Wide Data Variable Selector - Chi Square / Anova
From a very large data set (that is, one whose variables number in the thousands or millions), produces a new data set with correlations and significance statistics for each predictor (X) variable against a user-specified dependent (Y) variable.
![]()
Information at a Glance
|
Parameter |
Description |
|---|---|
| Category | Transform |
| Data source type | HD |
| Send output to other operators | Yes |
| Data processing tool | Spark SQL |
Algorithm
For each predictor (X) variable, the operator computes the correlation against the dependent (Y) variable. If categorical predictors exist, they are converted to continuous predictors using impact coding before the correlations are calculated. The algorithm does two passes through the data, one to collect the dependent values and another to calculate the correlations.
The t statistic and corresponding p value calculations use the following formula.
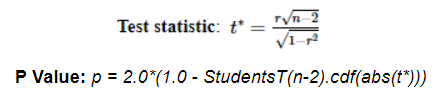
Scalability should not be limited by anything other than available cluster resources. The algorithm makes two passes through the data: one to collect the dependent values, and another to calculate the correlations.
Input
A single tabular data set that contains key-value pairs of variables and values in stacked format, with variable_names, continuous_values, and categorical_values, and row_id columns.
The operation checks for validity of the dependent variable specification. See the Algorithm section for more information.
- If the dependent variable is categorical, then it should be in a categorical values column and have discrete values (string, long, int).
- If the dependent variable is continuous, then use the operator Wide Data Variable Selector - Correlations.
If there are not enough cases to calculate correlation for a variable (at least 2), then the operation returns NaN.
If there are not enough cases to calculate t statistic and p value (at least 3), then the operation returns 0 and 1, respectively.
Configuration
| Parameter | Description |
|---|---|
| Notes | Notes or helpful information about this operator's parameter settings. When you enter content in the Notes field, a yellow asterisk appears on the operator. |
| Dependent Variable Name | The name of the dependent variable against which the correlation is computed. The dependent variable must be categorical. If it is continuous, then use the operator
Wide Data Variable Selector - Correlations.
Required. |
| Variables Column | The name of the column that contains the dependent variable. |
| Continuous Values Column | The name of the column that contains continuous predictor values. |
| Categorical Values Column | The name of the column that contains the categorical predictor values. Required. |
| Row ID Column | The name of the column that contains the row ID numbers. Required. |
| Number of Bins | The number of bins used for the correlation. The default is 10. |
| Chi Square Output | Can be one of the following:
|
| Output Directory | The location to store the output files. |
| Output Name | The name to contain the results. |
| Overwrite Output | Specifies whether to delete existing data at that path.
|
| Storage Format | Select the format in which to store the results. The storage format is determined by your type of operator.
Typical formats are Avro, CSV, TSV, or Parquet. |
| Compression | Select the type of compression for the output.
Available Parquet compression options.
Available Avro compression options.
|
| Advanced Spark Settings Automatic Optimization |
|
Output
Example
The following example shows the relationship between a wide table and the stacked table input the operator requires.
