Statistische Funktionen
Die Liste zeigt die statistischen Funktionen, die Sie in Ausdrücken verwenden können.
| Funktion | Beschreibung |
|---|---|
| Avg(Arg1, ...) | Gibt den Durchschnitt (arithmetisches Mittel) des Arguments zurück. Die Argumente und das Ergebnis sind vom Typ Real (reelle Zahl). Bei einem Argument ist das Ergebnis der Mittelwert aller Zeilen. Bei mehreren Argumenten ist das Ergebnis der Mittelwert jeder einzelnen Zeile. Null-Argumente werden ignoriert und gehen nicht in die Durchschnittsberechnung ein. Beispiele: Avg([Column]) Avg(2,-3,4)→ 1 Avg(-1) → -1 Avg(1.5, -2, 3.5) → 1 Avg(1, null, 3) → 2 Avg(null) →(Empty) |
| ChiDist(Arg1) | Gibt den Chi-Quadrat-P-Wert (oberer Tail) des Arguments zurück. Beispiel: ChiDist(x, deg_freedom) ChiDist(7.377759, 2) → 0,025 |
| ChiInv(Arg1) | Gibt den Chi-Quadrat-Quantilwert (oberer Tail) des Arguments zurück. Beispiel: ChiInv(p, deg_freedom) ChiInv(0.025, 2) → 7,377759 |
| Count(Arg1) | Berechnet die Anzahl nicht leerer Werte in der Argumentspalte oder, wenn kein Argument angegeben wurde, die Gesamtanzahl der Zeilen. Beispiel: Count([Column]) |
| CountBig(Arg1) | Berechnet die Anzahl nicht leerer Werte in der Argumentspalte oder, wenn kein Argument angegeben wurde, die Gesamtanzahl der Zeilen. Diese Funktion gibt eine lange Ganzzahl zurück. Beispiel: CountBig([Column]) |
| Covariance(Arg1, Arg2) | Berechnet die Kovarianz zweier Spalten, die als Argumente angegeben wurden. Beispiel: Covariance([Column1], [Column2]) |
| FDist(Arg1) | Gibt den F p-Wert (oberer Tail) des Arguments zurück. Beispiel: FDist(x, deg_freedom1, deg_freedom2) FDist(6.936728, 1, 10) → 0,025 |
| FInv(Arg1) | Gibt den F-Quantilwert (oberer Tail) des Arguments zurück. Beispiel: FInv(p, deg_freedom1, deg_freedom2) FInv(0.025, 1, 10) → 6,936728 |
| First(Arg1) | Gibt den ersten gültigen Wert basierend auf der physischen Reihenfolge der Datenzeilen in der Argumentspalte zurück. Beispiel: First([Column]) |
| GeometricMean() | Berechnet den geometrischen Mittelwert. Wenn einer der Eingabewerte negativ ist, lautet das Ergebnis "Leer". Wenn einer der Eingabewerte null ist, lautet das Ergebnis null. Beispiel: GeometricMean([Sales]) |
| IQR(Arg1) | Berechnet die Wertdifferenz Q3 – Q1 oder 75. Perzentil minus 25. Perzentil. Der Interquartilabstand (IQR) wird auch als H-Streubreite bezeichnet. Beispiel: IQR([Column]) |
| L95(Arg1) | Berechnet den unteren Endpunkt des 95-Prozent-Konfidenzintervalls. Beispiel: L95([Column]) |
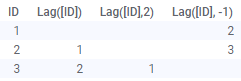
| Lag(Arg1, Arg2) | Verschiebt die Werte in einer Spalte um eine bestimmte Anzahl von Schritten nach unten. Das erste Argument ist die zu verschiebende Spalte. Das zweite (optionale) Argument ist die Anzahl der Schritte. 1 ist die Standardeinstellung. Wenn eine negative Anzahl von Schritten verwendet wird, werden die Werte in die entgegengesetzte Richtung verschoben (siehe Abbildung unten). Beispiele: Lag([Column]) Lag([Column],3) Beachten Sie, dass die Lag-Funktion auf die Daten in der Reihenfolge angewendet wird, in der die Daten geladen wurden. Die Funktion berücksichtigt die Sortierung in Visualisierungen nicht und Änderungen an den Daten (z. B. während des Neuladens) können zu unterschiedlichen Werten für die verschiedenen Zeilen führen. |
| Last(Arg1) | Gibt den letzten gültigen Wert basierend auf der physischen Reihenfolge der Datenzeilen in der Argumentspalte zurück. Beispiel: Last([Column]) |
