Understanding matching operation processing
Overview
The add-on and the EBX® core share responsibility for matching process execution. The core product pre-processes the list of records to match to find similar records and passes them to the add-on. EBX® finds similar records by taking the base record, or record to match against other records, and applying certain parameter settings.
If a field configured to participate in matching meets either of the following criteria, it is automatically disabled during the pre-processing phase to improve performance:
The field's type is
boolean.The entire column is
null.
When input consists of a selection of records, the output is a group of similar records. If the input is an entire table, additional processing is performed and the output is pairs of similar records. The add-on processes the output from EBX® using the logic defined in a matching policy's decision tree to determine whether values match. The diagram below visualizes this process:
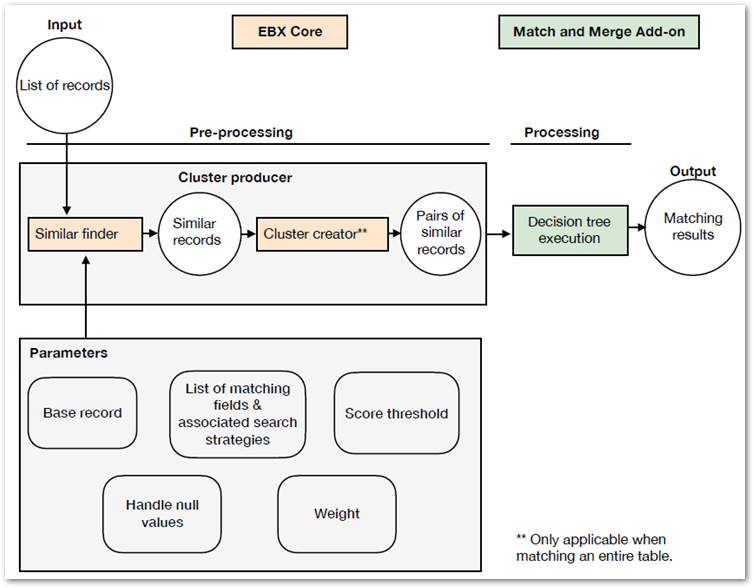
Pre-processing and cluster generation
To ensure high performance and scalability, not every record is compared against all other records. Instead, a pre-processing phase (clustering) creates candidate clusters for matching.
Purpose and principles
Clustering acts as a coarse filter. The goal is to reduce how often the add-on's decision tree logic runs. It does this by grouping only likely matches into clusters and filtering out obviously unrelated records. The logic is also tuned to keep false negatives (missed matches) to a minimum.
How similarity is determined
During pre-processing, EBX® iterates over the records to match and uses a full-text search to find similar records. Generally, every matching field configured in the matching policy acts as a criterion for similarity, where the system breaks down field values into searchable terms (or keywords). To be considered similar and compared within the decision tree, a record pair typically needs to satisfy a minimum threshold—for example, sharing at least 1 significant term out of 3.
Defining criteria and exclusions
Not all fields make good similarity criteria. Fields with low cardinality (few unique values) or very common values can create massive, inefficient clusters. You must manually exclude fields that are not unique enough to identify candidates (e.g., a "Country" field where 90% of customers are in "US", or a "Gender" field). To manually exclude a field, set the Weight to 0 in the matching policy's Matching fields tab. This ensures the field is used for scoring in the decision tree but not for picking candidate records during clustering.
The system also applies automatic exclusion. Fields defined as Boolean (e.g., IsActive) are automatically disabled during the pre-processing phase to improve performance. If an entire column is null, it is also automatically excluded.
Finally, specific common words (stopwords) must be filtered out to prevent irrelevant matches. Without this, records sharing generic terms like "Inc." or "LLC" might be identified as similar even if they are completely unrelated. This also applies to single-letter keywords often found in composed names (e.g. “George R.R. Martin”), unless filtered, the letter “R” could trigger matches with any other name containing that initial.
Balancing field weights
By default, all matching fields are assigned a weight of 1. Keep the default value unless you notice quality issues in your matching results. Only adjust weights if specific fields need to be prioritized to improve the relevance of the clusters. As mentioned above, set the weight to 0 only when you want to exclude a field from pre-processing.
