StreamBase recognizes the following data types:
See Specifying Literals in Expressions for information on entering literals for each data type in expressions.
Blobs provide a way of representing binary data in a tuple. They are designed to efficiently process large data objects such as video frames or other multimedia data, although performance might diminish with larger sizes.
In expressions, blobs can be used in any StreamBase function that supports all data
types, such as string() or firstval(). To use a blob in other functions, the blob must first
be converted to a supported data type. For example, error() does not accept a blob, but you can call error(string(, where
you first recast the blob as a string.
b))
The StreamBase blob() function converts a string to a
blob.
Two or more blob values are comparable with relational operators; the comparison is bytewise.
A Boolean always evaluates to either true or
false.
Two or more bool values are comparable with relational operators as follows: true > false.
When you declare a capture field as part of the schema for a hygienic module, you assign a
type name for that capture field. Thereafter, that capture type name appears in the
drop-down list of data types in Studio, and can be referenced as @ in
expressions. While a capture field is not strictly a type of data in the same sense
as the other types on this page, a capture field's type name is effectively a data
type in some circumstances. See Capture Fields in the Authoring Guide.
capture-typename
A double is always 8 bytes. Any numeric literal in scientific notation is considered
a double. That is, you do not need a
decimal point for a numeric literal to be recognized as a double (instead of an int).
For example, 1e1 is considered to be 10.0 (double) instead of 10 (integer).
Two or more double values are comparable numerically with relational operators.
A function can be data on a stream, stored in a table, or passed as an argument to another function. A StreamBase expression can be expressed as a function for efficient reuse.
Syntax for functions begins with the keyword function,
followed by an optional name, any number of arguments inside parentheses, an optional
return type, and a function body inside braces:
functionname(arg1 T, ... argn T)-> returnType{ body }
A name for the specified function is only necessary if the function calls itself recursively, or if you are using function() to define a long function for efficient reuse in other expressions.
In the usual case, the defined function's return type is the same for all output
values. Thus, the usual syntax is without the optional returnType argument:
function name (arg1 T, ... argn T) { body }
If you do specify a return data type prefixed by the two characters "->", that data type must be compatible with the function's
output. If you leave out the data type, StreamBase determines the return type based
on what on the expression body does to its inputs. For details, see Data Type
Coercion and Conversion.
The function body contains a StreamBase expression, such as:
{if (arg1 + arg2) > 0 then sqrt(arg1+arg2) else 0}
For example, the following expression calculates the nth value of the Fibonacci sequence as a long, using
Binet's formula:
round((1/sqrt(5))*(pow((1+sqrt(5))/2,n)-pow((1-sqrt(5))/2,n)))
Here is the expression expressed as a function that operates on an integer field (with a line break added for publication clarity):
function (n int) {round((1/sqrt(5))*
(pow((1+sqrt(5))/2,n)-pow((1-sqrt(5))/2,n)))}
You can add a function as an output expression in, for example, a Map operator, and use it downstream. For generality, however, instead of specifying it as a field grid expression, you can define a function with module scope. To do that, enter the function in the dialog on the Definitions tab of a module, as shown below.
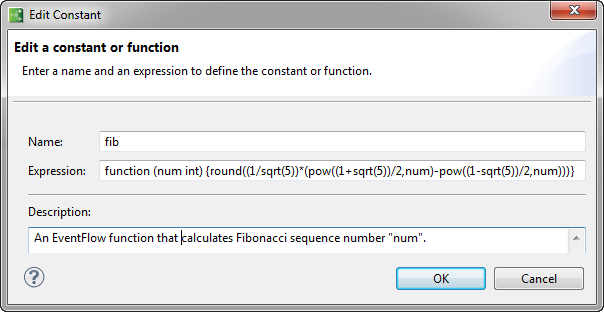
You can use EventFlow functions within and as arguments to other functions, as long as they accept and output compatible data types. For example, you can define a function to call the above function to compute the difference between successive Fibonacci numbers:
function (n int) {fib(n)-fib(n-1)}
or use it as an argument to a built-in function:
sqrt(fib(n))
Certain StreamBase expression language simple list functions
take functions as arguments. This function can be a built in function, a
function-valued field or constant (which is passed by name), or a function literal.
