Example: Classification Random Forests
This example illustrates the use of Random Forests for classification tasks (i.e., tasks that require associating a data case of the predictor variables with a class type among a group of categorical levels present in the dependent variable). Further examples on the use of similar models, such as Boosted Trees, can be found in Example 1: Classification via Boosting Trees.
- Data file
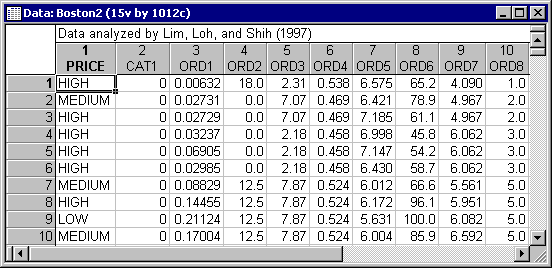
- This example illustrates an analysis of the Boston housing data (Harrison & Rubinfeld, 1978) that was reported by Lim, Loh, and Shih (1997). Median prices of housing tracts are classified as LOW, MEDIUM, or HIGH on the dependent variable PRICE. There is 1 categorical predictor, Cat1, and 12 continuous predictors, ORD1 through ORD12. A duplicate of the learning sample is used as a test sample. The sample identifier variable is SAMPLE and contains LEARNING and TEST as text. The complete data set containing 1,012 cases is available in the example data file Boston2.sta. This data file can be accessed via the File - Open Examples menu; it is in the Datasets folder. Part of this data file is shown below as an example.
- Objectives
- The purpose of this example is to demonstrate the use of the STATISTICA Random Forest module for classification type analyses. Our task is to correctly identify the class labels of each data case using the Random Forest model that we will build in this analysis. In other words, given a set of predictor values, we want to correctly categorize the price of a house in the Boston area as either LOW, MEDIUM or HIGH.
Specifying the Analysis
After opening the Boston2.sta data file, select Random Forest for Classification and Regression from the Data Mining menu to display the Random Forest Startup Panel.
In the Type of analysis list on the Quick tab, select Classification Analysis, and click the OK button to display the Random Forest Specifications dialog where you can configure the options for running the analysis.
- Selecting variables
- On the
Quick tab, click the Variables button to display the variable selection dialog. Note that not all the variables are displayed in all the variable type lists (dependent, categorical, continuous, and count). This is because STATISTICA pre-screens the list of variables so that you are prompted to select only from among those that are appropriate for the respective analysis. This feature is particularly useful when the number of variables in the data set is large. However, you can switch off pre-screening by clearing the Show appropriate variables only check box. See Select Variables for further details.
Clear the Show appropriate variables only check box, and select variable PRICE as the Dependent variable, variable CAT1 as a Categorical pred variable, and variables ORD1-ORD12 as the Continuous pred variables.
Click the OK button to accept these selections, close the variable selection dialog, and return to the Random Forest Specifications dialog.
There are a number of additional options available on the Classification, Advanced, and Stopping Condition tabs of this dialog that can be reconfigured to "fine-tune" the analysis.
- Misclassification costs
- Often, the cost of misclassification depends on if category A is misclassified as B. In other words, the cost of misclassifying A as B may be substantially different from the cost of misclassifying B as A. Setting values to misclassification costs help you to accounts for such differences. For example, if you were planning to buy a property, then perhaps misclassifying a HIGH house price as LOW is more costly than misclassifying a LOW house price as HIGH. In the former case, you will be simply over-estimating the property value. It should be noted that assigning misclassification costs is subjective by nature and may very well depend on the specific analysis.
By default, Random Forests assigns equal misclassifications costs to all categories. To change this setting, select the Classification tab.
Then, select the User spec. option button in the Misclassifications costs group box, and click the adjacent
 button to display a user defined input spreadsheet, which is used to adjust the cost values. (Note that, for this option to be available, response codes must be assigned via the Response codes option on the Quick tab).
button to display a user defined input spreadsheet, which is used to adjust the cost values. (Note that, for this option to be available, response codes must be assigned via the Response codes option on the Quick tab).
