Team Studio API Demo
You can run workflows remotely through the application's API. Beyond the ability to run the flow from outside the UI, you can define workflow variables at runtime. In this demo, we show how this can empower you to loop through a list in which the same modeling must be done for various values.
In this example, we look at the election92 dataset, a 3,141 row dataset with information about each county in the United States at the time of the 1992 election. Included in this data are the county name and state as well as statistics about the county demographics and voting patterns.
50 States, 50 Workflows?
While there are many useful applications of this entire dataset, it may be more interesting to analyze each state's data individually. This work could be replicated with the Group By configuration in the Summary Statistic operator, but that would require creating 50 row filters and manipulating them all within the UI.
Instead, we will create a single workflow, use workflow variables, and contact the API to automate the looping over all states.

Data Set Exploration
A first glance at the dataset indicates that we should be able to do a simple row filter on the state column to isolate a state's data.
Row Filter with Workflow Variable
By using workflow variables, we can change the state we are filtering each time we run the workflow using the API.

Below, you can see the initial workflow variable configuration, which includes the variable @state set to AL. Note that all workflow variables begin with @.
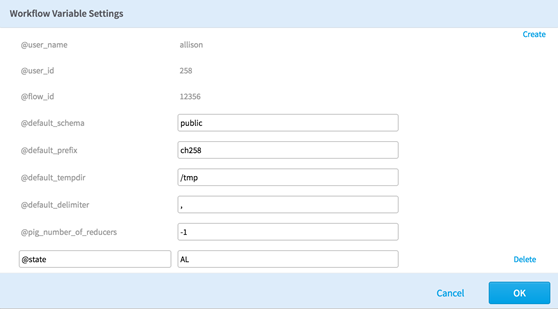
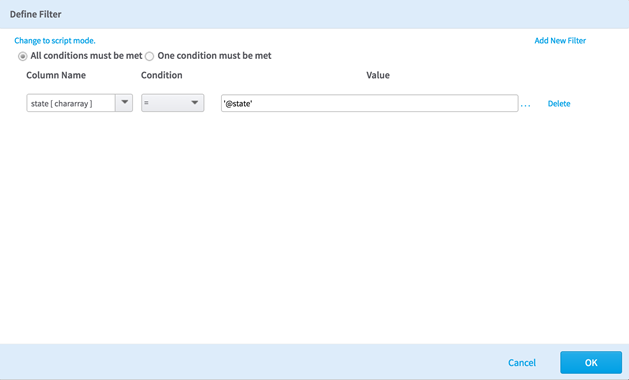
Now we define our filter configuration by adding a row filter to our data, selecting Define Filter from the configuration dialog box, and setting the Column Name (state[chararray]) to be equal to '@state'. Be sure to include the single quotes around the workflow variable.
To point out the ability to use workflow variables on data sets, we save our results as 50 individual tables within our Hadoop data source. To do this, we set the Results Name field to @state. This means that when the results are saved, the value of @state, which is currently AL, is used as the file name for the results. By using the API, we can loop through a list of the state names and create one file per state.
Use the API to Run the Workflow
The Team Studio API enables us to run a workflow without having to go to Team Studio in our browser. Instead, we can use the command line or write a script to run workflows. This extends the power of Team Studio, allowing us to run the workflow as a piece of our script. In this demo, we write a Bash script that can be run from the command line. This script loops over a list of the state abbreviations, allowing us to define the abbreviation when we run the flow. By doing this, we can change the workflow variables we mentioned above 50 times in a fraction of the time it would take us to do manually.
Creating the Request
Each of the following steps will be put into a Bash script. We begin by creating a file called 50states.sh.
First, we define our root URL as follows:
ROOT_URL="http://$host:$port/alpinedatalabs/api/v1/json"
where
- $host is the Team Studio application host.
- $port is the Team Studio port.
- alpinedatalabs is our application server name.
The complete URL for the request should take the following form:
url="$ROOT_URL/workflows/$workflowID/run?token=$token"
where
- $workflowID is the ID of the workflow being run.
- $token is the API authentication token (same as the Team Studio session ID, found at http://$host:$port/servername/api/sessions).
Next, we must define our workflow variables. To do this, we include a JSON payload in the request. Below is an example of this payload:
{
"meta" : { "version" : 1},
"variables" : [
{ "name" : "@state" , "value" : "AL"}
]
}
Finally, we combine this all in a Bash script that loops through all 50 2-letter state abbreviations and calls the workflow using the abbreviation as the workflow variable. Running the API creates a new directory in our Hadoop data source that contains the filtered data. As you can see, we've added the line 'sleep 15' to ensure that the workflow finishes running before moving to the next state. Alternatively, you query the process which is running to see if it has finished.
Our final script:
workflowID=???
token=mytokenhere
ROOT_URL="http://$host:$port/servername/api/v1/json"
url="$ROOT_URL/workflows/$workflowID/run?token=$token"
states=("AL" "AK" "AZ" "AR" "CA" "CO" "CT" "DE" "FL" "GA" "HI" "ID" "IL" "IN" "IA" "KS" "KY" "LA" "ME" "MD" "MA" "MI" "MN" "MS" "MO" "MT" "NE" "NV" "NH" "NJ" "NM" "NY" "NC" "ND" "OH" "OK" "OR" "PA" "RI" "SC" "SD" "TN" "TX" "UT" "VT" "VA" "WA" "WV" "WI" "WY")
for i in "${states[@]}"
do
workflow_variables='{"meta":{"version":1}, "variables":[{"name":"@state", "value":"'"$i"'"}]}'
response=$(curl -i -H "Content-Type: application/json" -d "$workflow_variables" -X POST "$url")
echo $response
sleep 15
done
Adding Summary Statistics
After running the above script successfully, we create a new workflow like the one below to get the summary statistics for each state. This will be a new workflow file, so that it has a different ID in the API.
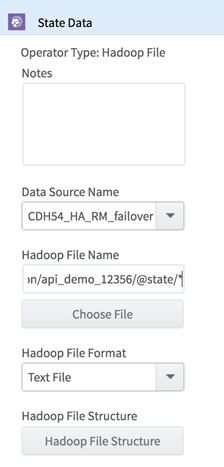
We navigate to the folder on our cluster where we stored the result file, and drag it to the canvas. We call it "State Data". Double-click the icon to bring up the configuration properties.
Change the value AL in the Hadoop File Name parameter to be our workflow variable, @state. This allows us to change the state we are analyzing when we call the API.
Configure Summary Statistics
Our Summary Statistics configuration is shown below, showing statistics for the pop, income, and turnout columns.
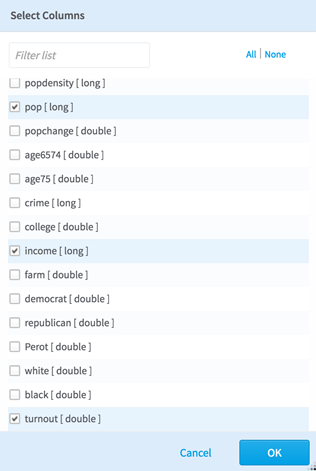
Once again, we set the Results Name configuration to @state. By setting Overwrite to Yes, we create a way to rerun this information.
Run Workflow
Running the Summary Statistics workflow is nearly identical to running the Row Filter workflow from before. A different workflow ID is called in the script, using the same looping pattern as before to go through all 50 states. In the end, we are left with 50 result tables from the Summary Statistics calculations, stored on our HDFS cluster.