Concepts de répartition et de marqueur
Lorsque vous visualisez les données dans une table de données, les données sont réparties en plusieurs parties, qui sont représentées par des marqueurs dans la visualisation. Les cellules d'un tableau, les segments de barre, les secteurs de camembert, les entités de carte ou les sommets de ligne sont des exemples de marqueurs. Différents attributs du marqueur, tels que la taille, la forme, la couleur ou les valeurs numériques, sont ensuite utilisés pour indiquer une valeur agrégée des données sous-jacentes au marqueur.
Les concepts de répartition et de marqueur sont essentiels pour comprendre les expressions personnalisées, car ces expressions sont basées sur les répartitions qui ont été définies dans la visualisation. Les expressions personnalisées contenant l'instruction OVER sont particulièrement affectées.
Répartir les données
La répartition des données en plusieurs parties est effectuée en spécifiant différentes propriétés pour la visualisation. Par exemple, vous pouvez répartir les données selon différentes catégories sur un axe des X ou en attribuant des couleurs ou des formes différentes. Les propriétés de répartition disponibles dépendent du type de visualisation. Chaque fois que vous répartissez les données en utilisant une de ces propriétés, les données sont divisées en parties de plus en plus petites et sont représentées par un plus grand nombre de marqueurs.
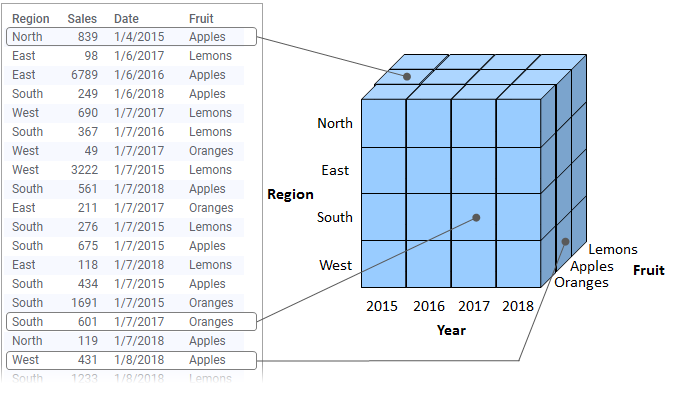
L'image suivante montre comment la répartition des données peut être représentée dans une visualisation ou un tableau croisé. Il n'y a pas de division en années : les valeurs des cellules du tableau croisé sont agrégées sur des parties qui comprennent toutes les années.
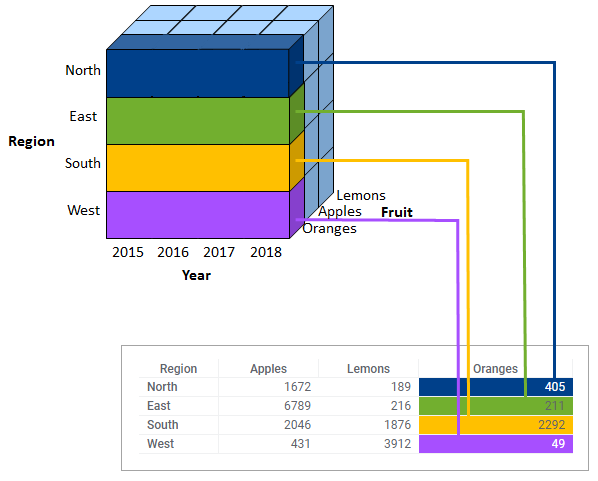
Dans l'exemple suivant, les données de ventes de la table de données sont visualisées sous la forme de nuages de points en utilisant différentes méthodes de répartition.
| Le marqueur représente la somme des ventes pour tous les fruits et toutes les années. | Les marqueurs représentent la somme des ventes par type de fruit. | Les marqueurs représentent la somme des ventes par an. |
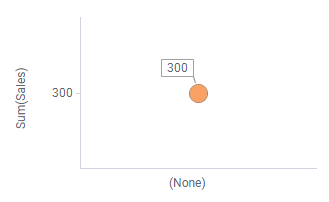
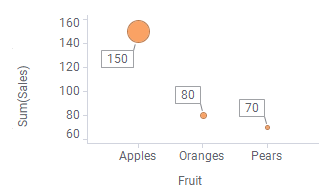
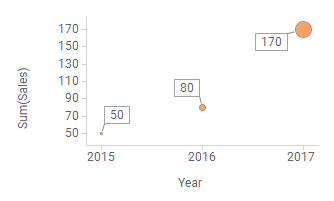
En fait, votre choix de répartition génère une expression personnalisée simple : Si vous cliquez avec le bouton droit sur chacun des sélecteurs de l'axe des X dans les nuages de points et sélectionnez Expression personnalisée, vous constaterez que les expressions<>,<[Fruit]>, et<[Year]> sont automatiquement définies dans leur boîte de dialogue Expression personnalisée respective.
De la même manière, si vous cliquez avec le bouton droit de la souris sur le sélecteur d'axe des Y et sélectionnez Expression personnalisée,Sum([Sales]) s'affiche automatiquement dans la boîte de dialogue. Les agrégations comme Sum sont des expressions personnalisées qui sont prédéfinies !
Dans les nuages de points ci-dessus, la propriété de l'axe des X a été utilisée pour répartir les données. Cependant, il existe également d'autres propriétés d'axe que vous pouvez utiliser pour la répartition (par exemple, la couleur, la forme et le treillis), comme illustré ci-dessous.
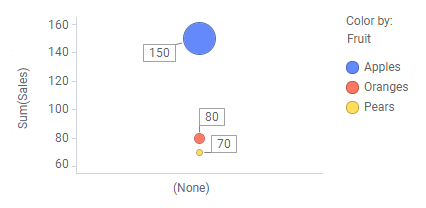
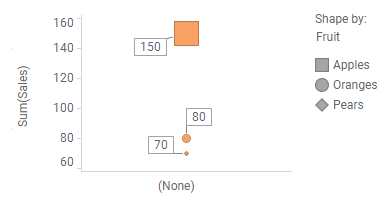
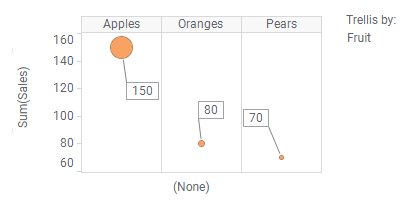
Pour conclure, vous pouvez répartir vos données de différentes façons. Les parties qui en résultent sont alors la base de vos calculs.
Marqueurs
Les marqueurs, tels que les points du nuage de points et les cellules de tableau croisé ci-dessus, sont des objets graphiques représentant la façon dont vous avez réparti vos données. Un marqueur peut représenter l'ensemble des lignes de votre table de données ou une ligne unique, selon la façon dont vous avez configuré votre visualisation. Généralement, sa valeur représente le résultat d'une agrégation (par exemple, une somme), comme indiqué dans les exemples précédents .
Expressions personnalisées
Une expression personnalisée fonctionne de la même manière qu'une agrégation prédéfinie : elle est évaluée sur chacun des marqueurs d'une visualisation. Il est cependant possible, dans une expression, d'inclure des données qui ne sont pas dans la partie actuelle en utilisant l'instruction OVER.