- Prior probabilities
- On the
Classification tab, you can also specify a priori probabilities of class memberships. Select the User specified option button in the Prior Probabilities group box, and click the adjacent
button to display the Enter values for the prior probabilities dialog. (Note that, for this option to be available, response codes must be assigned via the Response codes option on the Quick tab).
Prior probabilities should reflect the degree of belief in class memberships of data cases (i.e., whether it belongs to category LOW, MEDIUM, or HIGH) before performing any analysis. One way to set such probabilities is to consider the percentage of each category in the data set. This is a reasonable approach if the data set is a good representative of the true population. On the other hand, if no such information is available, then you can assign equal prior probabilities to all categories. Note that assigning equal priors means "I don't know," which simply reflects your lack of knowledge of the percentage of house categories in the Boston area. Note that priors, as all probabilities, must sum to unity.
On the Advanced tab, you can access options to control the number and complexity (number of nodes) of the tree models you are about to create.
- The Sampling methods
- By default, the Random Forest module partitions the data into training and testing samples using random selection of cases from the data set. While the training sample is used to build the model (add simple trees) the testing set is used to validate its performance. This performance is used as the goodness of the model, which for classification tasks is simply defined as the misclassification rate. By default, Random Forest selects 30% of the data set as test cases.
Instead of randomly partitioning the data set into training and test cases, you can define your holdout (testing) sample via the Test sample option, where you can identify a sample identifier code to divide the data into training and testing sets. Selecting this sampling method will override the random sampling option.
- Number of predictor variables
- One of the advantages of the STATISTICA Random Forest is the ability to perform predictions based on a partial number (subset) of the predictor variables. This feature is particularly attractive for data sets with an extremely large number of predictors.
In particular, you can specify the number of predictor variables you want to include in your tree models. This option is an important one, and care should be taken in setting its value. Including a large number of predictors in the tree models can lead to prolonged computational time and, thus, to missing one of the advantages of the Random Forest model, which is the ability to perform predictions based on a subset of the predictor variables. Alternately, including too small a number of predictor variables may downgrade the model performance (since this can exclude variables that may account for most of the variability and trend in the data). In setting the number of predictor variables, it is recommended that you use the default value, which is based on the formula (see Breiman for further details).
- Stopping conditions
- The options on the
Stopping condition tab provide you with a set of criteria for finalizing your current Random Forest model. By default, building a Random Forest involves adding a fixed number of trees (100).
However, for longer training runs there are better ways to specify when training should stop. You can do this on the Stopping Conditions tab.
The most useful option, perhaps, is the Percentage decrease in training error. This states that if the training error does not improve by at least the amount given over a number of epochs (the Cycles to calculate mean error), then training should stop.
- Reviewing the Results
- For this example, leave all the options at their default values, and click the OK button on the
Random Forest Specifications dialog. The Computing dialog will be displayed, where you can watch the progress of the analysis as well as see how much time has elapsed and how much is remaining.
Then, the Random Forest Results dialog will be displayed.
On the Quick tab, click the Summary button to review how consecutive training and testing classification rates progressed over the entire training cycles.
This graph demonstrates the basic mechanism of how the Random Forest algorithm implemented in STATISTICA can avoid overfitting (see also the Introductory Overview and Technical Notes). In general, as more and more simple trees are added to the model, the misclassification rate for training data (from which the respective trees were estimated) will generally decrease. The same trend should be observed for misclassification rates defined over the testing data. However, as more and more trees are added the misclassification rate for the testing, data will at one point start to increase (while the misclassification rate for the training set keeps decreasing), clearly marking the point where evidence for overfitting is beginning to show.
By default, the program will stop adding trees even if the designated number of trees you specified in the Number of trees option on the Advanced tab of the Random Forest Specifications dialog is not reached. To turn off the stopping condition, simply clear the Enable advanced stopping condition check box on the Stopping condition tab of the Random Forest Specifications dialog. In this case, the designated number of trees set in the Number of trees option will be added to the Random Forest.