Function literals start with the function keyword.
For example, here the foldleft function passes in a function that
adds a list of ints to the initial value 10 (with line break added for clarity):
foldleft(function addVals(a int, b int) { a+b }, 10,
list(1, 2, 3, 4, 5, 6))
The function call returns:
(int) 31
For more information about defining functions in StreamBase Studio, see Defining Functions in the Expression Language. Also see the related EventFlow Function Sample.
An int is always 4 bytes. The valid range of the int data type is -2,147,483,648 [–231] to 2,147,483,647 [231–1], inclusive. Integers are always
signed. Thus, the following expression is not valid, because the number 2,147,483,648 is not a valid int:
2147483648 + 0
However, integer computations wrap around cleared, so the following expression is
valid and evaluates to -2,147,483,648:
2147483647 + 1
The following expression is valid, because the period means that the number is treated as a floating-point value, which can have a much greater value:
2147483648. + 0.
Two or more int values are comparable numerically with relational operators.
A list is an ordered collection of values, called elements, each of which is of the same StreamBase data type, called the list's element type. The element type can be any StreamBase data type, such as an int, a tuple, or even a list (thus allowing for constructions such as a list of list of int).
In addition to the list() function, you use the
[] constructor to create a list For example,
['this','constructs','a','list','of','type','string',].
As the example illustrates, the last list element can optionally be followed by a
comma (which is ignored) to make it easier to add a new element to the list if you
later need to.
Lists are returned by a variety of functions in the StreamBase expression language,
such as list() and range().
Individual elements in a list can be accessed using their zero-based integer position
(their index) in the list. In any expression
in an EventFlow or StreamSQL program, use brackets to address individual elements of
a list. Thus, for a field named L with data type list, use L[0] to address the first element in the list,
L[1] for the second element, and
L[length(L)-1] to address the last
element.
In most list-related functions that take an index, you can also use a negative index
to count backward from the end of the list. Thus, for a list L, L[-1] is equivalent to L[length(L)-1].
The number of elements in a list can range from zero to a theoretical maximum of 231–1 elements (although that maximum cannot be reached in typical practice). The number of elements in a list is determined at application runtime.
Two or more lists are comparable with relational operators. The comparison is performed lexicographically: that is, like words in a dictionary, with each element in list AAA compared to its corresponding element in list BBB, just as the letters in two words are compared, one by one. For example, the list [1, 2, 3] is less than the list [1, 9, 3], and the list [1, 2] is less than the list [1, 2, 3].
Lists with numeric element types can be coerced if two lists are concatenated or merged in a Union operator, following the rules listed in Data Type Coercion and Conversion. For example, if you have a list(int) merging with a list(double), the result is a merged list(double). Two list(tuple) will successfully merge if a valid supertype tuple can be found. Coercion rules do not apply to output streams with declared, explicit schemas.
See Null Lists for a discussion of null lists compared to empty lists.
Most lists you deal with in the StreamBase expression language are tuple fields with a declared list type in the tuple's schema. You address such a list by means of the field's name, optionally using the bracket syntax shown above to address individual elements of the list. Functions are provided to append to a list, insert elements, replace elements, return the first, last, minimum, or maximum element in a list, and much more. See the list management elements in Simple Functions: Lists.
You can create lists of your own using one of the functions that returns a list,
such as list() and range(). As an alternative, you can define a list and specify
its contents by placing a comma-separated list of elements in square brackets.
Thus, list(100.00, 130.00, 78.34)
and [100.00, 130.00, 78.34] express
the same list.
