Adding a Hadoop Data Source from the User Interface
To add an HDFS data source, first make sure the TIBCO Data Science - Team Studio server can connect to the hosts, and then use the Add Data Source dialog to add it to TIBCO Data Science - Team Studio.
You must have data administrator or higher privileges to add a data source. Ensure that you have the correct permissions before continuing.
- Procedure
- From the menu, select Data.
- Select Add Data Source.
- Choose
Hadoop Cluster as the data source type.
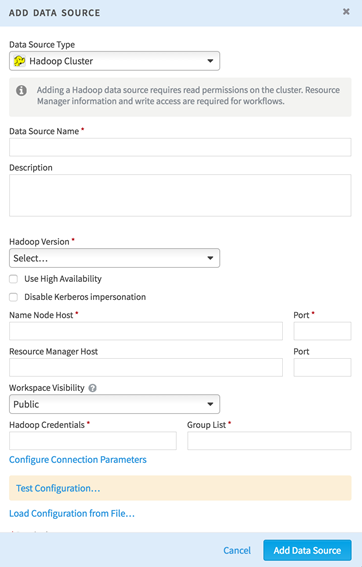
- Specify the following data source attributes:
Data Source Name Set a user-facing name for the data source. This should be something meaningful for your team (for example, "Dev_CDH5_cluster"). Description Enter a description for your data source. Hadoop Version Select the Hadoop distribution that matches your data source. Use High Availability Check this box to enable High Availability for the Hadoop cluster. Disable Kerberos Impersonation If this box is selected and you have Kerberos enabled on your data source, then the workflow uses the user account configured as the Hadoop Credentials here. If this box is cleared, the workflow uses the user account of the person running the workflow.
If you do not have Kerberos enabled on your data source, you do not need to select this box. All workflows run using the account configured as the Hadoop Credentials.
NameNode Host Enter a single active NameNode to start. Instructions for enabling High Availability are in Step 10. To verify the NameNode is active, check the web interface. (The default is http://namenodehost.localhost:50070/)
NameNode Port Enter the port that your NameNode uses. The default port is 8020. Job Tracker/Resource Manager Host For MapReduce v1, specify the job tracker. For YARN, specify the resource manager host. Job Tracker/Resource Manager Port Common ports are 8021, 9001, 8012, or 8032. Workspace Visibility There are two options here: - Public - Visible and available to all workspaces.
- Limited - Visible and available only to workspaces they are associated with.
To learn more about associating a data source to a workspace, see Data Visibility.
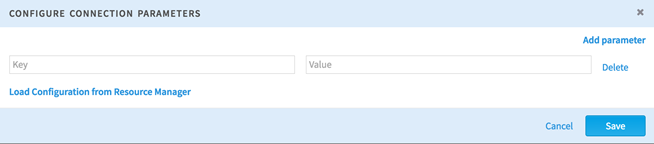
Hadoop Credentials Specify the user or service to use to run MapReduce jobs. This user must be able to run MapReduce jobs from the command line. Group List Enter the group to which the Hadoop account belongs. - For further configuration, choose Configure Connection Parameters.
- Specify key-value pairs for YARN on the
TIBCO Data Science - Team Studio server. Selecting
Load Configuration from Resource Manager attempts to populate configuration values automatically.
yarn.resourcemanager.scheduler.addressyarn.app.mapreduce.am.staging-dir
 Note: Be sure the directory specified above in the
Note: Be sure the directory specified above in thestaging-dirvariable is writable by the TIBCO Data Science - Team Studio user. Spark jobs produce errors if the user cannot write to this directory.Required if different from default:
yarn.application.classpath- The
yarn.application.classpathdoes not need to be updated if the Hadoop cluster is installed in a default location. - If the Hadoop cluster is installed in a non-default location, and the
yarn.application.classpathhas a value different from the default, the YARN job might fail with a "cannot find the class AppMaster" error. In this case, check the yarn-site.xml file in the cluster configuration folder. Configure these key:value pairs in the UI using the Configure Connection Parameters option.
- The
yarn.app.mapreduce.job.client.port-range- This describes a range of ports to which the application can bind. This is useful if operating under a restrictive firewall that needs to allow specific ports.
Recommended:
mapreduce.jobhistory.address = FQDN:10020Caution: Operators that use Pig for processing do not show the correct row count in output ifmapreduce.jobhistory.addressis not configured correctly.yarn.resourcemanager.hostname = FQDNyarn.resourcemanager.address = FQDNyarn.resourcemanager.scheduler.address = FQDN:8030yarn.resourcemanager.resource-tracker.address = FQDN:8031yarn.resourcemanager.admin.address = FQDN:8033yarn.resourcemanager.webapp.address = FQDN:8088mapreduce.jobhistory.webapp.address = FQDN:19888
- Save the configuration.
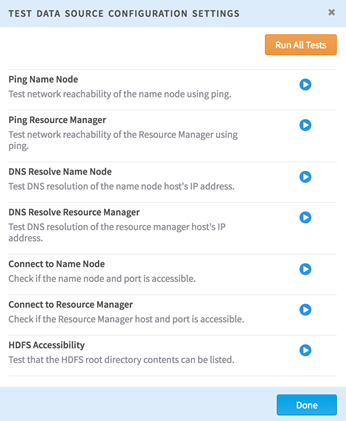
- To perform a series of automated tests on the data source, click
Test Connection.
- Click Save Configuration to confirm the changes.
- When the connectivity to the active NameNode is established above, set up NameNode High Availability (HA) if enabled.
Required:
dfs.ha.namenodes.nameservice1dfs.namenode.rpc-address.nameservice1.namenode<id> (required for each namenode id)dfs.nameservicesdfs.client.failover.proxy.provider.nameservice1
Recommended:
ha.zookeeper.quorum
Note: Support for Resource Manager HA is available.To configure this, add
failover_resource_manager_hoststo the advanced connection parameters and list the available Resource Managers.If one of the active Resource Managers fails during a job running, you must rerun the job, but you no longer must reconfigure the data source that failed. If one of the active Resource Managers fails while a job is not running, you do not need to do anything. TIBCO Data Science - Team Studio uses another available Resource Manager instead.