Статистические функции
Список статистических функций, которые можно использовать в выражениях.
| Функция | Описание |
|---|---|
| Avg(Arg1, ...) | Возвращает среднее (арифметическое среднее) значение аргументов. Аргументы и результат являются значениями действительного типа. Если дан один аргумент, то результатом будет среднее всех строк. Если дано несколько аргументов, то результатом будет среднее для каждой строки. Аргументы со значением NULL пропускаются и не участвуют в вычислении среднего значения. Примеры. Avg([Column]) Avg(2,-3,4)→ 1 Avg(-1) → -1 Avg(1.5, -2, 3.5) → 1 Avg(1, null, 3) → 2 Avg(null) →(Empty) |
| ChiDist(Arg1) | Возвращает p-значение (ограниченное сверху) хи-квадрата аргумента. Пример. ChiDist(x, deg_freedom) ChiDist(7.377759, 2) → 0,025 |
| ChiInv(Arg1) | Возвращает значение квантиля (ограниченное сверху) хи-квадрата аргумента. Пример. ChiInv(p, deg_freedom) ChiInv(0.025, 2) → 7,377759 |
| Count(Arg1) | Вычисляет число непустых значений в столбце аргументов либо, если аргументы не заданы, общее число строк. Пример. Count([Column]) |
| CountBig(Arg1) | Вычисляет число непустых значений в столбце аргументов либо, если аргументы не заданы, общее число строк. Эта функция возвращает LongInteger. Пример. CountBig([Column]) |
| Covariance(Arg1, Arg2) | Вычисляет смешанный момент второго порядка двух столбцов, данных в качестве аргументов. Пример. Covariance([Column1], [Column2]) |
| FDist(Arg1) | Возвращает p-значение, ограниченное сверху F, аргумента. Пример. FDist(x, deg_freedom1, deg_freedom2) FDist(6.936728, 1, 10) → 0,025 |
| FInv(Arg1) | Возвращает ограниченное сверху значение квантиля F аргумента. Пример. FInv(p, deg_freedom1, deg_freedom2) FInv(0.025, 1, 10) → 6,936728 |
| First(Arg1) | Возвращает первое допустимое значение по физическому порядку строк данных в столбце аргументов. Пример. First([Column]) |
| GeometricMean() | Вычисляет среднегеометрическое значение. Если какое-либо входное значение является отрицательным, в результате будет выдано значение Empty (Пусто). Если какое-либо входное значение равно нулю, в результате будет выдано значение нуль. Пример. GeometricMean([Sales]) |
| IQR(Arg1) | Вычисляет разницу значений Q3–Q1 или 75-й минус 25-й процентиль. IQR также именуется как H-разворот. Пример. IQR([Column]) |
| L95(Arg1) | Вычисляет нижнюю конечную точку 95 % доверительного интервала. Пример. L95([Column]) |
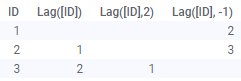
| Lag(Arg1, Arg2) | Смещает значения в столбце вниз на указанное количество шагов. Первым аргументом является столбец для выполнения смещения. Второй (дополнительный) аргумент — это число шагов. Значение по умолчанию — 1. Если используется отрицательное число шагов, тогда значения смещаются в противоположном направлении (см. изображение ниже). Примеры. Lag([Column]) Lag([Column],3) Обратите внимание, что функция Lag применяется к данным в том порядке, в котором данные были загружены. Функция не учитывает сортировку в визуализациях и любые изменения данных (например, во время перезагрузки) могут привести к различным значениям для различных строк. |
| Last(Arg1) | Возвращает последнее допустимое значение по физическому порядку строк данных в столбце аргументов. Пример. Last([Column]) |
| LastValueForMax(Arg1, Arg2) | Возвращает значение столбца 2 для максимального значения столбца 1. Если максимальных значений столбца 1 несколько, то результатом будет значение последней максимальной строки. См. также раздел ValueForMax. Пример. LastValueForMax([Column 1], [Column 2]) |
| LastValueForMin(Arg1, Arg2) | Возвращает значение столбца 2 для минимального значения столбца 1. Если минимальных значений столбца 1 несколько, то результатом будет значение последней минимальной строки. См. также раздел ValueForMin. Пример. LastValueForMin([Column 1], [Column 2]) |
| LAV(Arg1) | Вычисляет нижнее смежное значение. Пример. LAV([Column]) |
| Lead(Arg1, Arg2) | Смещает значения в столбце вверх на указанное количество шагов. Первым аргументом является столбец для выполнения смещения. Второй (дополнительный) аргумент — это число шагов. Значение по умолчанию — 1. Если используется отрицательное число шагов, тогда значения смещаются в противоположном направлении (см. изображение ниже). Примеры. Lead([Column]) Lead([Column],3) Обратите внимание, что функция Lead применяется к данным в том порядке, в котором данные были загружены. Функция не учитывает сортировку в визуализациях и любые изменения данных (например, во время перезагрузки) могут привести к различным значениям для различных строк. |
