Funciones estadísticas
La lista enumera las funciones estadísticas que puede utilizar en expresiones.
| Función | Descripción |
|---|---|
| Avg(Arg1, ...) | Devuelve el promedio (media aritmética) de los argumentos. Tanto los argumentos como el resultado son reales. Si se da un argumento, el resultado es el promedio de todas las filas. Si se da más de un argumento, el resultado es el promedio de cada fila. Los argumentos nulos se ignoran y no contribuyen al promedio. Ejemplos: Avg([Column]) Avg(2,-3,4)→ 1 Avg(-1) → -1 Avg(1.5, -2, 3.5) → 1 Avg(1, null, 3) → 2 Avg(null) →(Empty) |
| ChiDist(Arg1) | Devuelve el valor p de chi cuadrado (extremo superior) del argumento. Ejemplo: ChiDist(x, deg_freedom) ChiDist(7.377759, 2) → 0,025 |
| ChiInv(Arg1) | Devuelve el valor de cuantil de chi cuadrado (extremo superior) del argumento. Ejemplo: ChiInv(p, deg_freedom) ChiInv(0.025, 2) → 7,377759 |
| Count(Arg1) | Calcula el número de valores no vacíos en la columna del argumento, o bien, si no se especifica ningún argumento, el número total de filas. Ejemplo: Count([Column]) |
| CountBig(Arg1) | Calcula el número de valores no vacíos en la columna del argumento, o bien, si no se especifica ningún argumento, el número total de filas. Esta función devuelve un valor LongInteger. Ejemplo: CountBig([Column]) |
| Covariance(Arg1, Arg2) | Calcula la covarianza de dos columnas indicadas como argumentos. Ejemplo: Covariance([Column1], [Column2]) |
| FDist(Arg1) | Devuelve el valor p de F (extremo superior) del argumento. Ejemplo: FDist(x, deg_freedom1, deg_freedom2) FDist(6.936728, 1, 10) → 0,025 |
| FInv(Arg1) | Devuelve el valor del cuantil de F del extremo superior del argumento. Ejemplo: FInv(p, deg_freedom1, deg_freedom2) FInv(0.025, 1, 10) → 6,936728 |
| First(Arg1) | Devuelve el primer valor válido basado en el orden físico de las filas de datos de la columna de argumentos. Ejemplo: First([Column]) |
| GeometricMean() | Calcula el valor de media geométrica. Si algún valor de entrada es negativo, el resultado será el valor Vacío. Si algún valor de entrada es igual a cero, el resultado será cero. Ejemplo: GeometricMean([Sales]) |
| IQR(Arg1) | Calcula la diferencia de valor de Q3-Q1 o el percentil 75 menos el 25. IQR también recibe el nombre de dispersión h. Ejemplo: IQR([Column]) |
| L95(Arg1) | Calcula el punto final inferior del 95 % del intervalo de confianza. Ejemplo: L95([Column]) |
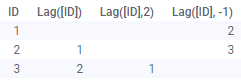
| Lag(Arg1, Arg2) | Desplaza los valores de una columna hacia abajo según un número específico de pasos. El primer argumento es la columna que se va a desplazar. El segundo argumento (opcional) es el número de pasos. La configuración predeterminada es 1. Si se utiliza un número negativo de pasos, los valores se desplazarán en la dirección opuesta, vea la imagen a continuación. Ejemplos: Lag([Column]) Lag([Column],3) Tenga en cuenta que la función Lag se aplica a los datos en el orden en el que estos se cargaron; la función no tiene en cuenta la clasificación en visualizaciones, y los cambios realizados en los datos (por ejemplo, durante la recarga) pueden dar como resultado valores diferentes para las distintas filas. |
| Last(Arg1) | Devuelve el último valor válido basado en el orden físico de las filas de datos de la columna de argumentos. Ejemplo: Last([Column]) |
