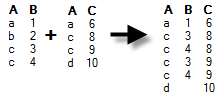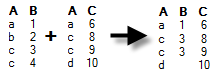
In the examples of the different join methods below, two data tables are matched using the identifiers in the "A" column of both data tables. The table on the left is "the old data" and the table in the middle is "the new data". The result after the join is after the arrow.
Option |
Description |
Columns
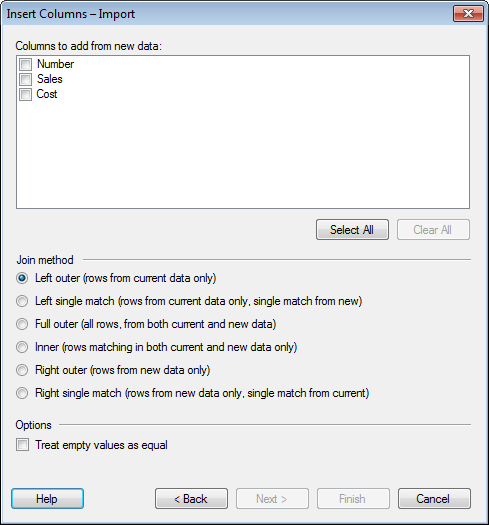
to add from new data |
Lists all columns in the new data that can be added to the current data table. Only columns that have not been used in a matching in the previous step are available. Select the check box for all columns you wish to add. |
Select
All |
Selects the check boxes for all available columns. |
Clear
All |
Clears the check boxes for all available columns. |
Join
method |
|
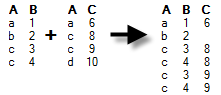
Left
outer |
Data will be kept (and columns added) only for rows that are available in the current data table. If additional rows exist in the new data, they will not be added to the current data table. If there are duplicates of the identifiers then there will be one row for each combination of values. Example:
|
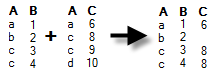
Left
single match |
Data will be kept (and columns added) only for rows that are available in the current data table. If additional rows exist in the new data, they will not be added to the current data table. If there are duplicates of the identifiers, only one value from the new data will be kept, and added to the existing rows. Example:
|
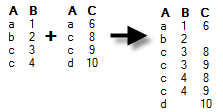
Full
outer |
Data will be kept (and columns added) for all rows available in any of the data tables. If additional rows exist in the new data, they will be added to the current data table. If there are duplicates of the identifiers then there will be one row for each combination of values. Example:
|
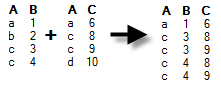
Inner |
Data will be kept (and columns added) only for rows that are available in both the current and the new data. If the new data contains fewer rows than the current data table, rows will be removed from the current data table after this operation. If there are duplicates of the identifiers then there will be one row for each combination of values. Example:
|
Right
outer |
Data will be kept (and columns added) only for rows that are available in the new data. If the new data contains fewer rows than the current data table, rows will be removed from the current data table after this operation. If there are duplicates of the identifiers then there will be one row for each combination of values. Example:
|
Right
single match |
Data will be kept (and columns added) only for rows that are available in the new data. If the new data contains fewer rows than the current data table, rows will be removed from the current data table after this operation. If there are duplicates of the identifiers, only one value from the old data will be kept and repeated for all instances of that identifier. Example:
|
Options |
|
Treat
empty values as equal |
Allows you to match on empty values. For example, this may be useful in cases where multiple key columns are used to match rows and a value is missing in one of the key columns. |
Finish |
Adds the selected columns to the selected data table in Spotfire. |
See also:
Details on Insert Columns – Select Source
Details on Insert Columns – Match Columns