Architecture and Message Flow
The Schema Repository is used by producer and consumer apps to create and reference schemas to ensure common representation for non-trivial message formats. The producer and consumer apps send and receive messages through the Kafka broker. The Kafka broker and the Schema Repository do not directly communicate. The TIBCO FTL server is used for storage.
Figure 2: Schema Repository Architecture
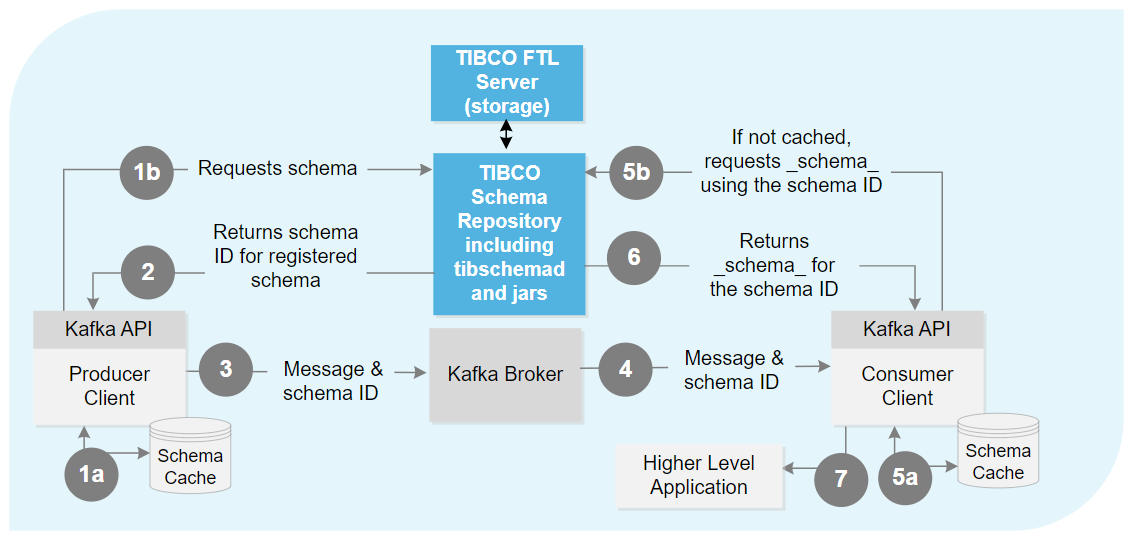
The following message flow is shown in this figure:
-
The producer secures the schema:
-
A producer checks the local schema cache. If the schema information exists, proceed to step 3.
-
If an appropriate schema based on the fields and types does not exist in the cache, the producer contacts the Schema Repository to either a) retrieve the schema ID for an existing schema or b) create a schema or version of an existing schema (if permitted to do so).
-
-
If the schema exists in the Schema Repository, the repository returns the schema ID to the producer. If the Schema Repository does not recognize the schema, the Schema Repository:
-
Validates the schema by looking at the schemas registered with the same subject and applies Avro's compatibility rules to check the new version and the old version.
- Registers the schema as a new distinct schema or applies it as a version to an existing schema.
- Assigns it a schema ID and a version, as appropriate.
- Returns the schema ID for the newly registered schema to the producer. (The producer does not need the version to produce messages.) Warning: If the schema is not compatible, a serialization exception occurs, an error is returned, and the schema is not registered. The consumer is unaware of the error. The developer must resolve the issue.
-
-
The producer serializes the message based on the schema returned and sends the serialized message payload and schema ID to a Kafka broker. The producer updates the cache.
-
The consumer receives the serialized message payload and schema ID from the Kafka broker.
-
After receiving the schema formatted message from the Kafka broker, the consumer examines the header and uses the schema ID to retrieve schema information to properly decode the message.
-
This information might be cached locally if a recent message using the same schema ID and version has been received. If so, the locally cached information is used to decode the received message into its constituting fields with their associated types. If the schema information exists, proceed to step 7.
-
If the schema is not cached locally from a prior message, the consumer requests the _schema_ from the Schema Repository using the schema ID from the received message.
-
-
The Schema Repository returns the _schema_ that corresponds to the schema ID.
Warning: If the schema ID no longer exists, a deserialization exception is returned to the consumer. For example, the schema ID may have been deleted before all messages with the broker have been consumed. -
The consumer decodes the message using the schema format and passes it to the higher-level application. The consumer also caches the schema information locally so the consumer does not have to query the Schema Repository on every subsequent message that uses the same schema and version.