GP Parser-Based Data Models
The data models in LogLogic LMI can be broadly classified into the following categories:
- Advanced Data Models, which use parser types such as syslog, Regex, JSON, and so on.
- GP Parser-Based Data Models, which are data models that use a grouped-pattern parser (GP parser). GP parsers are especially efficient in handling complex Regex parsing rules that work on heterogeneous free-text logs.
GP parsers are very different in structure and syntax from the advanced data model parsers. The parsing rules in a GP parser use Regex patterns, and it is recommended that you have preliminary knowledge of Regex patterns. GP parsing rules have been designed to handle a large set of such complex rules. You cannot create a new data model or edit a built-in data model that uses the GP parser. However, you can duplicate a built-in data model, and then edit its parsing rules as required.
Usage: GP parser-based data models
Sometimes, if the format or pattern of the logs received in LogLogic LMI are slightly different than expected, then the logs are not parsed with the parsing rules defined in the built-in data model. Before LogLogic LMI version 6.4.0, you could not identify which parsing rules failed to match, or which rules were the closest match for such logs, or to edit the parsing rules expressions to accommodate the parsing of the changed log format.
Starting version 6.4.0, you can:
- View a graphical representation of the entire node tree of parsing rules.
- Identify or filter out rules sharing a given node.
- Validate a sample log event against the built-in parsing rules and inspect the graphical view to identify at which node the parsing failed, or the closest matching rule that you might need to tweak.
- Edit the rule expression as required, and save the modified rule or save it as a new rule. See Editing GP Parser-Based Data Models.
- To edit parsing rules of advanced data models, see Editing Parsing Rules in Advanced Data Models.
- For a list of parsers in advanced data models, see Types of Parsers in Advanced Data Models.
List and Graphical Views of GP Parsing Rules
GP parsing rules are displayed as a list on the Rule list tab and as a node tree on the Node tree tab.
- Rule list tab
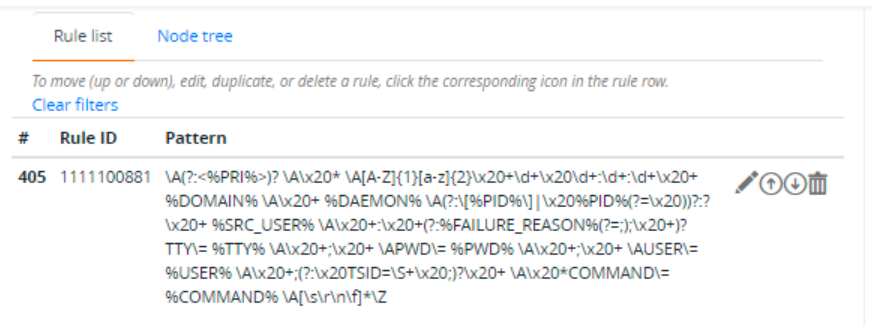
- The Rule list tab displays a list of rules as a table. Each row in the table displays the rule number, its rule ID, and its Regex pattern. After clicking the Edit icon
 , the page displays a table that includes the rule ID and pattern; followed by basic rules and the event descriptor fields. To reorder (move up or down), edit, duplicate, or delete a rule, click the corresponding icon in the rule row.
