Structural relations are used to combine different tables from a data source into a single view in Spotfire, which in turn can be used to create a data table.
To reach the New Relation dialog when working with a shared connection in the library:
Select Tools > Manage Data Connections.
Click on the connection of interest and click Edit.
On the General tab, click Edit... .
Under Relations, click New....
To reach the New Relation dialog when working with an embedded connection in an analysis:
Select Edit > Data Connection Properties.
In the list of Connections, click to select the connection of interest.
Click on Settings....
On the General tab, click Edit....
Response: The Views in Connection dialog is displayed.
Under Relations, click New....
Comment: You can only edit data tables for data connections that are embedded in the current analysis by using these steps. For shared library connections it is recommended to use the Manage Data Connections tool as described above instead.
To reach the Edit Relation dialog:
Open the Views in Connection dialog. See above.
In the Available tables in database list, locate the table with the relation you want to edit, and select it in the list.
Response: The Edit... button is enabled.
Click Edit....
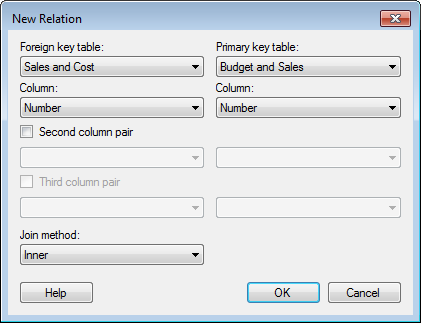
Option |
Description |
Lists all tables currently available. Select one of the tables for which you wish to define a relation. |
|
Column |
Lists all columns available in the foreign key table. Select the column to be used in the matching of rows. |
Lists all tables currently available. Select the table you wish to relate to the previously selected foreign key table. |
|
Column |
Lists all columns available in the primary key table. Select the column to be used in the matching of rows. |
Second
column pair |
Select this check box if you want to use a second pair of columns to match the tables. |
Third
column pair |
Select this check box if you want to use a third pair of columns to match the tables. |
Join
method |
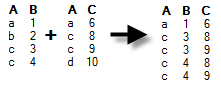
Lets you specify the join method to use in the relation. By choosing a suitable join type you may improve the performance of the data source. All of the examples below assume a join set up using the A columns. By default, another A column is created with the joined values, but you can always clear the check box for the duplicate column in the Views in Connection dialog. Note that all join methods are not supported by all data connectors. Inner – Data will be kept (and columns may be added depending on how data is modelled) only for rows that are available in both the foreign key table and the primary key table. If the foreign key table contains fewer rows than the primary key table, rows will be removed from the primary key table after this operation. If there are duplicates of the identifiers then there will be one row for each combination of values.
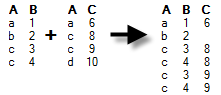
Left outer – Data will be kept (and columns may be added depending on how data is modelled) only for rows that are available in the foreign key table. If additional rows exist in the primary key table, they will not be added to the foreign key table. If there are duplicates of the identifiers then there will be one row for each combination of values. This is the default join type, which also was used in all relations in previous versions of the product.
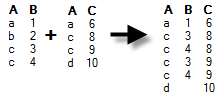
Right outer – Data will be kept (and columns may be added depending on how data is modelled) only for rows that are available in the foreign key table. If the foreign key table contains fewer rows than the primary key table, rows will be removed from the primary key table after this operation. If there are duplicates of the identifiers then there will be one row for each combination of values.
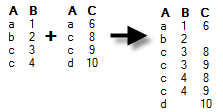
Full outer – Data will be kept (and columns may be added depending on how data is modelled) for all rows available in any of the tables. If additional rows exist in the foreign key table, they will be added to the primary key table. If there are duplicates of the identifiers then there will be one row for each combination of values.
|
See also:
Details on Data Tables in Connection