| LastValueForMax(Arg1, Arg2) | Devuelve el valor de la columna 2 para el valor máximo de la columna 1. Si existe más de una columna cuyo valor máximo sea 1, el resultado será el valor de la última fila máxima. Consulte también ValueForMax. Ejemplo: LastValueForMax([Column 1], [Column 2]) |
| LastValueForMin(Arg1, Arg2) | Devuelve el valor de la columna 2 para el valor mínimo de la columna 1. Si existe más de una columna cuyo valor mínimo sea 1, el resultado será el valor de la última fila mínima. Consulte también ValueForMin. Ejemplo: LastValueForMin([Column 1], [Column 2]) |
| LAV(Arg1) | Calcula el valor adyacente más bajo. Ejemplo: LAV([Column]) |
| Lead(Arg1, Arg2) | Desplaza los valores de una columna hacia arriba según un número específico de pasos. El primer argumento es la columna que se va a desplazar. El segundo argumento (opcional) es el número de pasos. La configuración predeterminada es 1. Si se utiliza un número negativo de pasos, los valores se desplazarán en la dirección opuesta, vea la imagen a continuación. Ejemplos: Lead([Column]) Lead([Column],3) Tenga en cuenta que la función Lead se aplica a los datos en el orden en el que estos se cargaron; la función no tiene en cuenta la clasificación en visualizaciones, y los cambios realizados en los datos (por ejemplo, durante la recarga) pueden dar como resultado valores diferentes para las distintas filas. |
| LIF(Arg1) | Calcula el límite interior inferior. Se trata del umbral que se encuentra en Q1 - (1.5*IQR). Ejemplo: LIF([Column]) |
| LOF(Arg1) | Calcula el límite exterior inferior. Se trata del umbral que se encuentra en Q1 - (3*IQR). Ejemplo: LOF([Column]) |
| Max(Arg1, ...) | Calcula el valor máximo. Si se da un argumento, el resultado es el máximo de toda la columna. Si se da más de un argumento, el resultado es el máximo de cada fila. Tanto el argumento como el resultado son reales. Se ignorarán los argumentos nulos. Ejemplos: Max([Column]) Max(-1) → -1 Max (1.5, -2, 3) → 3 Max (1, null, 3) → 3 Max (null) →(Empty) |
| MeanDeviation(Arg1, ...) | Calcula el valor de desviación media (desviación absoluta promedio). Si se da un argumento, el resultado es la desviación media de todas las filas. Si se da más de un argumento, el resultado es la desviación media de cada fila. Ejemplos: MeanDeviation([Column]) MeanDeviation(2,-3,4) → 2,67 |
| Median(Arg1) | Calcula la mediana del argumento. Si se da un argumento, el resultado es la mediana de todas las filas. Si se da más de un argumento, el resultado es la mediana de cada fila. Ejemplos: Median([Column]) Median(2,-3,4) |
| MedianAbsoluteDeviation(Arg1, ...) | Calcula la desviación absoluta media (DAM). Si se da un argumento, el resultado es la desviación absoluta media de todas las filas. Si se da más de un argumento, el resultado es la desviación absoluta media de cada fila. Ejemplos: MedianAbsoluteDeviation([Sales]) MedianAbsoluteDeviation(2,-3,4) |
| Min(Arg1, ...) | Calcula el valor mínimo. Si se da un argumento, el resultado es el mínimo de toda la columna. Si se da más de un argumento, el resultado es el mínimo de cada fila. Tanto el argumento como el resultado son reales. Se ignorarán los argumentos nulos. Ejemplos: Min([Column]) Min(-1) → -1 Min (1.5, -2, 3) → -2 Min (1, null, 3) → 1 Min (null) →(Empty) |
| NormDist(Arg1) | Devuelve el valor p normal (extremo superior) del argumento. Si no lo especifica, el predeterminado será que la media equivalga a cero, y la desviación estándar, a uno. Ejemplo: NormDist(x, mean, standard_dev) NormDist(1.96) → 0,025 |
