Linear Regression - MADlib
TIBCO Data Science - Team Studio supports the MADlib open source implementation of the Linear Regression algorithm.

Information at a Glance
|
Parameter |
Description |
|---|---|
| Category | Model |
| Data source type | DB |
| Send output to other operators | No |
| Data processing tool | MADlib |
Algorithm
The MADlib Linear Regression operator applies an Ordinary Least-Squares (OLS) linear regression algorithm to the input dataset. It is processed using the least squares method of regression analysis, meaning that the model is fit such that the sum-of-squares of differences of observed and predicted values is minimized.
More information including general principles can be found in the official MADlib documentation.
Input
A data set that contains the dependent and independent variables for modeling.
Configuration
| Parameter | Description |
|---|---|
| Notes | Notes or helpful information about this operator's parameter settings. When you enter content in the Notes field, a yellow asterisk appears on the operator. |
| MADlib Schema Name | Schema where MADlib is installed in the database. MADlib must be installed in the same database as the input dataset. If a "madlib" schema exists in the database, this parameter defaults to madlib. |
| Model Output Schema Name | The name of the schema where the output is stored. |
| Model Output Table Name | The name of the table that is created to store the Regression model. Specifically, the model output table stores:
See the official MADlib linear regression documentation for more information. |
| Drop If Exists |
|
| Dependent Variable | Required. The quantity to model or predict.
|
| Independent Variables | Click
Select Columns to select the available columns from the input data set for analysis.
Select the independent variable data columns for the regression analysis or model training. You must select at least one column. |
| Grouping Columns | You can set at least one column to group the input data and build separate regression models for each group.
Click Select Columns to open the dialog for selecting the available columns from the input dataset for grouping. |
| Heteroskedacity Stat | Set to
true (the default) to output two additional columns to the model table.
|
| Draw Residual Plot | Set to
true (the default) to output Q-Q Plot and Residual Plot graphs for the linear regression results.
|
Output
When assessing the Data tab results of the Linear Regression Operator, a modeler focuses mostly the Coefficient values, which indicate the strength of the effect of the independent variables on the dependent variable, and the associated P-values, which indicate how much not to trust the estimated correlation measurement.
The derived linear regression model is a mathematical equation linking the Dependent Variable (Y) to the Independent Variables (X1, X2, etc.). It includes the scaling or Coefficient values (β1, β2, etc.) associated with each independent variable in the model. Note: The resulting linear equation is expressed in the form of Y= β0 + β1*X1 + β2*X2 + …
The following overall model statistical fit numbers:
- R2: R2 is called the multiple correlation coefficient of the model, or the Coefficient of Multiple Determination. It represents the fraction of the total Dependent Variable (Y) variance explained by the regression analysis, with 0 meaning 0% explanation of Y variance and 1 meaning 100% accurate fit or prediction capability.
Note: In general, an R2 value greater than .8 is considered a good model. However, this value is relative and in some situations just getting an improved R2 from .5 to .6, for example, would be beneficial.
- S: represents the standard error per model (often also denoted by SE). It is a measure of the average amount that the regression model equation over- or under-predicts.
- The rule of thumb data scientists use is that 60% of the model predictions are within /- 1 SE and 90% are within /- 2 SEs.
For example, if a linear regression model predicts the quality of the wine on a scale between 1 and 10 and the SE is .6 per model prediction, then a prediction of Quality=8 means the true value is 90% likely to be within 2*.6 of the predicted 8 value (that is, the real Quality value is likely between 6.8 and 9.2).
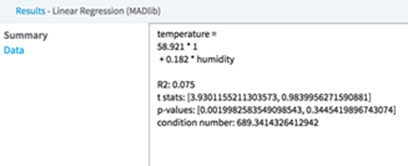
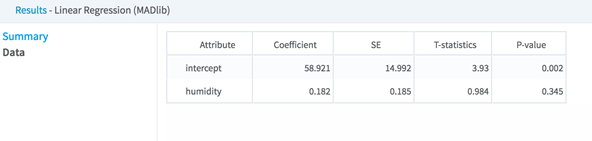
| Column | Description |
|---|---|
| Coefficient | The model coefficient, β, indicates the strength of the effect of the associated independent variable on the dependent variable.
Standard Error, or SE, represents the standard deviation of the estimated Coefficient values from the actual Coefficient values for the set of Variables in the regression.
|
| T-statistic | The T-statistic is computed by dividing the estimated value of the β Coefficient by its Standard Error, as follows: T= β/SE. It provides a scale for how big of an error the estimated coefficient has.
|
| P-value | P-value represents the probability of still observing the dependent variable's value if the Coefficient value for the independent variable is zero (that is, if p-value is high then the associated variable would not be considered relevant as a correlated, independent variable in the model).
|