統計関数
式に使用できる統計関数のリストを示します。
| 関数 | 説明 |
|---|---|
| Avg(Arg1, ...) | 引数の平均 (算術平均) を返します。引数および結果は実数型です。1 つの引数が指定された場合は、すべてのローの平均値が計算されます。複数の引数が指定された場合は、各ローの平均値が計算されます。NULL の引数は無視され、平均には含められません。 例: Avg([Column]) Avg(2,-3,4)→ 1 Avg(-1)→ -1 Avg(1.5, -2, 3.5)→ 1 Avg(1, null, 3)→ 2 Avg(null)→(Empty) |
| ChiDist(Arg1) | 引数の (上尾の) カイ 2 乗 p-value を返します。 例: ChiDist(x, deg_freedom) ChiDist(7.377759, 2)→ 0.025 |
| ChiInv(Arg1) | 引数の (上尾の) カイ 2 乗変位値を返します。 例: ChiInv(p, deg_freedom) ChiInv(0.025, 2)→ 7.377759 |
| Count(Arg1) | 引数のカラム内の空でない値の数を計算するか、引数が指定されていない場合は、ローの合計数を計算します。 例: Count([Column]) |
| CountBig(Arg1) | 引数のカラム内の空でない値の数を計算するか、引数が指定されていない場合は、ローの合計数を計算します。この関数は LongInteger を返します。 例: CountBig([Column]) |
| Covariance(Arg1, Arg2) | 引数として指定された 2 つのカラムの共分散を計算します。 例: Covariance([Column1], [Column2]) |
| FDist(Arg1) | 引数の (上尾の) F p-value を返します。 例: FDist(x, deg_freedom1, deg_freedom2) FDist(6.936728, 1, 10)→ 0.025 |
| FInv(Arg1) | 引数の上尾の F 変位値を返します。 例: FInv(p, deg_freedom1, deg_freedom2) FInv(0.025, 1, 10)→ 6.936728 |
| First(Arg1) | 引数カラム内のデータのローの物理的な順序に基づいて、最初の有効値を返します。 例: First([Column]) |
| GeometricMean() | 幾何平均値を計算します。Arg1 が負の場合、結果は「空」となります。Arg1 がゼロの場合、結果はゼロとなります。 例: GeometricMean([Sales]) |
| IQR(Arg1) | Q3-Q1、または 75 番目のパーセンタイルから 25 番目のパーセンタイルを引いた値を計算します。IQR は H-spread とも呼ばれます。 例: IQR([Column]) |
| L95(Arg1) | 95% 信頼区間の下側のエンドポイントを計算します。 例: L95([Column]) |
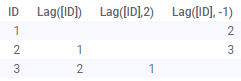
| Lag(Arg1, Arg2) | カラム内の値を指定されたステップ数だけ下方にシフトします。最初の引数はシフトするカラムです。2 つ目 (オプション) の引数は、ステップの数です。既定値は 1 です。 負のステップ数を使用すると、値は反対方向にシフトします。次の図を参照してください。 例: Lag([Column]) Lag([Column],3) Lag 関数はデータがロードされた順番でデータに適用されます。この機能はビジュアライゼーションの並べ替えを考慮に入れておらず、データの変更 (たとえば再ロード中)はすべてさまざまなローに対して異なる値をもたらす可能性があります。 |
| Last(Arg1) | 引数カラム内のデータのローの物理的な順序に基づいて、最後の有効値を返します。 例: Last([Column]) |
| LastValueForMax(Arg1, Arg2) | カラム 1 の最大値に対してカラム2 の値を返します。 カラム 1 の最大値が複数ある場合、結果は最後の最大ローの値になります。「ValueForMax」も参照してください。 例: LastValueForMax([Column 1], [Column 2]) |
| LastValueForMin(Arg1, Arg2) | カラム 1 の最小値に対してカラム 2 の値を返します。 カラム 1 の最小値が複数ある場合、結果は最後の最小ローの値になります。「ValueForMin」も参照してください。 例: LastValueForMin([Column 1], [Column 2]) |
| LAV(Arg1) | 下位隣接値を計算します。 例: LAV([Column]) |
| Lead(Arg1, Arg2) | カラム内の値を指定されたステップ数だけ上方にシフトします。最初の引数はシフトするカラムです。2 つ目 (オプション) の引数は、ステップの数です。既定値は 1 です。 負のステップ数を使用すると、値は反対方向にシフトします。次の図を参照してください。 例: Lead([Column]) Lead([Column],3) Lead 関数はデータがロードされた順番でデータに適用されます。この機能はビジュアライゼーションの並べ替えを考慮に入れておらず、データの変更 (たとえば再ロード中)はすべてさまざまなローに対して異なる値をもたらす可能性があります。 |
| LIF(Arg1) | 下側の内部フェンスを計算します。これは、Q1 - (1.5*IQR)のしきい値です。 例: LIF([Column]) |