| LIF(Arg1) | Вычисляет нижнее внутреннее ограждение. Это пороговое значение, расположенное на Q1 - (1.5*IQR). Пример. LIF([Column]) |
| LOF(Arg1) | Вычисляет нижнее внешнее ограждение. Это пороговое значение, расположенное на Q1 - (3*IQR). Пример. LOF([Column]) |
| Max(Arg1, ...) | Вычисляет максимальное значение. Если дан один аргумент, то результатом будет максимум всего столбца. Если дано несколько аргументов, то результатом будет максимум для каждой строки. Аргумент и результат являются значениями действительного типа. Аргументы со значением NULL пропускаются. Примеры. Max([Column]) Max(-1) → -1 Max (1.5, -2, 3) → 3 Max (1, null, 3) → 3 Max (null) →(Empty) |
| MeanDeviation(Arg1, ...) | Вычисляет значение среднего отклонения (среднее абсолютное отклонение). Если дан один аргумент, то результатом будет среднее отклонение всех строк. Если дано несколько аргументов, то результатом будет среднее отклонение для каждой строки. Примеры. MeanDeviation([Column]) MeanDeviation(2,-3,4) → 2,67 |
| Median(Arg1) | Вычисляет медиану аргумента. Если дан один аргумент, то результатом будет медиана всех строк. Если дано несколько аргументов, то результатом будет медиана для каждой строки. Примеры. Median([Column]) Median(2,-3,4) |
| MedianAbsoluteDeviation(Arg1, ...) | Вычисляет значение медианного абсолютного отклонения. Если дан один аргумент, то результатом будет медианное абсолютное отклонение всех строк. Если дано несколько аргументов, то результатом будет медианное абсолютное отклонение для каждой строки. Примеры. MedianAbsoluteDeviation([Sales]) MedianAbsoluteDeviation(2,-3,4) |
| Min(Arg1, ...) | Вычисляет минимальное значение. Если дан один аргумент, то результатом будет минимум всего столбца. Если дано несколько аргументов, то результатом будет минимум для каждой строки. Аргумент и результат являются значениями действительного типа. Аргументы со значением NULL пропускаются. Примеры. Min([Column]) Min(-1) → -1 Min (1.5, -2, 3) → -2 Min (1, null, 3) → 1 Min (null) →(Empty) |
| NormDist(Arg1) | Возвращает нормальное p-значение (ограниченное сверху) аргумента. Если не указать их самостоятельно, то по умолчанию будет использовано среднее = 0 и стандартное отклонение = 1. Пример. NormDist(x, mean, standard_dev) NormDist(1.96) → 0,025 |
| NormInv(Arg1) | Возвращает нормальное значение квантиля (ограниченное сверху) аргумента. Если не указать их самостоятельно, то по умолчанию будет использовано среднее = 0 и стандартное отклонение = 1. Пример. NormInv(p, mean, standard_dev) NormInv(0.025) → 1,96 |
| NthLargest(Arg1, Arg2) | n-е наибольшее значение. Первым аргументом является анализируемый столбец, а вторым — значение n. Если n больше, чем число значений в столбце, возвращается наименьшее значение. Пример. NthLargest([Column], 10) |
| NthSmallest(Arg1, Arg2) | n-е наименьшее значение. Первым аргументом является анализируемый столбец, а вторым — значение n. Если n больше, чем число значений в столбце, возвращается наибольшее значение. Пример. NthSmallest([Column], 10) |
| Outliers(Arg1) | Количество внешних значений. Вычисляет число значений, которые больше, чем верхнее смежное значение, или меньше, чем нижнее смежное значение. Пример. Outliers([Column]) |
| P10(Arg1) | 10-й процентиль — это значение, при котором 10 процентов значений данных меньше значения или равны ему. Пример. P10([Column]) |
| P90(Arg1) | 90-й процентиль — это значение, при котором 90 процентов значений данных меньше значения или равны ему. Пример. P90([Column]) |
| PctOutliers(Arg1) | Процентиль внешних значений. Вычисляет процент значений, которые больше, чем верхнее смежное значение, или меньше, чем нижнее смежное значение. Пример. PctOutliers([Column]) |
| Percent(Arg1, Arg2) | Процент — значение, вычисленное в виде определенного процента выше минимального значения в диапазоне значение (максимальное значение — минимальное значение). Первым аргументом является анализируемый столбец, а вторым — процент. Пример. Percent([Column], 15.0) |
| Percentile(Arg1, Arg2) | Процентиль — значение, при котором определенный процент значений данных меньше значения или равен ему. Первым аргументом является анализируемый столбец, а вторым — процент. Пример. Percentile([Column], 15.0) |
| Q1(Arg1) | Вычисляет первый квартиль. Пример. Q1([Column]) |