, the page displays a table that includes the rule ID and pattern; followed by basic rules and the event descriptor fields. To reorder (move up or down), edit, duplicate, or delete a rule, click the corresponding icon in the rule row. - Node tree tab
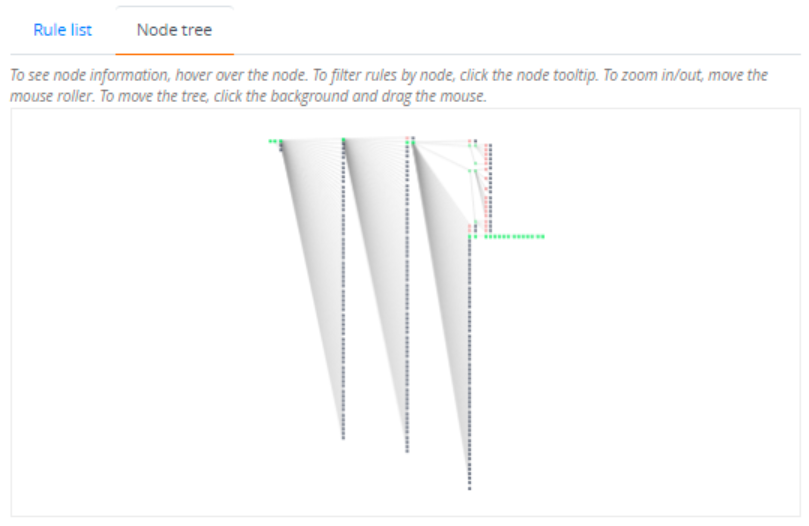
- The Node tree tab displays the list of rules as a tree. Initially, in the node tree, the first node is green and all others are gray. After parsing a sample log that you provide in the Sample event field, the colors of the nodes change - depending on whether the node was visited; or whether the node pattern matched or failed.
The state of each node is displayed in a tooltip box after hovering over the node and also represented by the following colors:
- Grey: The node has not been visited during the parsing process
- Green: The node has been visited and matched
- Red: The node has been visited but pattern matching failed
Note:- The colors red and green reflect the node parsing status when a sample log has been provided.
- In the collapsed state, the colors of the nodes are darker than in the expanded state. For example, dark green in collapsed state; but light green in expanded state.
In the node tree area, you can perform the following actions:
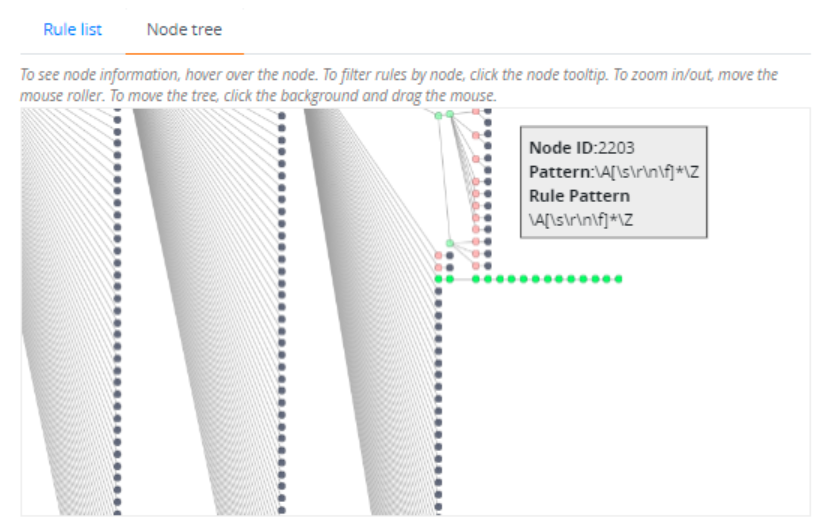
- To view node information: If you hover on a node, the node ID, pattern, and rule pattern of that node are displayed as a tooltip box.
- To zoom in or out of the tree: Move the mouse roller or use the mouse trackpad in the tree area.
- To move the tree: Click the background and drag the tree area (keep the mouse button pressed while dragging).
- To filter rules by node: Click the tooltip box of a node. The view switches to the Rule list tab; displaying a filtered list of rules. To clear the filters and view the entire rule list, click the Refresh icon
 .
.
- To collapse or expand a node: Click the node. This action triggers an update of the tree layout and changes the view of the node tree. Expanding a node zooms in on the tree; collapsing a node zooms out and might display the entire tree in compact form.
Note: In the collapsed state, the colors of the nodes are darker than in the expanded state. For example, dark green in collapsed state; but light green in expanded state.