In contexts where list data appears in string form, such as the output of of sbc dequeue, lists are output in standard array format within square brackets. For example:
list(int) [1,3,5] list(double) [34.78,123.23,90.84,85.00]
Lists of strings do not show each element enclosed in quotes, because the element type of such a list is known to be string. For example:
list(string) [IBM,DELL,HPQ]
When specifying lists as input to sbc
enqueue, enclose the list in quotes to escape the commas inside the
list brackets. For list(string), there is no need to quote each element. For
example, to input data for a stream with schema {int, list(double), list(string), list(int)}, use
the following format:
9456,"[234.0,2314.44]","[IBM,DELL]","[3000,2000]"
When specifying strings and lists that occur within a tuple data type, use one pair
of quotes around the tuple value, and use two pairs of quotes to surround the
string and list members of that tuple. For example, to input data for a stream with
schema tuple(int, int, int), tuple(string,
list(string)), use the following format:
"1, 3, 3"," ""Alpha"", ""[Beta,Gamma,Delta]"" "
In the example above, quotes surround the first tuple field, consisting of three int values. Quotes surround the second tuple field, from the comma after the 3 to the end. Within the second field, two pairs of quotes surround the string sub-field, and surround the list(string) sub-field. Notice that there is still no need to quote each element of the list(string) sub-field.
When using sbc dequeue with its
–v option, elements in a list of strings are shown
surrounded with \", backslash-quote. This is a
display-only convention meant to convey that the quotes around list(string)
elements are escaped. Do not use backslash-quote to enter data with sbc enqueue. For example, the previous example
displayed by sbc dequeue -v looks
like the following example:
OutputStream1: (tupleid=3,T=(i1=1,i2=3,i3=3),W=(x1="Alpha",
x2="[\"Beta\",\"Gamma\",\"Delta\"]"))
(This example is shown here on two lines for clarity, but appears as a single unbroken line in practice.)
A long is always 8 bytes. The range is -9,223,372,036,854,775,808 [-263] to +9,223,372,036,854,775,807 [263 -1]. You can use the long
data type to contain integer numbers that are too large to fit in the four-byte int
data type.
When specifying a long value in a StreamBase expression, append L to the number. Thus, 100L and
314159L are both long values. Without the L, StreamBase interprets values in the int data type's range as
ints. Values outside the range of an int are interpreted as longs without the L.
Two or more long values are comparable numerically with relational operators.
When you define a named
schema for a module or interface, StreamBase automatically generates a new
function in the StreamBase expression language that allows you to construct tuples
with that schema. Thereafter, the names of named schemas appear in the drop-down list
of data types in Studio, which allows you to use a named schema's name wherever you
would use the tuple data type. Thus, while not strictly
a type of data in the same sense as the other entries on this page, the names of
named schemas can be used as an effective data type. See Named Schema Constructor Function in the Authoring
Guide.
A string is a field of text characters.
In previous StreamBase releases, the string data type required specifying the string length. For backwards compatibility, StreamBase still accepts string length specifications, but silently ignores the length.
The theoretical maximum for a string in a single-field tuple is around 2 gigabytes, but the practical limit is much smaller. While StreamBase does support large tuples, including large string fields, be aware that moving huge amounts of data through any application negatively impacts its throughput.
Two or more string values are comparable with the relational operators. By default, strings are compared lexicographically based on ASCII sort order. If Unicode support is enabled for StreamBase Server (as described in Unicode Support), string elements are compared in the sort order for the current character set.
The timestamp data type can hold either an absolute timestamp or an interval timestamp.
An absolute timestamp represents a date and time. Its value is the number of seconds between the epoch and that date and time, with a maximum precision of milliseconds. The epoch is defined as midnight of January 1, 1970 UTC.
An interval timestamp represents a duration. Its value is the number of seconds in the interval, with a maximum precision of milliseconds.
The range for timestamp values is –262 to (262 – 1), which
holds absolute timestamps for plus or minus 146 million years, and hold interval
timestamp values between -4,611,686,018,427,387,904 and
+4,611,686,018,427,387,903.
Absolute timestamps are expressed in the time format patterns of the java.text.SimpleDateFormat class
described in the Sun Java Platform SE reference documentation. For example, the now() function returns a timestamp value for the current time.
The returned value is a representation of the internal value as a date and time.
