its label. |
| Even if a matching policy includes a 'Filter by' configuration, the 'Exact match at once' operation ignores it. This is because 'Exact match at once' already behaves as a filter. |
| The 'Exact match at once' operation does not support matching on multi-valued fields. |
Group at once
The 'Group at once unmatched' operation ('to be matched') allows you to group unmatched or 'to be matched' records. Contrary to matching execution, records that are grouped do not move to another state such as golden, pivot or suspect. They keep their states unmatched (to be matched).
Special notation: | |
|---|---|
| The maximum number of records in a group is defined by the 'Max number of records for group' property in the 'Table' configuration. It is recommended that this property is configured to maintain manageable groups sizes that depend on the context of use. For example, to have a chance to group 100,000 records in a minimum of 100 groups, the 'Max number of records for group' property must be set to '1,000'. |
Groups creation
It is possible to configure a special matching policy for group at once execution ('For group at once' property in the Matching policy table). If this policy is not configured, then the default is used.
Most of the time, the group at once operation is used to create groups of records on which a further execution of the match at once operation will be applied. Then, the groups can be created from a rough matching policy (Exact algorithm, one matching field) that will streamline the execution response time.
The group at once operation takes into consideration all unmatched records (to be matched) in the table, whatever their cluster localization ('000' for unmatched, '002' for to be matched), including records already grouped. In other words, the execution of the group at once operation reshapes the existing groups for unmatched or to be matched.
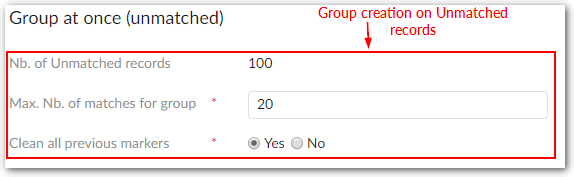
The 'Maximum number of matches for group' property allows you to limit group at once operation match execution.
Groups collapse
It is possible to collapse a group by using the 'Group collapse (unmatched)' operation (to be matched). Then, all group records move to the reserved cluster '000' (unmatched) or '002' (to be matched) and the group dissolves.
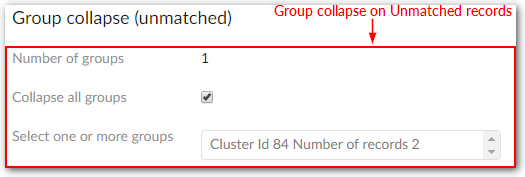
Note: the number of records in a group is computed at the time of group creation. In order to keep the original information about the group size, it is not updated after the creation.
Follow the result of a group at once execution
The 'Clean all previous markers' parameter is used to retrieve records that have been handled by the match at once execution.
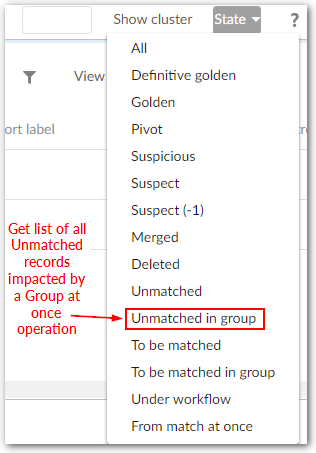
When a record is grouped during a 'group at once' operation, the add-on flags it. This allows you to retrieve a list of all records impacted by a group at once operation (button State, operations 'Unmatched in group' and 'To be matched in group').
A record is considered as stemming from a 'group at once' operation until it is modified by any other operation, or if the 'Clean all previous markers' option is set to 'Yes' when executing a 'group at once' operation (figure below). Then, a special indicator displays as highlighted below.
Align foreign keys of all merged records
Any record that still has a relationship with another record after it has been merged has an integrity issue. Since merged records still remain in their tables, built-in validation performed by EBX® cannot be used to resolve this issue.
The EBX® Match and Merge Add-on provides two services to realign foreign keys:
'Align foreign key of merged record' applied to a golden or pivot record uses all merged records related to the pivot or golden record to realign (see Operations applied to single record section).
'Align foreign key of all merged records' applied to a table uses all merged records in the table to realign.
These services check every foreign key in relation to the table managed by the add-on, including ones in the table on which the service is executed (in case of self-referencing relationships). The scope of these services includes all related dataspaces and datasets.
When a foreign key is linked to a merged record, the add-on automatically updates it with the correct target record in the appropriate dataspace and dataset. To achieve this process, the service relies on the matching metadata to keep track of the target record for each merged record. Note that the setting of a table's Relationship management property can affect this behavior as follows:
When the property is set to None, no action is taken.