Editing GP Parser-Based Data Models
Starting from LogLogic LMI 6.4.0, you can edit the parsing rules of data models that use the GP parser. Because these are built-in data models, you cannot edit them directly. You must duplicate a built-in data model, save it in the User group or any other user-created group, and then edit the parsing rules of your new data model.
Similarly, you cannot create a new GP parsing rule. You can edit an existing rule, and then save it either as the same rule or as a new rule (the new rule is automatically assigned a new rule ID). By default, the GP parsing rules are enabled, and cannot be disabled.
Editing parsing rules involves the following steps:
- Defining a source filter.
This procedure is the same as that for advanced data models. See Defining a Source Filter.
- Editing GP Parser Rules
- Reviewing the Data Model Configuration
Editing GP Parser Rules
To edit a GP parser rule, you must add a sample event and then perform the following steps.
- Procedure
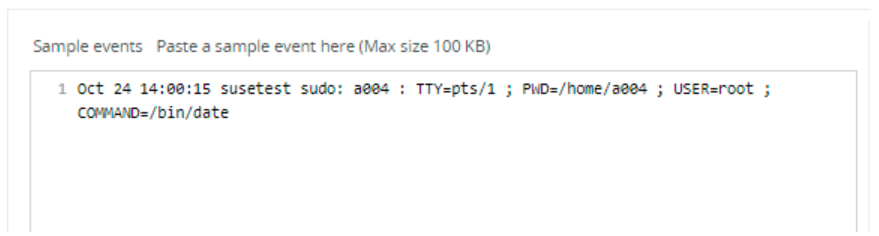
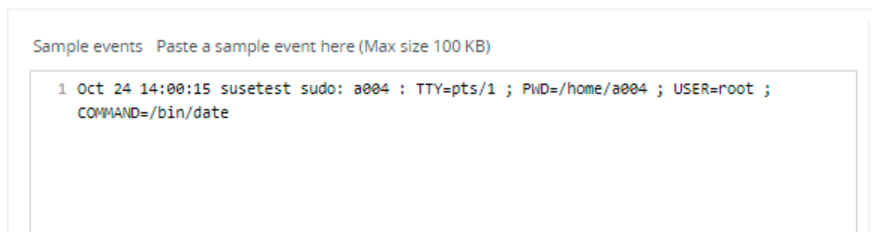
- In the Sample events box, paste a sample event.
This data can help in defining the parsing rule based on the log source. After saving the data model, the sample data is always available when editing the same data model or associated parsing rules.
 Note:
Note:- You can paste a maximum of 100 KB of sample data.
- The tree view shows the node status only for the first event in the Sample events box.
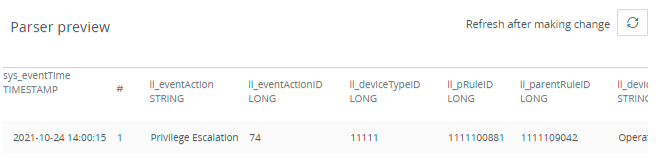
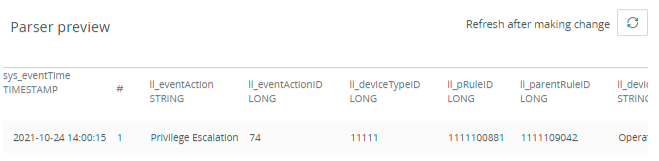
- Click the Refresh icon . The Parser preview panel displays all extracted columns and their data types that are matched by the corresponding parsing rule.