| NormInv(Arg1) | Devuelve el valor de cuantil normal (extremo superior) del argumento. Si no lo especifica, el predeterminado será que la media equivalga a cero, y la desviación estándar, a uno. Ejemplo: NormInv(p, mean, standard_dev) NormInv(0.025) → 1,96 |
| NthLargest(Arg1, Arg2) | El enésimo (n.°) valor más grande. El primer argumento es la columna que se va a analizar. El segundo argumento es el valor de n. Si n es mayor que el número de valores de la columna, se devuelve el valor más pequeño. Ejemplo: NthLargest([Column], 10) |
| NthSmallest(Arg1, Arg2) | El enésimo (n.°) valor más pequeño. El primer argumento es la columna que se va a analizar. El segundo argumento es el valor de n. Si n es mayor que el número de valores de la columna, se devuelve el valor más grande. Ejemplo: NthSmallest([Column], 10) |
| Outliers(Arg1) | Recuento de valores exteriores. Calcula el número de valores mayores que el valor adyacente más alto o menores que el valor adyacente más bajo. Ejemplo: Outliers([Column]) |
| P10(Arg1) | El percentil 10 es el valor en el que el 10 por ciento de los valores de datos son iguales o inferiores al valor. Ejemplo: P10([Column]) |
| P90(Arg1) | El percentil 90 es el valor en el que el 90 por ciento de los valores de datos son iguales o inferiores al valor. Ejemplo: P90([Column]) |
| PctOutliers(Arg1) | Indica el recuento de valores exteriores. Calcula el porcentaje de valores mayores que el valor adyacente más alto o menores que el valor adyacente más bajo. Ejemplo: PctOutliers([Column]) |
| Percent(Arg1, Arg2) | El porcentaje es el valor calculado de un determinado porcentaje sobre el valor mínimo dentro del rango de valores (valor máximo - valor mínimo). El primer argumento es la columna que se va a analizar, mientras que el segundo argumento es el porcentaje. Ejemplo: Percent([Column], 15.0) |
| Percentile(Arg1, Arg2) | Hace referencia a los percentiles, que son aquellos en los que un tanto por ciento de los valores de datos son iguales o inferiores al valor. El primer argumento es la columna que se va a analizar, mientras que el segundo argumento es el porcentaje. Ejemplo: Percentile([Column], 15.0) |
| Q1(Arg1) | Calcula el primer cuartil. Ejemplo: Q1([Column]) |
| Q3(Arg1) | Calcula el tercer cuartil. Ejemplo: Q3([Column]) |
| Range(Arg1) | Indica el rango entre el valor mayor y el menor de la columna. El resultado se presentará como un valor real o un intervalo de tiempo, en función del tipo de datos del argumento. Ejemplo: Range([Column]) |
| StdDev(Arg1) | Calcula la desviación estándar. Ejemplo: StdDev([Column]) |
| StdErr(Arg1) | Calcula el error estándar. Ejemplo: StdErr([Column]) |
| TDist(Arg1) | Devuelve el valor p de t (extremo superior) del argumento. Ejemplo: TDist(x, deg_freedom) TDist(4.302653, 2) → 0,025 |
| TERR_Binary | Llama al motor de TIBCO Enterprise Runtime para R y devuelve una salida del tipo de datos especificado que contiene el mismo número de filas que la entrada. El primer argumento es un script y los siguientes argumentos son los argumentos para el script. La columna devuelta debe tener el mismo número de filas que la entrada. Se necesita al menos un argumento distinto del script. Las entradas se colocarán en variables denominadas input1, input2, (...) inputN, y la salida se debe colocar en una variable denominada output. Ejemplos: TERR_Real("output <- input1*100 + input2", [Record No], [Sales]) TERR_String("output <- input1", [String Column]) |
| TERR_Boolean | Consulte el TERR_Binary anterior. |
| TERR_DateTime | Consulte el TERR_Binary anterior. |