| Q3(Arg1) | Вычисляет третий квартиль. Пример. Q3([Column]) |
| Range(Arg1) | Диапазон между наибольшим и наименьшим значениями в столбце. Результат будет представлен в виде действительного значения или TimeSpan в зависимости от типа данных аргумента. Пример. Range([Column]) |
| StdDev(Arg1) | Вычисляет стандартное отклонение. Пример. StdDev([Column]) |
| StdErr(Arg1) | Вычисляет среднеквадратическую ошибку. Пример. StdErr([Column]) |
| TDist(Arg1) | Возвращает p-значение (ограниченное сверху) t аргумента. Пример. TDist(x, deg_freedom) TDist(4.302653, 2) → 0,025 |
| TERR_Binary | Вызывает модуль TIBCO Enterprise Runtime for R и возвращает выходные значения указанного типа с таким же количеством строк, что и во входных данных. Первый аргумент — скрипт, последующие аргументы — аргументы скрипта. В возвращенном и входном столбце должно быть одинаковое количество строк. Кроме скрипта требуется указать еще хотя бы один аргумент. Вводные данные указываются вместо переменных input1, input2, ...inputN, а выходные данные — вместо переменной output. Примеры. TERR_Real("output <- input1*100 + input2", [Record No], [Sales]) TERR_String("output <- input1", [String Column]) |
| TERR_Boolean | См. TERR_Binary выше. |
| TERR_DateTime | См. TERR_Binary выше. |
| TERR_Integer | См. TERR_Binary выше. |
| TERR_Real | См. TERR_Binary выше. |
| TERR_String | См. TERR_Binary выше. |
| TERRAggregation_Binary | Вызывает модуль TIBCO Enterprise Runtime for R и возвращает данные указанного типа. Первый аргумент — скрипт, последующие аргументы — аргументы скрипта. Скрипт должен вернуть одно агрегированное значение. Кроме скрипта требуется указать еще хотя бы один аргумент. Вводные данные указываются вместо переменных input1, input2, ...inputN, а выходные данные — вместо переменной output. Примеры. TERRAggregation_Real("output <- median(input1) + median(input2)", [X], [Y]) TERRAggregation_String("output <- input1[1]", [Customer Name]) |
| TERRAggregation_Boolean | См. TERRAggregation_Binary выше. |
| TERRAggregation_DateTime | См. TERRAggregation_Binary выше. |
| TERRAggregation_Integer | См. TERRAggregation_Binary выше. |
| TERRAggregation_Real | См. TERRAggregation_Binary выше. |
| TERRAggregation_String | См. TERRAggregation_Binary выше. |
| TInv(Arg1) | Возвращает значение квантиля (ограниченное сверху) t аргумента. Примеры. TInv(p, deg_freedom) TInv(0.025, 2) → 4,302653 |
| TrimmedMean(Arg1, Arg2) | Вычисляет усеченное среднее значение. Первым аргументом является анализируемый столбец, а вторым — число исключаемых из вычисления значений (выраженное в процентах). Если в качестве значения усечения указать 10 %, то из вычисления среднего будут исключены 5 % наибольших и 5 % наименьших значений. Пример. TrimmedMean([Sales], 10) |
| U95(Arg1) | Вычисляет верхнюю конечную точку 95 % доверительного интервала. Пример. U95([Column]) |
| UAV(Arg1) | Вычисляет верхнее смежное значение. Пример. UAV([Column]) |
| UIF(Arg1) | Вычисляет верхнее внутреннее ограждение. Это пороговое значение, расположенное на Q3 + (1.5*IQR). Пример. UIF([Column]) |
| UniqueCount(Arg1) | Вычисляет число уникальных, непустых значений в столбце аргумента. Пример. UniqueCount([Column]) |
| UOF(Arg1) | Вычисляет верхнее внешнее ограждение. Это пороговое значение, расположенное на Q3 + (3*IQR). Пример. UOF([Column]) |
| ValueForMax(Arg1, Arg2) | Возвращает значение столбца 2 для максимального значения столбца 1. Если максимальных значений столбца 1 несколько, то результатом будет значение первой максимальной строки. См. также раздел LastValueForMax. Пример. ValueForMax([Column 1], [Column 2]) |
| ValueForMin(Arg1, Arg2) | Возвращает значение столбца 2 для минимального значения столбца 1. Если минимальных значений столбца 1 несколько, то результатом будет значение первой минимальной строки. См. также раздел LastValueForMin. Пример. ValueForMin([Column 1], [Column 2]) |
| Var(Arg1) | Вычисляет дисперсию. Пример. Var([Column]) |
| WeightedAverage(Arg1, Arg2) | Вычисляет взвешенное среднее двух столбцов. Arg1 — это столбец веса, а Arg2 — столбец значений. Пример. WeightedAverage([Column1],[Column2]) |

Совет. Ключевое слово DISTINCT можно указывать, чтобы возвратить результат только по уникальным значениям. Например, Avg(DISTINCT[Column]) возвратит среднее уникальных, а не всех значений из указанного столбца. UniqueCount([Column]) является эквивалентом Count(DISTINCT[Column]).
Также см. раздел Функции.