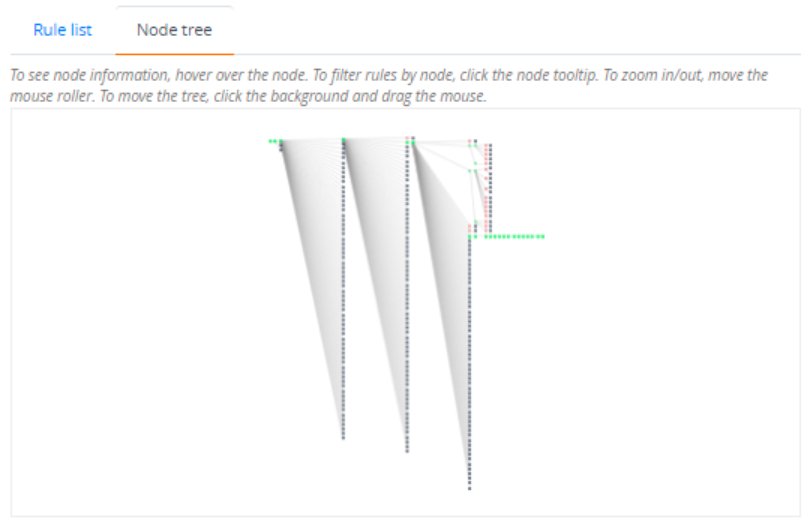
- Click the Node tree tab to see the tree view. The node tree displays nodes with different colors:
- Grey: The node has not been visited during the parsing process
- Green: The node has been visited and matched
- Red: The node has been visited but pattern matching failed
 Note:
Note:- The colors red and green reflect the node parsing status when a sample log has been provided.
- In the collapsed state, the colors of the nodes are darker than in the expanded state. For example, dark green in collapsed state; but light green in expanded state.
- To zoom in or out of the view, move the mouse roller till you have a better view of the matching node. To view the node information of a node, hover over the node.
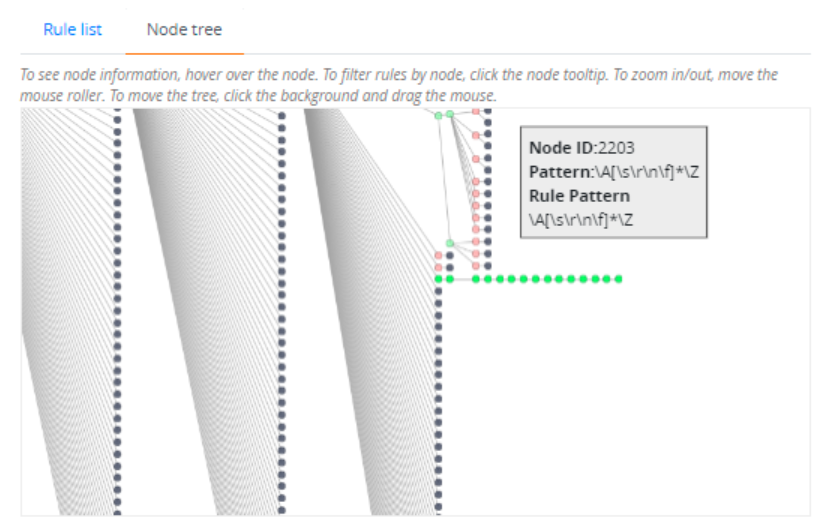
- After clicking the tooltip box, the view switches to the Rule list tab, and only those parsing rules that share the node you clicked are displayed. Scroll to the rule you want to edit and click its Edit or duplicate icon .