Thus, the now() function run on 27 May 2011 in the EST
time zone returned:
(timestamp) 2011-05-27 12:06:31.968-0400
By contrast, the expression hours(1)
returns an interval timestamp, showing the number of seconds in one hour:
(timestamp) 3600.0
You can add and subtract timestamp values in expressions, using the rules in the following table:
| Operation | Result | Example |
|---|---|---|
| interval + interval | interval |
Result: 93600.0, the number of seconds in 26 hours. |
| interval – interval | interval |
Result: 79200.0, the number of seconds in 22 hours. |
| absolute + interval | absolute |
Result: an absolute timestamp representing the time one hour from now. |
| absolute – absolute | interval |
Result: an interval timestamp representing the number of seconds between midnight UTC and midnight in the local time zone. |
| absolute + absolute | Absolute |
Result: an absolute timestamp representing double the number of
milliseconds between now and the epoch (January 1, 1970 UTC). This is
calculated as |
Two or more timestamp values are comparable with relational operators such as > and <. You must compare timestamp values interval-to-interval or absolute-to-absolute. You cannot compare interval-to-absolute or absolute-to-interval.
In comparison expressions that use the operators ==, !=, <=, >=, <, or >, if one side of the comparison is a timestamp, and the other side is a string literal, StreamBase tries to interpret the string as a valid timestamp. If the string literal does not contain an explicit time zone, the string is interpreted as having the time zone set in the operating system of the computer that compiles the application. If the conversion of the string literal fails, then the comparison fails typechecking.
StreamBase supports three ways of specifying time zones. The following examples all indicate the same time zone (Central Europe):
| Content | Data Type | Example |
|---|---|---|
| Offset in hours | double |
|
| Zone Abbreviation | string |
|
| Time Zone ID | string |
|
Certain timestamp functions allow you to use these specifications as arguments, but not interchangeably. Selected time zone IDs for the United States and Europe are shown below. Note that time zone ID literals are case-sensitive.
| Time Zone or City | Time Zone ID | GMT/UTC Offset |
|---|---|---|
| US Eastern Standard Time |
|
-05:00 |
| US Central Standard Time |
|
-06:00 |
| US Mountain Standard Time |
|
-07:00 |
| US Pacific Standard Time |
|
-08:00 |
| US Alaska Standard Time |
|
-09:00 |
| US Hawaii Standard Time |
|
-10:00 |
| Greenwich Mean Time |
|
00:00 |
| London UK |
|
+01:00 |
| Zurich CH |
|
+02:00 |
| Minsk BY |
|
+03:00 |
| Moscow RU |
|
+04:00 |
| Calcutta IN |
|
+05:00 |
| Bangkok TH |
|
+07:00 |
| Singapore SG |
|
+08:00 |
| Seoul KR |
|
+09:00 |
For for a full listing, see the Wikipedia article List of tz database time
zones. You can also obtain the list by calling the Java function TimeZone.getAvailableIDs(). See the Javadoc for class TimeZone for details.
The functions get_second() ... get_year() take time zone IDs as an optional second argument to
obtain timestamp fields for a given time zone rather than for local time, as
described in Timestamp Fields.
The tuple data type is an ordered collection of fields, each of which has a name and a data type. The fields in the collection must be defined by a schema, which can be unnamed or named. Fields can be of any StreamBase data type, including other tuples, nested to any depth. The size of a tuple depends on the aggregate size of its fields.
See Null Tuples for a discussion of null tuples and empty tuples.
Two or more tuples are comparable with relational operators as long as the tuples being compared have identical schemas.
The following sections discuss features of the tuple data type:
In expressions, you can address a tuple field's individual sub-fields using dot
notation: tuplename.tuplefieldname
In an EventFlow application, tuplename is
the name of a field of type tuple, and tuplefieldname is name of a sub-field.
In StreamSQL, tuplename is either:
-
The name of a named schema created with CREATE SCHEMA.
-
The name of an individual tuple created with the tuple() function, and named with the final AS keyword.