| LOF(Arg1) | 下側の外部フェンスを計算します。これは、Q1 - (3*IQR)のしきい値です。 例: LOF([Column]) |
| Max(Arg1, ...) | 最大値を計算します。1 つの引数が指定された場合は、カラム全体の最大値が計算されます。複数の引数が指定された場合は、各ローの最大値が計算されます。引数および結果は実数型です。NULL の引数は無視されます。 例: Max([Column]) Max(-1) → -1 Max (1.5, -2, 3)→ 3 Max (1, null, 3)→ 3 Max (null)→(Empty) |
| MeanDeviation(Arg1, ...) | 平均偏差値 (平均絶対偏差、AAD) を計算します。1 つの引数が指定された場合は、すべてのローの平均偏差が計算されます。複数の引数が指定された場合は、ローごとの平均偏差が計算されます。 例: MeanDeviation([Column]) MeanDeviation(2,-3,4) → 2.67 |
| Median(Arg1) | 引数の中央値を計算します。1 つの引数が指定された場合は、すべてのローの中央値が計算されます。複数の引数が指定された場合は、ローごとの中央値が計算されます。 例: Median([Column]) Median(2,-3,4) |
| MedianAbsoluteDeviation(Arg1, ...) | 中央絶対偏差 (MAD) を計算します。1 つの引数が指定された場合は、すべてのローの中央絶対偏差が計算されます。複数の引数が指定された場合は、ローごとの中央絶対偏差が計算されます。 例: MedianAbsoluteDeviation([Sales]) MedianAbsoluteDeviation(2,-3,4) |
| Min(Arg1, ...) | 最小値を計算します。1 つの引数が指定された場合は、カラム全体の最小値が計算されます。引数が複数渡されると、結果は各ローの最小となります。引数および結果は実数型です。NULL の引数は無視されます。 例: Min([Column]) Min(-1) → -1 Min (1.5, -2, 3)→ -2 Min (1, null, 3)→ 1 Min (null) →(Empty) |
| NormDist(Arg1) | 引数の (上尾の) 通常 p-value を返します。自分で指定しない場合は、既定では平均値 =0、標準偏差 =1 になります。 例: NormDist(x, mean, standard_dev) NormDist(1.96)→ 0.025 |
| NormInv(Arg1) | 引数の (上尾の) 通常変位値を返します。自分で指定しない場合は、既定では平均値 =0、標準偏差 =1 になります。 例: NormInv(p, mean, standard_dev) NormInv(0.025)→ 1.96 |
| NthLargest(Arg1, Arg2) | n 番目に大きな値。1 つ目の引数は分析対象のカラムで、2 つ目の引数は n の値です。 n がカラム内の値の数より大きい場合は、最小値が返されます。 例: NthLargest([Column], 10) |
| NthSmallest(Arg1, Arg2) | n 番目に小さな値。1 つ目の引数は分析対象のカラムで、2 つ目の引数は n の値です。 n がカラム内の値の数より大きい場合は、最大値が返されます。 例: NthSmallest([Column], 10) |
| Outliers(Arg1) | 外側値数。上側の隣接値より大きいか下側の隣接値より小さい値の数を計算します。 例: Outliers([Column]) |
| P10(Arg1) | 10 パーセンタイルとは、全データ値の 10% がその値以下になるような値です。 例: P10([Column]) |
| P90(Arg1) | 90 パーセンタイルとは、全データ値の 90% がその値以下になるような値です。 例: P90([Column]) |
| PctOutliers(Arg1) | 外側値パーセンタイル上側の隣接値より大きいか下側の隣接値より小さい値のパーセントを計算します。 例: PctOutliers([Column]) |
| Percent(Arg1, Arg2) | パーセントは、値の範囲 (最大値から最小値) 内の最小値より上の特定のパーセントを計算した値です。1 つ目の引数は分析対象のカラムで、2 つ目の引数はパーセントです。 例: Percent([Column], 15.0) |
| Percentile(Arg1, Arg2) | パーセンタイルとは、全データ値の特定のパーセントがその値以下になるような値です。1 つ目の引数は分析対象のカラムで、2 つ目の引数はパーセントです。 例: Percentile([Column], 15.0) |
| Q1(Arg1) | 第 1 四分位数を計算します。 例: Q1([Column]) |
| Q3(Arg1) | 第 3 四分位数を計算します。 例: Q3([Column]) |
| Range(Arg1) | カラム内の最大値と最小値の間の範囲です。 結果は、引数のデータ型に応じて、実数または期間として表示されます。 例: Range([Column]) |
| StdDev(Arg1) | 標準偏差を計算します。 例: StdDev([Column]) |
| StdErr(Arg1) | 標準誤差を計算します。 例: StdErr([Column]) |
| TDist(Arg1) | 引数の (上尾の) t p-value を返します。 例: TDist(x, deg_freedom) TDist(4.302653, 2)→ 0.025 |
