Click Files
and data ![]() .
.
In the Files and data flyout, click Connect to.
In the list of connectors, click Apache Spark SQL.
In the Apache Spark SQL flyout, click New connection.
This dialog is used to configure a connection to an Apache Spark SQL database, and to Databricks Cloud. You can choose whether to analyze data in-database, or to import it into your analysis.
To access data in Apache Spark SQL with the Spotfire connector for Apache Spark SQL, the Spark Thrift Server must be installed on your cluster. Spark Thrift Server provides access to Spark SQL via ODBC, and it might not be included by default on some Hadoop distributions.
Note that you need to install a driver on your computer to access the Apache Spark SQL connector. See the system requirements to find the correct driver. You can also view Getting Started with Connectors to learn more about getting access to connectors in Spotfire.
Note: If you use the in-database load method when connecting to Apache Spark 2.1 or later, and you encounter errors in your analysis, the option spark.shuffle.service.enabled might have to be enabled on the Spark server.
You can also create an Apache Spark SQL connection for performing Databricks SQL Analytics queries. To be able to connect to Databricks, you must install the Databricks ODBC driver. Check the system requirements for the Apache Spark SQL connector, and see Drivers and data sources in TIBCO Spotfire for finding the right driver.
Note: When connecting to a Databricks cluster that is not already running, the first connection attempt will trigger the cluster to start. This can take several minutes. The Database selection menu will be populated once Spotfire is connected successfully. You may have to click Connect again if the connection times out.
To add a new Apache Spark SQL connection to the library:
On the menu bar, select Data > Manage Data Connections.
Click Add New > Data Connection and select Apache Spark SQL.
To add a new Apache Spark SQL connection to an analysis:
Click Files
and data ![]() .
.
In the Files and data flyout, click Connect to.
In the list of connectors, click Apache Spark SQL.
In the Apache Spark SQL flyout, click New connection.
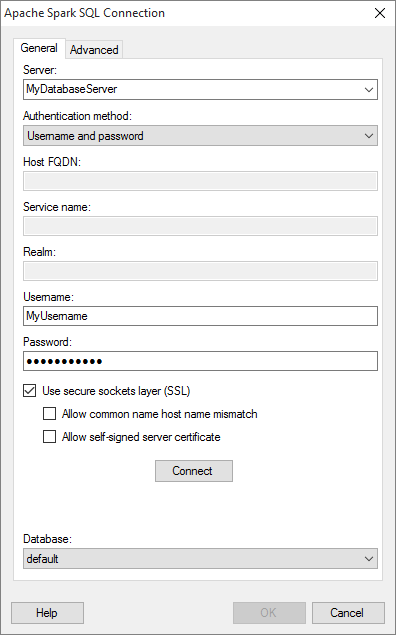
Option |
Description |
Server |
The name
of the server where your data is located. To include the port
number that the Spark Thrift Server listens on, add it directly
after the name preceded by colon. For example: Note: If you do not specify a port number, the port number 10000 will be used, which is the default port number that Spark Thrift Server listens on. |
Authentication
method |
The authentication method to use when logging into the database. Choose from
|
Host
FQDN |
[Only applicable when Kerberos authentication is selected.] The fully qualified domain name of the Spark Thrift Server host. For more information about the host FQDN, contact your Apache Spark SQL system administrator. |
Service
name |
[Only applicable when Kerberos authentication is selected.] The Kerberos service principal name of the Spark server. For example, "spark". For more information about the service name, contact your Apache Spark SQL system administrator. |
Realm |
[Only applicable when Kerberos authentication is selected.] The realm of the Spark Thrift Server host. Leave blank if a default Kerberos realm has been configured for your Kerberos setup. For more information about the realm, contact your Apache Spark SQL system administrator. |
Username |
The name of the user account you wish to use when logging into Apache Spark SQL. |
Password |
The password for the specified username. |
Connect |
Connects you to the specified server and populates the list of available databases. |
Database |
Select the database of interest from the drop-down list. |
Use secure sockets
layer (SSL) |
Select this check box to connect using SSL. Note: By default, SSL is enabled. |
Allow
common name host name mismatch |
[Only applicable when Use secure sockets layer (SSL) is selected.] Select this check box if it should be allowed that the certificate name does not match the host name of the server. |
Allow self-signed server certificate
|
[Only applicable when Use secure sockets layer (SSL) is selected.] Select this check box to allow self-signed certificates from the server. |
Advanced
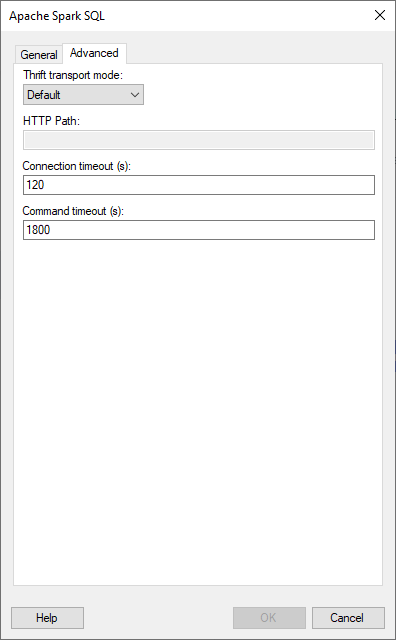
Option |
Description |
Thrift transport mode
|
Select the transport mode that should be used to send requests to the Spark Thrift Server. Choose from
|
HTTP Path |
[Only available when Thrift transport mode HTTP is selected.] Specify the partial URL that corresponds to the Spark server you are connecting to. Note: The partial URL is appended to the host and port specified in the server field. For example, to connect to the HTTP address http://example.com:10002/gateway/default/spark, enter example.com:10002 as the server and /gateway/default/spark as the HTTP path. |
Connection timeout (s) |
The maximum time, in seconds, allowed for a connection to the database to be established. The default value is 120 seconds. |
Command timeout (s) |
The maximum time, in seconds, allowed for a command to be executed. The default value is 1800 seconds. |