Advanced Tab
Select the Advanced tab in the Text Mining dialog box to access the options described here.
Note: You can use the options on the Defaults tab to save or retrieve the settings for these options and to set the defaults for future analyses.
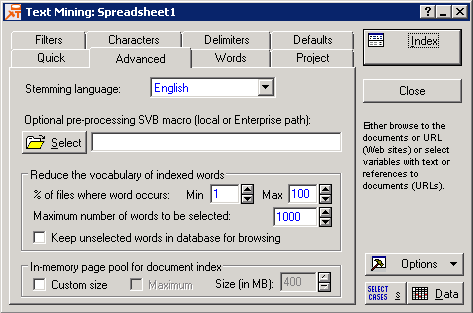
| Option | Description |
|---|---|
| Stemming language. | Choose one of languages to be used for stemming the words in the input documents. Stemming is an important pre-processing step before indexing of input documents begins. The term refers to the reduction of words to their root, so that, for example, different grammatical forms or declinations of verbs are identified and indexed (counted) as the same word. For example, stemming will ensure that both "travel" and "traveled" will be recognized by the program as the same word. Stemming is available for several languages. |
| Reduce the vocabulary of indexed words | Use the options in this group box to refine the specifications for the words to be indexed. |
| % of files where word occurs |
In the Min. box, specify the minimum permissible document frequency (specify an integer percentage value) for the analysis. Words that occur in fewer than the indicated percentage of documents will be deemed non-diagnostic and excluded from the analysis (e.g., if only a very small number of documents contain the word "stentorian," that word is not particularly useful to characterize the contents and underlying dimensions that enable us to summarize the collection of documents in a meaningful way). In the Max. box, specify the maximum permissible document frequency (specify an integer percentage value) for the analysis. Words that occur in more than the indicated percentage of documents will be deemed non-diagnostic and excluded from the analysis (e.g., if a very large percentage of documents contain the word "tree," that word may not be particularly useful to characterize the contents and underlying dimensions that enable us to summarize the collection of documents and differentiate between them in a meaningful way). |
| Maximum number of words to be selected | Specify an integer number for the maximum number of indexed words to be selected for subsequent analysis. If the number of indexed terms exceeds this limit, the program will trim it by selecting those with the highest document frequencies, and among those with equal document frequencies - ones with higher total occurrence count. Note that a useful maximum number of indexed and selected (for the final results) terms will rarely exceed 1,000 words or so. Common words (such as the English "the," "also," etc.) are by default excluded via the Stop words list as selected on the
Words tab. Rare or unusual words (that only occur in a small subset of documents) are also by default excluded (see option
Min % of files where word occurs).
Keep in mind that this word selection approach might not be as effective when analyzing only a few lengthy documents, since in this case there is a limited number of distinct document frequencies. The general point, which is also further discussed in the Introductory Overview, is that the techniques implemented in Statistica Text and Document Mining are best suited for incorporating large numbers of documents of moderate size into overall data mining projects, rather than extracting concepts from a very few large documents. (A good example of the former would be the analysis of narratives accompanying insurance claims in a large database of claims; an example of the latter application would be if you wanted to summarize and compare the "concepts" and "constructs" in three lengthy textbooks on statistics.) |
| Keep unselected words in database for browsing | Select this check box to retain unselected words in the indexing database; as mentioned above, it is important to distinguish between selected vs. indexed words. Words or terms can be indexed in the (internal) database but not selected into the word list from which final results are computed (e.g., singular value decomposition). |
| In-memory page pool for document index | The document indexing engine uses a file-backed page pool that enables it to handle large amounts of data (with sizes exceeding computer’s physical or even virtual memory). This is a low-level setting that controls the size of in-memory page pool; since the indexer is multi-threaded, on computers with multiple processing units (cores), a separate page pool will be allocated for each thread. Default settings in this section will be sufficient for most applications, but in some cases users may benefit from using custom values, especially when processing large data sets on computers with lots of physical memory. |
| Custom size |
Select this check box to enable access to the Maximum check box and Size (in MB) box. |
| Maximum |
Select this check box to use all available physical memory for page pools. |
| Size (in MB) | Enter the specification of custom sizes for page pools. |