| LastValueForMax(Arg1, Arg2) | Gibt den Wert in Spalte 2 beim Maximalwert von Spalte 1 zurück. Wenn es mehr als einen Maximalwert für Spalte 1 gibt, entspricht das Ergebnis dem Wert der letzten Zeile mit Maximalwert. Siehe auch ValueForMax. Beispiel: LastValueForMax([Column 1], [Column 2]) |
| LastValueForMin(Arg1, Arg2) | Gibt den Wert in Spalte 2 beim Minimalwert von Spalte 1 zurück. Wenn es mehr als einen Minimalwert für Spalte 1 gibt, entspricht das Ergebnis dem Wert der letzten Zeile mit Minimalwert. Siehe auch ValueForMin. Beispiel: LastValueForMin([Column 1], [Column 2]) |
| LAV(Arg1) | Berechnet den unteren Nachbarwert. Beispiel: LAV([Column]) |
| Lead(Arg1, Arg2) | Verschiebt die Werte in einer Spalte um eine bestimmte Anzahl von Schritten nach oben. Das erste Argument ist die zu verschiebende Spalte. Das zweite (optionale) Argument ist die Anzahl der Schritte. 1 ist die Standardeinstellung. Wenn eine negative Anzahl von Schritten verwendet wird, werden die Werte in die entgegengesetzte Richtung verschoben (siehe Abbildung unten). Beispiele: Lead([Column]) Lead([Column],3) Beachten Sie, dass die Lead-Funktion auf die Daten in der Reihenfolge angewendet wird, in der die Daten geladen wurden. Die Funktion berücksichtigt die Sortierung in Visualisierungen nicht und Änderungen an den Daten (z. B. während des Neuladens) können zu unterschiedlichen Werten für die verschiedenen Zeilen führen. |
| LIF(Arg1) | Berechnet den unteren inneren Zaun. Hierbei handelt es sich um den Schwellenwert bei Q1 - (1.5*IQR). Beispiel: LIF([Column]) |
| LOF(Arg1) | Berechnet den unteren äußeren Zaun. Hierbei handelt es sich um den Schwellenwert bei Q1 - (3*IQR). Beispiel: LOF([Column]) |
| Max(Arg1, ...) | Berechnet den Maximalwert. Bei einem Argument ist das Ergebnis der Maximalwert für die gesamte Spalte. Bei mehreren Argumenten ist das Ergebnis der Maximalwert jeder einzelnen Zeile. Das Argument und das Ergebnis sind vom Typ Real (reelle Zahlen). Null-Argumente werden ignoriert. Beispiele: Max([Column]) Max(-1) → -1 Max (1.5, -2, 3) → 3 Max (1, null, 3) → 3 Max (null) →(Empty) |
| MeanDeviation(Arg1, ...) | Berechnet den Wert der mittleren Abweichung (durchschnittliche Absolutabweichung, AAD). Bei einem Argument ist das Ergebnis die mittlere Abweichung aller Zeilen. Bei mehreren Argumenten ist das Ergebnis die mittlere Abweichung jeder einzelnen Zeile. Beispiele: MeanDeviation([Column]) MeanDeviation(2,-3,4) → 2,67 |
| Median(Arg1) | Berechnet den Medianwert des Arguments. Bei einem Argument ist das Ergebnis der Median aller Zeilen. Bei mehreren Argumenten ist das Ergebnis der Medianwert jeder einzelnen Zeile. Beispiele: Median([Column]) Median(2,-3,4) |
| MedianAbsoluteDeviation(Arg1, ...) | Berechnet den Medianwert der absoluten Abweichung (MAD). Bei einem Argument ist das Ergebnis der Median der absoluten Abweichung aller Zeilen. Bei mehreren Argumenten ist das Ergebnis der Medianwert der absoluten Abweichung jeder einzelnen Zeile. Beispiele: MedianAbsoluteDeviation([Sales]) MedianAbsoluteDeviation(2,-3,4) |
| Min(Arg1, ...) | Berechnet den Minimalwert. Bei einem Argument ist das Ergebnis der Minimalwert für die gesamte Spalte. Bei mehreren Argumenten ist das Ergebnis der Minimalwert jeder einzelnen Zeile. Das Argument und das Ergebnis sind vom Typ Real (reelle Zahlen). Null-Argumente werden ignoriert. Beispiele: Min([Column]) Min(-1) → -1 Min (1.5, -2, 3) → -2 Min (1, null, 3) → 1 Min (null) →(Empty) |
| NormDist(Arg1) | Gibt den normalen p-Wert (oberer Tail) des Arguments zurück. Wenn Sie die Werte nicht selbst festlegen, wird standardmäßig mean=0 und standard deviation=1 verwendet. Beispiel: NormDist(x, mean, standard_dev) NormDist(1.96) → 0,025 |