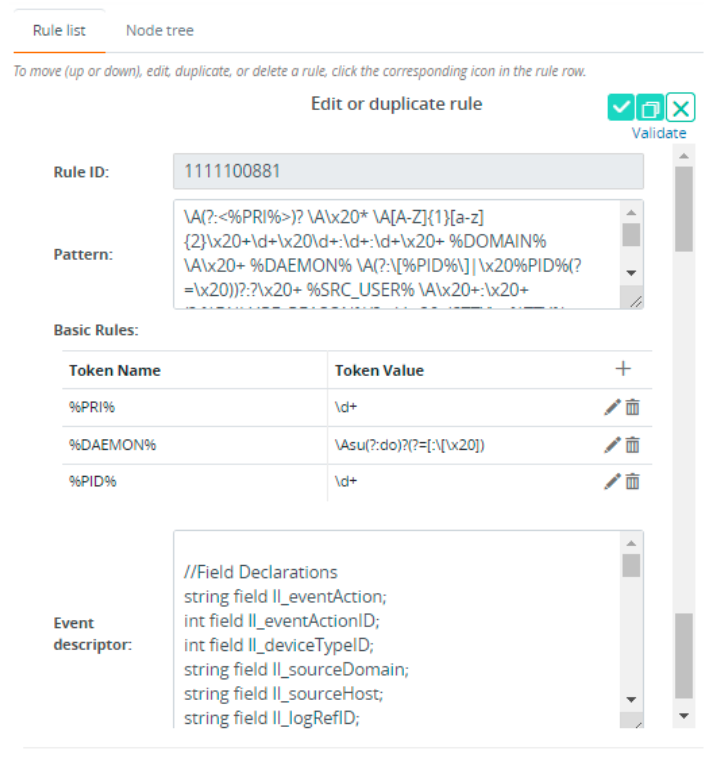
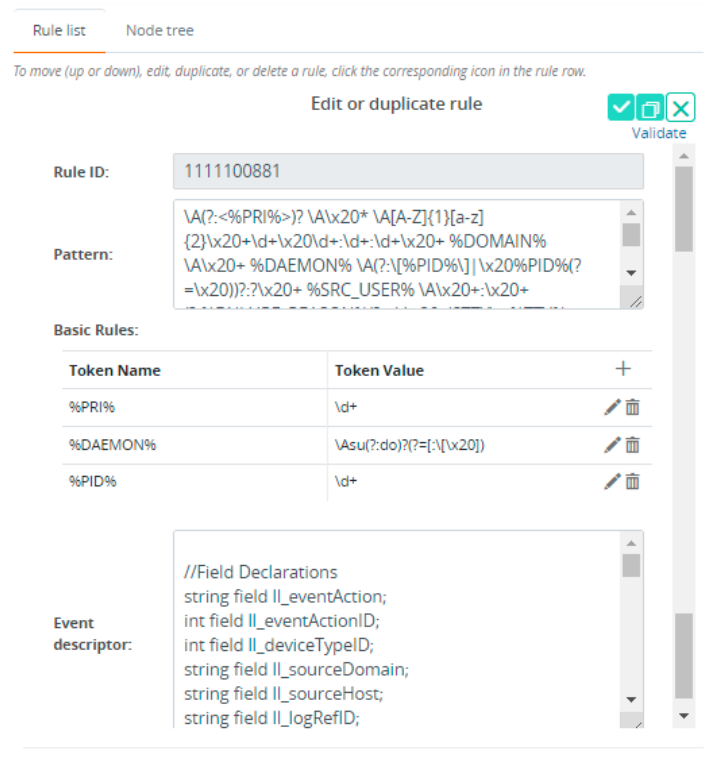
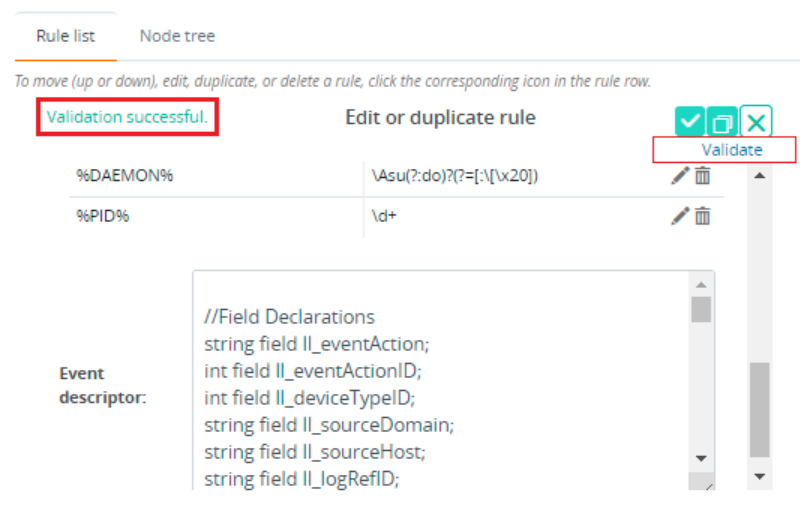
- In the Edit or duplicate rule section, you can edit any fields of the parsing rule except the Rule ID field.
