SANN Overviews - Network Generalization
Generalization and Performance
The performance of neural networks is measured by how well they can predict unseen data (an unseen data set is one that was not used during training). This is known as generalization. The issue of generalization is actually one of the major concerns when training neural networks. It is known as the tendency to overfit the training data accompanied by the difficulty in predicting new data. While one can always fine tune (overfit) a sufficiently large and flexible neural network to achieve a perfect fit (i.e., zero training error), the real issue here is how to construct a network that is capable of predicting on new data as well. As it turns out, there is a relation between overfitting the training data and poor generalization. Thus, when training neural networks, one must take the issue of performance and generalization into account.
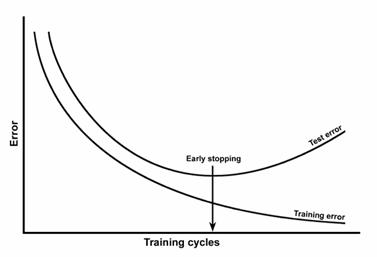
Schematic of a neural network training with early stopping. The network is repeatedly trained for a number of cycles as long as the test error is on the decrease. When the test error starts to increase, training is halted.
There are several techniques to combat the problem of overfitting and tackling the generalization issue. The most popular ones involve the use of test data. Test data is a holdout sample that will never be used in training. Instead, it will be used as a means of validating how well a network makes progress in modeling the input-target relationship as training continues. Most work on assessing performance in neural modeling concentrates on approaches to test data. A neural network is optimized using a training set. A separate test set is used to halt training to mitigate overfitting. The process of halting neural network training to prevent overfitting and improving the generalization ability is known as early stopping. This technique slightly modifies the training algorithm to:
- Present the network with an input-target pair from the training set.
- Compute the predictions of the network for the targets.
- Use the error function to calculate the difference between the predictions (output) of the network and the target values.
- Continue with steps 1 and 2 until all input-target pairs from the training set are presented to the network.
- Use the training algorithm to adjust the weights of the networks so that it gives better predictions for each and every input-target.
- Pass the entire test set to the network, make predictions, and compute the value of network test error.
- Compare the test error with the one from the previous iteration. If the error keeps decreasing, continue training; otherwise, stop training.
Validation Data
Sometimes the test data alone may not be sufficient proof of a good generalization ability of a trained neural network. For example, a good performance on the test sample may actually be just a coincidence. To make sure that this is not the case, another set of data known as the validation sample is often used. Just like the test sample, a validation sample is never used for training the neural network. Instead, it is used at the end of training as an extra check on the performance of the model. If the performance of the network was found to be consistently good on both the test and validation samples, then it is reasonable to assume that the network generalizes well on unseen data.
Regularization
Besides the use of test data for early stopping, another technique frequently used for improving the generalization of neural networks is known as regularization. This method involves adding a term to the error function that generally penalizes (discourages) large weight values.
One of the most common choices of regularization is known as weight decay (Bishop 1995). Weight decay works by modifying the network's error function to penalize large weights by adding an additional term Ew (same applied to the cross-entropy error function)
where ![]() is the weight decay constant and w is the network weights (biases excluded). The larger
is the weight decay constant and w is the network weights (biases excluded). The larger ![]() the more the weights are penalized. Consequently, too large a weight decay constant may damage network performance by encouraging underfitting, and experimentation is generally needed to determine an appropriate weight decay factor for a particular problem domain. The generalization ability of the network can depend crucially on the decay constant. One approach to choosing the decay constant is to train several networks with different amounts of decay and estimate the generalization error for each; then choose the decay constant that minimizes the estimated generalization error.
the more the weights are penalized. Consequently, too large a weight decay constant may damage network performance by encouraging underfitting, and experimentation is generally needed to determine an appropriate weight decay factor for a particular problem domain. The generalization ability of the network can depend crucially on the decay constant. One approach to choosing the decay constant is to train several networks with different amounts of decay and estimate the generalization error for each; then choose the decay constant that minimizes the estimated generalization error.
The above form will encourage the development of smaller weights, which tends to reduce the problem of overfitting by limiting the ability of the network to form large curvature, thereby potentially improving generalization performance of the network. The result is a network that compromises between performance and weight size.
It should be noted that the basic weight decay model described above might not always be the most suitable way of imposing regularization. A fundamental consideration with weight decay is that different weight groups in the network usually require different decay constants. Although this may be problem dependent, it is often the case that a certain group of weights in the network may require different scale values for an effective modeling of the data. Examples of such groups are input-hidden and hidden-output weights. Therefore, STATISTICA Automated Neural Networks uses separate weights decay values for regularizing these two groups of weights.