Configure Columns: Text Files
The Configure Columns dialog changes options depending on the file type specified in the Hadoop File properties dialog. The options described in this topic are available for text files.
| Column configuration | Description |
|---|---|
| Vertical/Horizontal File View | If the text file contains a large number of columns, then you can click the
switch icon ( |
| Escape and Quote Characters | Specify the escape and quote characters used in the file. |
| Delimiter |
Select the delimiter from the list.
|
| Headers |
When TIBCO Data Science – Team Studio opens the Configure Columns dialog, TIBCO Data Science – Team Studio uses heuristics to determine if the first row of data is a header row, and selects or clears the control First row contains header based on this determination. You can select or clear this property manually.
|
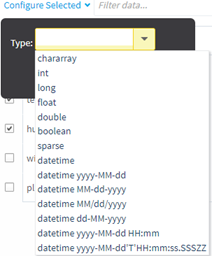
| Data Columns |
TIBCO Data Science – Team Studio attempts to infer the correct column names and data types by using a sample of the first few rows. When the dialog is displayed, each column is preceded by the inferred data type. You can change these settings by providing new column names and data types. The drop-down list box provides a list of standard data types.
You can change the data type for multiple columns. Set the view to horizontal format, select the checkboxes for the desired columns, and then click Configure Selected.
The list of columns can also be filtered with the filter field. Note: For
datetime data types, if the source data uses the ISO
datetime format, you should select the basic
datetime data type option to preserve the flexibility of the ISO formatting. ISO provides an international data exchange format framework for
datetime data types that converts all
datetime values into the number of milliseconds since 1970. For more details, see
ISO DateTime Format.
If the source data is not in ISO
You can modify the list of specific
Default
Although a list of
|