For detailed information about the syntax, description, and format rules, see the Field Reference section.
-
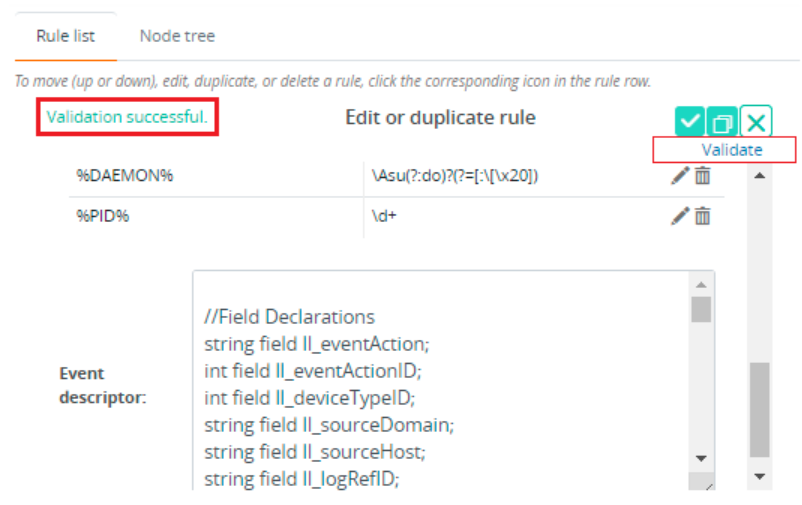
After modifying the required fields, click Validate. If validation of the rule is successful, a message is displayed at the top of the section. If not successful, an error message is displayed, providing the reason for failure.
- You can either save the changes in the same rule or save the rule as a new rule (duplicate the rule):
- To save the changes in the same rule, click the Save icon
 .
. - To save a copy of the rule, click the Save as icon
 .
.
- To cancel the changes, click the Cancel icon
 .
.
Note:- The Save and Save as icons are enabled only after making changes in at least one field (except the Rule ID field) and if validation is successful.
- Saving the parsing rule also saves the data model.
- To save the changes in the same rule, click the Save icon

Reviewing the Data Model Configuration
From the Review configuration page, you can update columns and data types for the associated data model. You can also review column statistics for each defined parsing rule.
- Procedure
- In the Columns panel, all system and custom columns are displayed.
Field Description Name The name of the column that is displayed in the results. Type The data type of the column. Parser rules The rule name that includes the defined column. - Select the Show system columns check box to show all system columns. By default, some system columns are selected. If the check box is not selected, only the user-defined columns and some default system columns are displayed. For a list of system columns, see Types of Columns.
- The Match statistics panel displays overall information about events that are matched by specified parsing rules. It displays how many rules are enabled, how many columns are extracted by the rule, and how many events are matched with each rule.
Field Reference
This section explains the fields in a GP parser. You can edit any fields of the parsing rule except the Rule ID field. For information about how to edit these fields, see the Editing GP Parser Rules section.
A GP parsing rule is a sequence of pattern-matching nodes that parse a log. Each rule is made of pattern-matching nodes and event descriptors. Each node includes a set of basic rules. The basic rules contain token definitions, which are the patterns to be used to match and capture substrings from the log. Such substrings are then assigned to the specified database columns. The definition of which substrings are stored in which database columns is stored in the Event Descriptor field. If a log matches the entire node sequence, an event is generated as defined in the Event descriptor field.