| NormInv(Arg1) | Gibt den normalen Quantilwert (oberer Tail) des Arguments zurück. Wenn Sie die Werte nicht selbst festlegen, wird standardmäßig mean=0 und standard deviation=1 verwendet. Beispiel: NormInv(p, mean, standard_dev) NormInv(0.025) → 1,96 |
| NthLargest(Arg1, Arg2) | Der N.-größte Wert. Das erste Argument ist die Spalte, die analysiert werden soll, und das zweite Argument ist der Wert n. Falls n größer als die Anzahl der Werte in der Spalte ist, wird der kleinste Wert zurückgegeben. Beispiel: NthLargest([Column], 10) |
| NthSmallest(Arg1, Arg2) | Der N.-kleinste Wert. Das erste Argument ist die Spalte, die analysiert werden soll, und das zweite Argument ist der Wert n. Falls n größer als die Anzahl der Werte in der Spalte ist, wird der größte Wert zurückgegeben. Beispiel: NthSmallest([Column], 10) |
| Outliers(Arg1) | Anzahl der äußeren Werte. Berechnet die Anzahl der Werte, die über dem oberen Nachbarwert oder unter dem unteren Nachbarwert liegen. Beispiel: Outliers([Column]) |
| P10(Arg1) | Das 10. Perzentil ist der Wert, bei dem 10 Prozent der Datenwerte kleiner oder gleich dem Wert sind. Beispiel: P10([Column]) |
| P90(Arg1) | Das 90. Perzentil ist der Wert, bei dem 90 Prozent der Datenwerte kleiner oder gleich dem Wert sind. Beispiel: P90([Column]) |
| PctOutliers(Arg1) | Perzentil der äußeren Werte. Berechnet den Prozentsatz der Werte, die über dem oberen Nachbarwert oder unter dem unteren Nachbarwert liegen. Beispiel: PctOutliers([Column]) |
| Percent(Arg1, Arg2) | Der Prozentsatz ist der Wert, der bei einem bestimmten Prozentsatz über dem Minimalwert innerhalb des Wertbereichs berechnet wird (Max.-Wert - Min.-Wert). Das erste Argument ist die Spalte, die analysiert werden soll, und das zweite Argument ist der Prozentsatz. Beispiel: Percent([Column], 15.0) |
| Percentile(Arg1, Arg2) | Das Perzentil ist der Wert, bei dem ein bestimmter Prozentsatz der Datenwerte kleiner oder gleich diesem Wert ist. Das erste Argument ist die Spalte, die analysiert werden soll, und das zweite Argument ist der Prozentsatz. Beispiel: Percentile([Column], 15.0) |
| Q1(Arg1) | Berechnet das erste Quartil. Beispiel: Q1([Column]) |
| Q3(Arg1) | Berechnet das dritte Quartil. Beispiel: Q3([Column]) |
| Range(Arg1) | Der Bereich zwischen dem größten und dem kleinsten Wert in der Spalte. Das Ergebnis wird je nach dem Datentyp des Arguments als reelle Zahl oder als Zeitraum angegeben. Beispiel: Range([Column]) |
| StdDev(Arg1) | Berechnet die Standardabweichung. Beispiel: StdDev([Column]) |
| StdErr(Arg1) | Berechnet den Standardfehler. Beispiel: StdErr([Column]) |
| TDist(Arg1) | Gibt den T p-Wert (oberer Tail) des Arguments zurück. Beispiel: TDist(x, deg_freedom) TDist(4.302653, 2) → 0,025 |
| TERR_Binary | Ruft die TIBCO Enterprise Runtime for R-Engine auf und gibt eine Ausgabe des angegebenen Datentyps mit derselben Anzahl an Zeilen wie die Eingabe zurück. Das erste Argument ist ein Skript und die folgenden Argumente sind die Argumente für das Skript. Die zurückgegebene Spalte muss dieselbe Anzahl an Zeilen wie die Eingabe aufweisen. Es ist mindestens ein Argument erforderlich, das sich vom Skript unterscheidet. Die Eingaben werden in Variablen namens input1,input2, ...inputN platziert, und die Ausgabe muss in einer Variable namens output platziert werden. Beispiele: TERR_Real("output <- input1*100 + input2", [Record No], [Sales]) TERR_String("output <- input1", [String Column]) |
| TERR_Boolean | Siehe TERR_Binary oben. |
