Normalize
Converts a string into a normalized form, which includes any or all of these:
-
Converting the entire string to upper or lower case
-
Removing extra spacing
-
Removing any non-alphanumeric characters, etc.
-
Removing any titles, such as ‘Mr.’, ‘Mrs.’, ‘Dr.’, etc.
This rule is handy for CAQH as well as other types of normalization as defined in the Phase II CORE 258 rule.
Format of Parameters
SourceString ResultVar CommandString
Where:
SourceString
|
The string to be converted. This can be a literal in double quotes, a system variable like Current_Element or Current_Date, or a variable name. |
ResultVar
|
The variable to contain the result. |
CommandString
|
A string (variable or literal) containing one or more of the normalization operations, each separated by a comma, as described in CommandString Details below. These will be performed on SourceString, in the order you specify, so the results may differ if the options are in a different order. |
CommandString Details
This can be one of the following:
|
Option |
Result |
|---|---|
|
LC |
Convert all upper case letters to lower case. |
|
UC |
Convert all lower case letters to upper case |
|
TRIMlimits |
Trim all leading and trailing spaces, and replacing any embedded sequences of two or more spaces with a single space. To limit the range of TRIM, append one or more of the following limits:
Examples
The order of the suffix codes do not matter. TRIMLT is the same as TRIMTL. Finally, TRIM with no suffix codes is the same as TRIMLTM. |
|
RC:NonX12B |
Remove all characters not in the X12 basic character set. This character set includes: Uppercase letters Decimal digits Punctuation Characters ! " & ' ( ) * + , - . / : ; |
|
RC:NonX12E |
Remove all characters not in the X12 extended character set. This character set includes: Uppercase letters Lowercase letters Decimal digits Punctuation Characters ! " & ' ( ) * + , - . / |
|
|
Remove all characters not in the EDIFACT UNOA character set. This character set includes: Uppercase letters Decimal digits Punctuation Characters |
|
|
Remove all characters not in the EDIFACT UNOB character set. This character set includes: Uppercase letters Lowercase letters Decimal digits Punctuation Characters . , - ( ) / = ' + : ? |
|
|
Remove all characters that are not alphanumeric (not an uppercase or lowercase letter or a digit) |
|
|
Remove all control characters that have an ASCII value of 1 through 31 |
|
|
Remove all control characters that have an ASCII value of 128 through 255 |
|
|
Remove all control characters that have an ASCII value of 1 through 31 or 128 through 255 |
|
|
Remove all characters listed in ccc. Example To remove a single quote character, use two consecutive single quotes in the ‘ccc’ string. Example
|
|
RW:CAQH |
Removes all occurrences of the following titles from the front and/or end of SourceString, as specified in section 4.2.2 of the CAQH CORE document: JR SR I II III IV V RN MD MR MS DR MRS PHD REV ESQ |
|
|
Removes all occurrences of the words specified by w1, w2 …. w1 w2 … is a list of words, with each word separated by a space. Letter case is not significant. Words will be removed if they are found at the beginning or end of SourceString, and separated from the rest of the string by a space, comma, or forward slash character. If any word is immediately followed by a period, the period will also be removed. To include a single quote character in a word, use two consecutive single quotes in the ‘w1 w2 …’ string. |
Examples
The character ‘·’ in these examples represents a space
Example 1
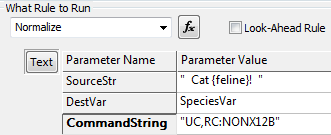
This puts ··CAT··FELINE!··
-
UC -
RC:NONX12B
Example 2
Assume that the current element contains Dr. Fred Schultz
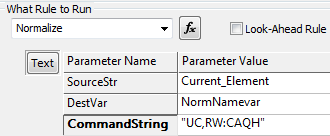
This puts FRED SHULTZ
-
UC -
RW:CAQH
Example 3
This shows how the sequence of operations can affect the result.
Assume that variable VarDat contains This·is·a·Test!·· .
Normalize NormResult1var "UC,RC:NONX12B"
Normalize NormResult2var "RC:NONX12B,UC"
The first rule causes THIS·IS·A·TEST!·· to be put into variable NormResult
-
UC converts to upper case.
-
RC:NONX12B removes all characters not in the Basic X12 character set.
However, the second rule causes T···T!·· to be put into variable NormResult
-
RC:NONX12B remove all characters not in the Basic X12 character set.
-
UC converts to upper case.
-
Since lower case letters are not in the X12 Basic Character Set, they all get removed.
Example 4
Assume that the current element contains Rev. Raymond A. Ratchet, Esq, PhD
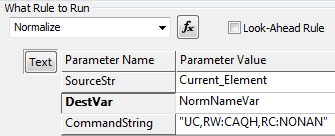
This causes RAYMOND A RATCHET
-
UC -
RW:CAQH -
RC:NONAN
Example 5
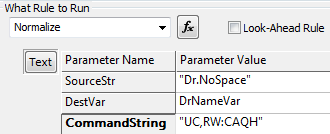
This causes DR.NOSPACE
-
UC converts to upper case.
-
RW:CAQH removes all prefixes and suffixes in the CAQH title list. However, there is no space, comma, or forward slash between the DR. and the rest of the string so it isn’t removed.