| TERR_Binary | TIBCO Enterprise Runtime for R エンジンを呼び出し、入力時と同じ数の行を含む、指定したデータ型の出力値を返します。 最初の引数はスクリプトで、次の引数はスクリプトの引数です。 返されるカラムは入力時と同じロー数を持っている必要があります。スクリプトを除く 1 つ以上の引数が必要です。入力値には、input1、input2、inputN という変数が配置され、出力には output という変数が配置されます。 例: TERR_Real("output <- input1*100 + input2", [Record No], [Sales]) TERR_String("output <- input1", [String Column]) |
| TERR_Boolean | 上記の「TERR_Binary」を参照してください。 |
| TERR_DateTime | 上記の「TERR_Binary」を参照してください。 |
| TERR_Integer | 上記の「TERR_Binary」を参照してください。 |
| TERR_Real | 上記の「TERR_Binary」を参照してください。 |
| TERR_String | 上記の「TERR_Binary」を参照してください。 |
| TERRAggregation_Binary | TIBCO Enterprise Runtime for R エンジンを呼び出し、指定されたデータ型の出力を返します。最初の引数はスクリプトで、次の引数はスクリプトの引数です。 スクリプトは、1 つの集計値を返します。スクリプトを除く 1 つ以上の引数が必要です。入力値には、input1、input2、inputN という変数が配置され、出力には output という変数が配置されます。 例: TERRAggregation_Real("output <- median(input1) + median(input2)", [X], [Y]) TERRAggregation_String("output <- input1[1]", [Customer Name]) |
| TERRAggregation_Boolean | 上記の TERRAggregation_Binary を参照してください。 |
| TERRAggregation_DateTime | 上記の TERRAggregation_Binary を参照してください。 |
| TERRAggregation_Integer | 上記の TERRAggregation_Binary を参照してください。 |
| TERRAggregation_Real | 上記の TERRAggregation_Binary を参照してください。 |
| TERRAggregation_String | 上記の TERRAggregation_Binary を参照してください。 |
| TInv(Arg1) | 引数の (上尾の) t 変位値を返します。 例: TInv(p, deg_freedom) TInv(0.025, 2)→ 4.302653 |
| TrimmedMean(Arg1, Arg2) | トリム平均値 (トリム平均) を計算します。1 つ目の引数は分析対象カラムで、2 つ目の引数は計算対象外の値の数をパーセントで表したものです。トリム値が 10% に設定されている場合は、最高値の 5% と最低値の 5% が計算される平均の対象外となります。 例: TrimmedMean([Sales], 10) |
| U95(Arg1) | 95% 信頼区間の上側のエンドポイントを計算します。 例: U95([Column]) |
| UAV(Arg1) | 上位隣接値を計算します。 例: UAV([Column]) |
| UIF(Arg1) | 上側の内部フェンスを計算します。これは、Q3 + (1.5*IQR)のしきい値です。 例: UIF([Column]) |
| UniqueCount(Arg1) | 引数で指定されたカラム内の空でない固有値の数を計算します。 例: UniqueCount([Column]) |
| UOF(Arg1) | 上側の外部フェンスを計算します。これは、Q3 + (3*IQR) のしきい値です。 例: UOF([Column]) |
| ValueForMax(Arg1, Arg2) | カラム 1 の最大値に対してカラム2 の値を返します。 カラム 1 の最大値が複数ある場合、結果は最初の最大ローの値になります。「LastValueForMax」も参照してください。 例: ValueForMax([Column 1], [Column 2]) |
| ValueForMin(Arg1, Arg2) | カラム 1 の最小値に対してカラム 2 の値を返します。 カラム 1 の最小値が複数ある場合、結果は最初の最小ローの値になります。「LastValueForMin」も参照してください。 例: ValueForMin([Column 1], [Column 2]) |
| Var(Arg1) | 分散を計算します。 例: Var([Column]) |
| WeightedAverage(Arg1, Arg2) | 2 つのカラムの加重平均を計算します。Arg1 は加重カラムであり、Arg2 は数値列です。 例: WeightedAverage([Column1],[Column2]) |

ヒント: DISTINCTキーワードは、一意の値のみを使用した結果を返す場合に使用できます。たとえば、Avg(DISTINCT[Column])は、指定したカラムのすべての値の平均ではなく、一意の値の平均を返します。UniqueCount([Column]) は、Count(DISTINCT[Column]).と同じです。
「関数」も参照してください。