| TERR_DateTime | Siehe TERR_Binary oben. |
| TERR_Integer | Siehe TERR_Binary oben. |
| TERR_Real | Siehe TERR_Binary oben. |
| TERR_String | Siehe TERR_Binary oben. |
| TERRAggregation_Binary | Ruft die TIBCO Enterprise Runtime for R-Engine auf und gibt eine Ausgabe des angegebenen Datentyps zurück. Das erste Argument ist ein Skript und die folgenden Argumente sind die Argumente für das Skript. Das Skript sollte einen einzelnen aggregierten Wert zurückgeben. Es ist mindestens ein Argument erforderlich, das sich vom Skript unterscheidet. Die Eingaben werden in Variablen namens input1,input2, ...inputN platziert, und die Ausgabe muss in einer Variable namens output platziert werden. Beispiele: TERRAggregation_Real("output <- median(input1) + median(input2)", [X], [Y]) TERRAggregation_String("output <- input1[1]", [Customer Name]) |
| TERRAggregation_Boolean | Siehe TERRAggregation_Binary oben. |
| TERRAggregation_DateTime | Siehe TERRAggregation_Binary oben. |
| TERRAggregation_Integer | Siehe TERRAggregation_Binary oben. |
| TERRAggregation_Real | Siehe TERRAggregation_Binary oben. |
| TERRAggregation_String | Siehe TERRAggregation_Binary oben. |
| TInv(Arg1) | Gibt den T-Quantilwert (oberer Tail) des Arguments zurück. Beispiele: TInv(p, deg_freedom) TInv(0.025, 2) → 4,302653 |
| TrimmedMean(Arg1, Arg2) | Berechnet den gestutzten Mittelwert (gestutzten Durchschnitt). Das erste Argument ist die Spalte, die analysiert werden soll, und das zweite Argument gibt an, viele Prozent der Werte von der Berechnung ausgeschlossen werden sollen. Wenn der Mittelwert um 10 % gestutzt wird, werden die höchsten 5 % und die niedrigsten 5 % der Werte aus der Mittelwertberechnung ausgeschlossen. Beispiel: TrimmedMean([Sales], 10) |
| U95(Arg1) | Berechnet den oberen Endpunkt des 95-Prozent-Konfidenzintervalls. Beispiel: U95([Column]) |
| UAV(Arg1) | Berechnet den oberen Nachbarwert. Beispiel: UAV([Column]) |
| UIF(Arg1) | Berechnet den oberen inneren Zaun. Hierbei handelt es sich um den Schwellenwert bei Q3 + (1.5*IQR). Beispiel: UIF([Column]) |
| UniqueCount(Arg1) | Berechnet die Anzahl eindeutiger, nicht leerer Werte in der Argumentspalte. Beispiel: UniqueCount([Column]) |
| UOF(Arg1) | Berechnet den oberen äußeren Zaun. Hierbei handelt es sich um den Schwellenwert bei Q3 + (3*IQR). Beispiel: UOF([Column]) |
| ValueForMax(Arg1, Arg2) | Gibt den Wert in Spalte 2 beim Maximalwert von Spalte 1 zurück. Wenn es mehr als einen Maximalwert für Spalte 1 gibt, entspricht das Ergebnis dem Wert der ersten Zeile mit Maximalwert. Siehe auch LastValueForMax. Beispiel: ValueForMax([Column 1], [Column 2]) |
| ValueForMin(Arg1, Arg2) | Gibt den Wert in Spalte 2 beim Minimalwert von Spalte 1 zurück. Wenn es mehr als einen Minimalwert für Spalte 1 gibt, entspricht das Ergebnis dem Wert der ersten Zeile mit Minimalwert. Siehe auch LastValueForMin. Beispiel: ValueForMin([Column 1], [Column 2]) |
| Var(Arg1) | Berechnet die Varianz. Beispiel: Var([Column]) |
| WeightedAverage(Arg1, Arg2) | Berechnet den gewichteten Mittelwert der beiden Spalten. Arg1 ist die Gewichtungsspalte, und Arg2 ist die Wertspalte. Beispiel: WeightedAverage([Column1],[Column2]) |

Tipp: Das Stichwort DISTINCT kann verwendet werden, um ein Ergebnis zurückzugeben, dass nur eindeutige Werte verwendet. Avg(DISTINCT[Column]) beispielsweise würde den Durchschnitt der eindeutigen Werte zurückgeben, statt den Durchschnitt aller Werte in der angegebenen Spalte zurückzugeben.UniqueCount([Column]) ist das Äquivalent von Count(DISTINCT[Column]).
Siehe auch Funktionen.