In StreamSQL, tuple is not a keyword like string or blob. Instead, you use the tuple data type when you define a schema, either named or anonymous. The following example shows how the tuple data type is used in StreamSQL to form a tuple with a tuple sub-field:
CREATE SCHEMA NamedSchema1 (myInt1 int, myDouble1 double);CREATE SCHEMA NamedSchema2 (myInt2 int, myTuple1 NamedSchema1);
CREATE INPUT STREAM in ( myInt3 int, AnonTupleField1 (myDouble2 double, myString1 string),
AnonTupleField2 (myString2 string, mySubTuple NamedSchema1)
);
These comments refer to lines with callout numbers in the example above:
|
|
Create a named schema containing an int field and a double field. |
|
|
Create another named schema, this time containing an int field and a tuple
field. The tuple field's schema consists of a reference to the first named
schema, and therefore, its fields are |
|
|
The input stream's schema includes an int field followed by two tuple fields with anonymous schemas. |
|
|
The second tuple field's schema includes a string followed by a nested tuple, which references one of the named schemas. |
See the CREATE SCHEMA Statement reference page for more on the distinction between named and anonymous schemas.
In an expression, use the tuple() function to create both schema and field values of a single tuple.
The name of a named schema automatically becomes a generated function that returns a single tuple with that schema. See named schema constructor function for details.
In contexts where a tuple value appears in textual string form, comma-separated
value (CSV) format is used. Examples of such contexts include the contents of files
read by the CSV Input Adapter, written by the CSV Output Adapter, and in the result
of the Tuple.toString() Java API method.
Use the nested quote techniques in this section to enter a field of type tuple when specifying input data at the command prompt with sbc enqueue.
The string form of a tuple with three integer fields whose values are 1, 2, and 3 is the following:
1,2,3
We will refer to the above as tuple A.
When tuple A appears as a field of type tuple inside another tuple, surround tuple A with quotes. For example, a second tuple, B, whose first field is a string and whose second field is tuple A, has a CSV format like the following:
IBM,"1,2,3"
These quotes protect the comma-separated values inside the second field from being interpreted as individual field values.
With deeper nesting, the quoting gets more complex. For example, suppose tuple B, the two-field tuple above, is itself the second field inside a third tuple, C, whose first field is a double. The CSV format of tuple C is:
3.14159," IBM,""1,2,3"" "
The above form shows doubled pairs of quotes around 1,2,3, which is necessary to ensure that the nested quotes are
interpreted correctly. There is another set of quotes around the entire second
field, which contains tuple B.
StreamBase's quoting rules follow standard CSV practices, as defined in RFC 4180, Common Format and MIME Type for Comma-Separated Values (CSV) Files.
You can duplicate any tuple field into another field of type tuple without using
wildcards. For example, a Map operator might have an entry like the following in
its Additional Expressions grid, where both
IncomingTuple and CopyOfIncomingTuple are the names of tuple fields:
| Action | Field Name | Expression |
|---|---|---|
| Add | CopyOfIncomingTuple | IncomingTuple |
Use the .* syntax to flatten a
tuple field into the top level of a stream.
For example, a Map operator might define an entry like the following in its Additional Expressions grid. When using this syntax, you must have an asterisk in both Field Name and Expression columns.
| Action | Field Name | Expression |
|---|---|---|
| Add | * | IncomingTuple.* |
Use the * AS * syntax for
tuples defined with a named schema to copy the entire tuple into a single field of
type tuple.
For example, let's say the tuple arriving at the input port of a Map operator was
defined upstream with the NYSE_FeedSchema named
schema. To preserve the input tuple unmodified for separate processing, the Map
operator could add a field of type tuple using settings like the following in the
Additional Expressions grid. When using the
* AS * syntax in the
Expression column, the name of the tuple field in the
Field Name column has an implied asterisk for all of
its fields.
| Action | Field Name | Expression |
|---|---|---|
| Add | OriginalOrder | NYSE_FeedSchema(input1.* as *) |
Because the Map operator has only one input port, the port does not need to be named:
| Action | Field Name | Expression |
|---|---|---|
| Add | OriginalOrder | NYSE_FeedSchema(* as *) |
A null tuple results when the entire tuple is set to null (not just the fields of the tuple).
An empty tuple is a tuple with each individual field set to null.
A no-fields tuple is what is sent to an input stream that has an empty schema, which is a schema with no fields defined, as described in Using Empty Schemas. An input stream with an empty schema might be declared, for example, as a trigger for a Read All Rows operation on a Query Table. In this case, the tuple sent to this input stream is itself neither null nor empty, it is a no-fields tuple.