Noncentrality-Based Indices of Fit - Steiger-Lind RMSEA Index
The Population Noncentrality Index F* (PNI) offers some significant virtues as a measure of badness-of-fit (see, e.g., Steiger & Lind, 1980; McDonald, 1989). First, it is a weighted sum of discrepancies. Second, unlike the Akaike information criterion, for example, it is relatively unaffected by sample size.
However, there are two obvious problems with using the population noncentrality index as an index of population badness-of-fit.
The PNI is not in the metric of the original standardized parameters, because the quadratic form squares the weighted residuals.
The PNI fails to compensate for model complexity. In general, for a given S, the more complex the model the better it fits. A method for assessing population fit which fails to compensate for this will inevitably lead to choosing the most complex models, even when much simpler models fit the data nearly as well. The PNI fails to compensate for the size or complexity of a model. Hence it has limited utility as a device for comparing models.
The RMS index, first proposed by Steiger and Lind (1980), takes a relatively simplistic (but not altogether unreasonable) approach to solving these problems. Since model complexity is reflected directly in the number of free parameters, and inversely in the number of degrees of freedom, the PNI is divided by degrees of freedom, then the square root is taken to return the index to the same metric as the original standardized parameters.
Hence
![]() (90)
(90)
The RMS index R* can be thought of roughly as a root mean square standardized residual. Values above .10 indicate an inadequate fit, values below .05 a very good fit. Point estimates below .01 indicate an outstanding fit, and are seldom obtained.
In practice, point and interval estimates of the population RMS index are calculated as follows. First, we obtain point and interval estimates of the PNI. (Negative point estimates are replaced by zero.) Since all these are non-negative, and R* is a monotonic transform of the PNI, point estimates and a confidence interval for R* are obtained by inserting the corresponding values for F* in Equation 90.
It may be shown easily that a bound on the point estimate of R* implies a corresponding bound on the ratio of the Chi-square statistic to its degrees of freedom. Specifically, suppose, for example, you have decided that, for your purposes, the point estimate of the RMS index should be less than some value c. Manipulating the interval, we have
R* < c
Letting c2 = nF , the expression becomes
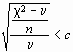
This in turn implies that
![]() (91)
(91)
So, for example, the rule of thumb that, for "close fit," RMS should be less than .05 translates into a rule that
![]() (92)
(92)
With this criterion, if n = 400, the ratio of the Chi-square to its degrees of freedom should be less than 2. Note that this rule implies a less stringent criterion for the ratio c2/n as sample size increases.
Rules of thumb that cite a single value for a critical ratio of c2/n ignore the point that the Chi-square statistic has an expected value that is a function of degrees of freedom, population badness of fit, and N. Hence, for a fixed level of population badness of fit, the expected value of the Chi-square statistic will increase as sample size increases. The rule of Equation 91 compensates for this, and hence it may be useful as a quick and easy criterion for assessing fit.
To avoid misinterpretation, we should emphasize at this point that our primary emphasis is on a confidence interval based approach, rather than one based on point estimates. The confidence interval approach incorporates information about precision of estimate into the assessment of population badness of fit. Simple rules of thumb (such as that of Equation 91) based on point estimates ignore these finer statistical considerations.