Can I select random subsets of data?
Yes, you can. Subsets of data can be created using both simple random sampling and systematic random sampling. Select Random Sampling from the Data menu to display the Create a Random Sample dialog box.
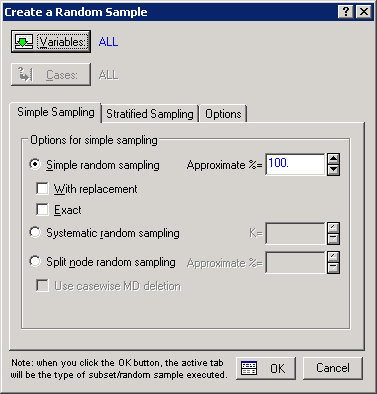
Select the Simple random sampling option button on the Simple Sampling tab to obtain a subset by random sampling. You have two choices in regard to how the subset is created: either by the Percentage of cases within the original spreadsheet or an Approximate number of cases. If you select the With replacement check box, once a case is selected to be included into the subset, that case is placed back into the pool of available choices for the remaining cases in the subset (hence an individual case can appear more than once in the resulting subset).
Select the Systematic random sampling option button to obtain a subset by systematic random sampling. For instance, if you enter a 5 in the K= box, Statistica randomly selects a case within the first five cases and then finish obtaining the subset by selecting each fifth case in the spreadsheet after the originally selected case.
Select the Split node random sampling option button to randomly divide the selected observations in the current data file into two data files; this option is particularly useful in the context of data mining projects in order to create separate data sets for training and testing of models for predictive data mining.