When the property is set to Manual, alignment follows the selections in the Merge view.
To verify whether the orphan relationships have been fully repaired in a repository, all obsolete merged records must be purged. Once these records are no longer physically present in the tables, built-in validation performed by EBX® can be relied upon to identify remaining orphan relationships.
As the 'Align foreign key' services can no longer be used once merged records have been purged, you can employ a child dataspace for EBX® validation checking. In the child dataspace, it is then possible to purge the merged records in isolation and correct any validation errors reported by EBX®. Once the results have been validated in the child dataspace, the corrections alone can be merged back into the parent dataspace, thereby leaving merged records untouched in the parent dataspace allowing 'Align foreign key' to be run again in the future.
Logical deletion of records
The add-on relies on a logical deletion of records (deleted state). From the add-on's point of view, it is better to keep the record deleted until a definitive decision for its physical deletion is made. At any time, a deleted record can be reset to unmatched if needed (undelete).
When a record moves to the deleted state, integrity is a concern if other records hold a link to this record. Since the record is not yet physically deleted, the EBX® validation procedure does not raise errors.
To enable EBX® to enforce the validation you need to physically remove all records with the deleted state. This can be achieved either by using the usual EBX® 'delete' service, or by executing the 'Purge at once (deleted)' operation supplied by the add-on.
Running survivorship on all clusters
From the Table services menu, you can execute the Run survivorship on clusters service to run survivorship on selected clusters. Only clusters that have pivot, golden and merged records will be taken into account. When you run this service, the add-on executes survivorship to merge data from merged records to golden, or pivot records.
Running a match from a table
You can execute a match from a table's Actions menu by selecting the Run match service. This service allows you to select one or more records to include in a matching operation. If you run the service without making any selections, matching runs on the entire table.
When you run the service and:
a single record is selected, the add-on executes a match against the selected record and immediately displays the (Light) Data quality stewardship view.
multiple records are selected, the add-on displays the Run match screen where you can specify how you want the match to execute. The match executes only on the selected records and the add-on redirects you to the (Full) Data quality stewardship view.
no records are selected, the Run match screen displays and you can choose how you want the match to run. When you run the match, it executes on the entire table. Once the matching process completes, the add-on opens the (Full) Data quality stewardship view.
In the Run match screen, the Active selection field shows the number of currently selected records. You can use the Record to match against field to define which records the add-on will process against the active selection. The Specific states option allows you to select from available states. The matching operation then runs on records with the selected state. When you choose the Active selection option, the match runs only actively selected records (against each other). The Max no. of selected records property limits the number of records from the active selection that will be processed.
The following image shows the Run match screen:
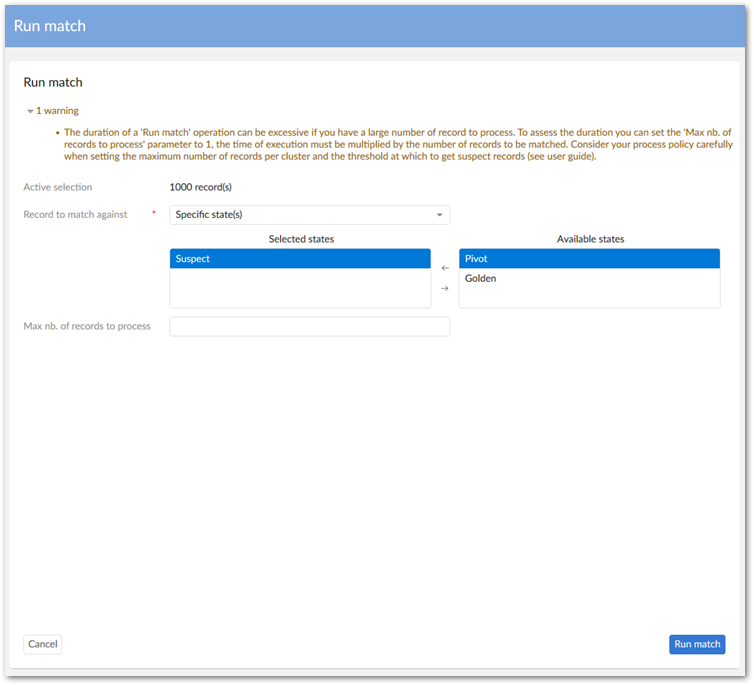
Setting record state
The add-on allows you to set the matching state for records as follows:
When in the Data quality stewardship screen, you can set all records in a table using the Set at once service options.

When viewing a table, you can select records and use the Set state service. Note that if you do not select any records, the service applies to all records in the table.