The following table describes the fields in a GP parsing rule:
| Field Name | Description | Format |
|---|---|---|
| Rule ID | The unique identifier of the rule in a data model. It is displayed in Advanced Search results. The rule ID is an auto-generated number and cannot be modified. | Numeric, integer. Format : [0-9]+ |
| Pattern | The Pattern field contains the rule definition. | It is a sequence of Regex or token nodes (%SOMETHING%). Note: The nodes are separated by a space character (' '). Therefore, to use a space character in the pattern, you must use \x20 or \s in the pattern. |
| Basic Rules | The Basic Rules field contains the list of token names and their corresponding patterns. The token names can be reused in the Event Descriptor field to extract substrings. These substrings can be used as function variables or field values. See the Event Descriptor Language Reference section. | %('A' .. 'Z' | 'a' .. 'z' | '_' | '0' .. '9')+% |
| Event descriptor | This field includes a set of columns with the values extracted from the log after the parsing rule completes parsing the log. The columns and their values are displayed in the Parser preview pane. This is a very large section, and includes other subsections. | You must follow the language syntax as described in the Event Descriptor Language Reference section. |
Event Descriptor Language Reference
The event descriptor language is used in the parser rule file. Similar to other programming languages, it includes declarations, statement types, array constructs, and so on.
The following table describes the terms used in this section.
| Term | Used in | Format | Example |
|---|---|---|---|
| Token |
Used in the Basic Rules and Event Descriptor fields. A token is a pattern-capturing group. You can use a token to reference the strings in the Event Descriptor field. |
%('A' .. 'Z' | 'a' .. 'z' | '_' | '0' .. '9')+% | ll_eventID := %EVENTID% |
| Static string | Used in the Event Descriptor field for constants | Any character sequence between double quotes. (escape character: '\') | "Some string", "with a \"” |
| Field or temporary variable | Used in the Event Descriptor field |
LETTER ( LETTER | DIGIT )* Where LETTER includes upper case letters ('A' .. 'Z'), lower case letters ('a' .. 'z'), or underscore ('_') |
ll_eventID |
| Function call | Used in the Event Descriptor field |
FUNCTNAME(expressions) Where the format of FUNCTNAME is: LETTER ( LETTER | DIGIT )* |
concat2(“prefix_”, %EVENTID%) |
| Expressions | Used in the Event Descriptor field for passing arguments to function calls. | It can be a one-to-many static string, token, function call, or temporary field. When specifying a list of expressions, the separator is comma (,). |
|
Basic Operations
This section describes the syntax and format of the following operations:
- Declare a field.
- Declare a temporary variable.
- Assign a value to a field or variable.
- Use conditional statements. Iterate over an array.
- Generate multiple events for a log.
| Operation | Syntax | Example |
|---|---|---|
| Declare a field | TYPE field IDENT;
Format: LETTER ( LETTER | DIGIT )* |
int field ll_eventID; |
| Declare a temporary variable | temp IDENT <ARRAY_MARKER>;
|
|
| Assign a value to a field or temporary variable | IDENT := expression; |
|
| Conditional statement | if ( expression )
{ statements }
( else ( if_statement | ({ statements } ) ) )?
|
|
| ‘Foreach’ statement | Foreach my_var in myTvar {
statements
}
|
Foreach my_var in myTvar {
//create output data : set fields;
insert;
}
|
| ‘insert’ statement
Used in combination with |
insert; | Foreach my_var in myTvar {
//create output data : set fields;
insert;
}
|
Functions
The following table describes a few functions, their syntax, and usage information.
| Function name | Description |
|---|---|
addnum(expression1, expression2)
|
Returns the sum of the expressions. |
concat2(expression1, expression2)
|
Concatenates the two expressions and returns the resultant string. |
| ipAddress(expression) | Converts the expression into an inetAddr value. The expression can be a 32-bit number or a string. |
join(string, expressions) |
Concatenates multiple expressions with the value of string.