When adjustments are necessary, assigning appropriate weights becomes crucial for the coarse filter to work effectively. You should only give higher weights to fields that are highly distinctive (like a Tax ID or Email) and lower weights to fields that are less specific or prone to errors (like First Name).
Example: optimizing similarity criteria
Consider a matching policy for Corporate Customers that uses the following fields: Company Name, City, Region, and IsActive.
Field | Example value | Clustering behavior | Configuration note |
|---|---|---|---|
IsActive | True | Ignored | Automatic, no configuration required. Boolean fields are never used to find similar records. |
Region | North-East | Ignored | Manual configuration is required. Because "North-East" is too generic and would cluster too many unrelated records, an administrator must set the Weight of the matching field to 0. |
City | Chicago | Used | Used as a similarity criterion. Records sharing "Chicago" are candidates. |
Company name | Acme Inc. | Used, but optimized | Used as a similarity criterion. Records sharing "Acme" are candidates. Stopword: The term "Inc." is configured as a stopword and ignored to prevent matching with each occurrence of "Inc." in the column. |
In the above example, records are picked as "similar" candidates only if they share a meaningful term (e.g. "Chicago" or "Acme") in the City or Company Name fields. System resources are not wasted comparing records just because they are active (True), or in the "North-East".
Performance tip: Selecting the right fields for clustering is critical. For detailed instructions on tuning these settings to avoid bottlenecks, refer to the Performance recommendations section to optimize performance.
Adjusting parameter settings
Adjusting parameter settings changes the criteria used by EBX® to find similar records. As a result, the output records passed to the add-on for processing can change. Fine-tune the settings to obtain desired results. However, keep in mind that it is wise to find a balance between the trade-off of restrictive settings vs nonrestrictive. Criteria that is too strict can result in not passing records to the add-on that a decision tree would consider a match.
To edit parameter settings:
Access the configuration settings for the matching field you want to update:
Navigate to Administration > TIBCO EBX® Match and Merge Add-on > Table activation and settings.
Open the table configuration and matching policy containing the field.
Select the Matching fields tab and open the field.
Use the following options under Pre-processing to change parameter settings:
Search strategy: Sets the search strategy used to group similar records during the pre-clustering process. The list only includes search strategies defined in the data model containing the selected field. See the EBX® Reference Manual for more information about search strategies.
Weight: Specifies the weight assigned to this field during pre-processing by EBX®. When a matching operation includes multiple fields, the weight sets the relative importance of each field's score in determining whether records are similar. Note that this weight does not affect the weighted average in the decision tree comparison nodes.
See the information above on balancing field weights.
Null value management: Determines the behavior when comparing two records and one or both of them has a Null value in this field. When enabling matching of null values, adjust the weight for the field so that it is lower as compared to other fields. Otherwise, it might not get included during pre-processing with other similar records. Using the Do nothing option when your dataset contains many null values can help performance and result relevancy. This option ignores null values and prevents records that are not similar, except for their null values, from being considered similar. Essentially, it helps prevent false positives from passing to the decision tree for unnecessary evaluation.
Save and close to keep your changes.
Pre-processing optimizations reduce cluster size
Where possible the pre-processing phase automatically reduces the cluster size to optimize performance. During this phase, the decision tree is analyzed as follows:
The system identifies any fields determined as "mandatory". These are fields whose similarity is required to consider records as matches or suspects. Any records without similarity in these fields are excluded from further processing, which can significantly improve performance by reducing the number of candidate records. For example, the Customer_Email field is considered as mandatory in a decision tree where the field is included in all paths that lead to a MATCH or SUSPECT output. In this case, records that do not have the same email address will never be considered as candidates, and are not passed to the decision tree for evaluation.
Currently, this behavior only applies to data comparison nodes that use the All fields match evaluation and the following algorithms: Exact, or Full text with a minimum score of 100%.
The system analyses each decision tree path that leads to a MATCH or SUSPECT output to identify groups of fields where similarity is essential for records to match. A minimum required score is computed from the smallest group of fields. Records must meet, or exceed this score. Otherwise, they are not passed to the decision tree for evaluation. Take for instance, a decision tree with five fields configured with the same weight, and at least three of the fields must be similar for records to match. In this case, the minimum similarity score is 60% to pass candidate records to the decision tree.