- Accuracy of Prediction
- Note that you can generate predictions for any group of data cases of your choice - training, testing, or the entire data set. Also, you can make predictions for partially missing predictor cases, which is one of the capabilities of Random Forest models (see the
Introductory Overview and Technical Notes for further details).
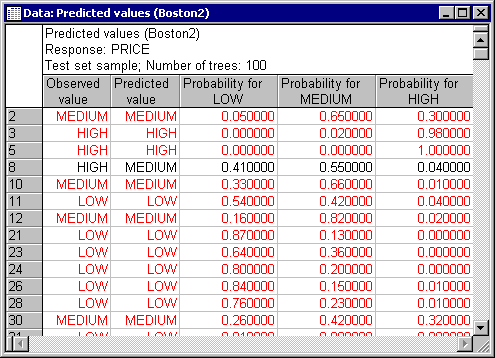
To produce predictions for the test sample, for example, click on the Classification tab of the Results dialog
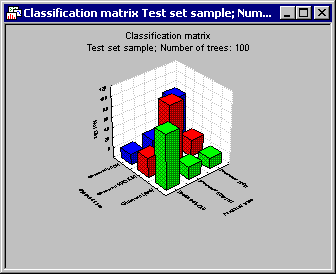
Select the Test set option button in the Sample group box, and then click the Predicted vs. observed by classes button. The program will then display the spreadsheet of predicted values and probability of class memberships. It will also display a spreadsheet and a 3D histogram of the classification matrix, together with a spreadsheet of the confusion matrix.
In addition, you may want to review the various additional summary statistics (e.g., Risk estimates) and the predictor importance (in the form of a histogram). The Predictor importance graph contains the importance ranking on a 0-1 scale for each predictor variable in the analysis. See Predictor Importance in STATISTICA GC&RT, Interactive Trees, and Boosted Trees.
- Lift charts
- Another way to assess the accuracy of the predictions is to compute the lift chart for each category of the dependent variable. Select the Classification tab of the Results dialog to compute gains or lift charts for different samples.
- Interpreting the Results
- In general, Random Forest (see the Introductory Overview and Technical Notes) is best considered a machine learning model, i.e., a "black box" that to some extent will (usually) produce very accurate predictions, but yield models that are not easily interpretable (unlike, for example, linear models, where the final prediction model can usually be "put into words," i.e., explained). To interpret the results from the STATISTICA Random Forest module, there are two key tools:
- Predictor importance
- With the bar graph and spreadsheet of the predictor importance, you can usually distinguish the variables that make the major contributions to the prediction of the dependent variable of interest. Click the Bargraph of predictor importance button on the
Quick tab to display a bar graph that pictorially shows the importance ranking on a 0-1 scale for each predictor variable considered in the analysis.
This plot can be used for visual inspection of the relative importance of the predictor variables used in the analysis and, thus, helps to conclude which predictor variable is the most important predictor. See also, Predictor Importance in STATISTICA GC&RT, Interactive Trees, and Boosted Trees.. In this case, variables ORD1, ORD5, and ORD12 stand out as the most important predictors.
- Final trees
- You can also review the final sequence of trees, either graphically or in a sequence of results spreadsheets (one for each tree). However, this may not be a useful way to examine the "meaning" of the final model when the final solution involves a large number of trees.
- Deploying the Model for Prediction
- Finally, you can deploy the model via the Code generator on the Results dialog - Report tab. In particular, you may want to save the PMML deployment code for the created model, and then use that code via the Rapid Deployment Engine module to predict (classify) new cases.
- Adding more trees/amending your model
- Rather than continually creating new models, which may be time consuming, you can amend your existing Random Forest without full model re-building. Upon analyzing your results you may find, for example, that your model is not strong enough (i.e., does not fit the data well). In this case, you may want to add more trees by simply specifying the number of trees to add in the Number of more trees option and then clicking the More trees button.