|
| logAppId() | Returns the app ID of the GP parser rule. It is an internal identifier and cannot be modified. |
| logId() | Returns the log identifier. |
| logRuleid() | Returns the ID of the matching rule. |
| logsource() | Returns the log source name. |
| logtime() | Returns the log collection time. |
mapRuleAction(expression) |
Calls the enrichment list function for a data model, using the expression for the specific rule ID: <Data model name>_mapRuleAction(Rule_ID) Returns the corresponding value from the enrichment list. |
mapRuleStatus(expression) |
Calls the enrichment list function for a data model, using the expression for the specific rule ID: <Data model name>_mapRuleStatus(RuleID_expression) Returns the corresponding value from the enrichment list. |
match(<regex>, expression)
|
Returns true if the
To use the capturing groups from the |
matchList(<some_regex>, expression)
|
Finds all matches of the |
matchN (group_id) |
Returns a capturing group from the last match() function call. You can then use the capturing group value in other functions or assign the capturing group value to a variable. |
splitChar(expression_split, expression) |
Splits the Use the following pattern: foreach element in T_elementList {
//assign fields values.... ;
Insert;
}
|
splitRegex("some_regex", expression) |
Similar to splitChar(), but with a Regex as the split condition.
|
strequal(expression_string1, expression_string2) |
Returns true if the expression strings are identical. |
strptime(time_format, expression) |
Convert the For more information about how to specify the time format, see Time format specifiers. |
strstr(<source_expression>, search_expression) |
Returns true if the source expression string contains the search expression string. |
upcase(expression) |
Return uppercase string of the expression string.
|
Time format specifiers
Use the following letters to specify the time format parameter in the strptime() function.
| Parameter | Description |
|---|---|
| 'A', 'a' | The day of the week, using the locale's weekday names. Specify either the abbreviated or full name. |
| 'B', 'b' | The month, using the locale's month names. Specify either the abbreviated or full name. |
| 'c', 'C' | Not supported |
| 'd' | The day of the month [1-31]. Leading zeros are permitted, but not required. |
| 'D' | %D is the same as %m/%d/%y. |
| 'e' | %e is the same as %d. |
| 'h' | %h is the same as %b. |
| 'H' | The hour (24-hour clock) [0-23]. Leading zeros are permitted; but not required. |
| 'I' | The hour (12-hour clock) [1-12]. Leading zeros are permitted; but not required. |
| 'j' | The day of the year [1366] Leading zeros are permitted; but not required. |
| 'k' | %k is the same as %H. |
| 'l' | %l is the same as %I. |
| 'm' | The month number [1-12]. Leading zeros are permitted; but not required. |
| 'M' | The minute [0-59]. Leading zeros are permitted; but not required. |
| 'n' | Any white space. |
| 'p' | The locale's equivalent of A.M. or P.M. It is an indicator for the 12-hour clock. |
| 'r' | %r is the time as %I:%M:%S %p. |
| 'R' | %R is the time as %H:%M. |
| 'S' | The seconds [0-61]. Leading zeros are permitted; but not required. You can also specify milliseconds (optional). |
| 't' | %t is any white space. |
| 'T' | %T is the time as %H:%M:%S. |
| 'U' | The week number of the year as a decimal number [0-53]. Leading zeros are permitted but not required. Sunday is considered as the first day of the week. |
| 'w' | The weekday as a decimal number [0-6], with 0 representing Sunday. Leading zeros are permitted; but not required. |
| 'W' | The week number of the year as a decimal number [0-53]. Leading zeros are permitted; but not required. Monday is considered the first day of the week. |
| 'x' | Not supported. |
| 'y', 'Y' | The year including the century. For example, 1998. |
| '%' | %% is replaced by %. |