| TERR_Integer | Consulte el TERR_Binary anterior. |
| TERR_Real | Consulte el TERR_Binary anterior. |
| TERR_String | Consulte el TERR_Binary anterior. |
| TERRAggregation_Binary | Llama al motor de TIBCO Enterprise Runtime para R y devuelve una salida del tipo de datos especificado. El primer argumento es un script y los siguientes argumentos son los argumentos para el script. El script debe devolver un único valor agregado. Se necesita al menos un argumento distinto del script. Las entradas se colocarán en variables denominadas input1, input2, (...) inputN, y la salida se debe colocar en una variable denominada output. Ejemplos: TERRAggregation_Real("output <- median(input1) + median(input2)", [X], [Y]) TERRAggregation_String("output <- input1[1]", [Customer Name]) |
| TERRAggregation_Boolean | Consulte TERRAggregation_Binary anterior. |
| TERRAggregation_DateTime | Consulte TERRAggregation_Binary anterior. |
| TERRAggregation_Integer | Consulte TERRAggregation_Binary anterior. |
| TERRAggregation_Real | Consulte TERRAggregation_Binary anterior. |
| TERRAggregation_String | Consulte TERRAggregation_Binary anterior. |
| TInv(Arg1) | Devuelve el valor de cuantil de t (extremo superior) del argumento. Ejemplos: TInv(p, deg_freedom) TInv(0.025, 2) → 4,302653 |
| TrimmedMean(Arg1, Arg2) | Calcula el valor de media truncada (promedio truncado). El primer argumento es la columna que se va a analizar. El segundo argumento es el porcentaje del número de valores que se van a excluir del cálculo. Si el valor truncado se define con el valor 10%, el 5% de los valores más altos y el 5% de los valores más bajos se excluirán de la media calculada. Ejemplo: TrimmedMean([Sales], 10) |
| U95(Arg1) | Calcula el punto final superior del 95 % del intervalo de confianza. Ejemplo: U95([Column]) |
| UAV(Arg1) | Calcula el valor adyacente más alto. Ejemplo: UAV([Column]) |
| UIF(Arg1) | Calcula el límite interior superior. Se trata del umbral que se encuentra en Q3 + (1.5*IQR). Ejemplo: UIF([Column]) |
| UniqueCount(Arg1) | Calcula el número de valores exclusivos no vacíos de la columna del argumento. Ejemplo: UniqueCount([Column]) |
| UOF(Arg1) | Calcula el límite exterior superior. Se trata del umbral que se encuentra en Q3 + (3*IQR). Ejemplo: UOF([Column]) |
| ValueForMax(Arg1, Arg2) | Devuelve el valor de la columna 2 para el valor máximo de la columna 1. Si existe más de una columna cuyo valor máximo sea 1, el resultado será el valor de la primera fila máxima. Consulte también LastValueForMax. Ejemplo: ValueForMax([Column 1], [Column 2]) |
| ValueForMin(Arg1, Arg2) | Devuelve el valor de la columna 2 para el valor mínimo de la columna 1. Si existe más de una columna cuyo valor mínimo sea 1, el resultado será el valor de la primera fila mínima. Consulte también LastValueForMin. Ejemplo: ValueForMin([Column 1], [Column 2]) |
| Var(Arg1) | Calcula la varianza. Ejemplo: Var([Column]) |
| WeightedAverage(Arg1, Arg2) | Calcula el promedio ponderado de dos columnas. Arg1 es la columna de ponderación y Arg2, la columna de valores. Ejemplo: WeightedAverage([Column1],[Column2]) |

Sugerencia: La palabra clave DISTINCT se puede usar para devolver un resultado solo con valores únicos. Por ejemplo, Avg(DISTINCT[Column]) devuelve la media de los valores únicos en lugar de la de todos los valores de la columna especificada. UniqueCount([Column]) es el equivalente de Count(DISTINCT[Column]).
Consulte también Funciones.