Models with Structured Means or Intercept Variables
Analysis of covariance structures can be extended to handle modeling of the means of variables as well as their variances and covariances. However, some important restrictions apply to these model extensions. In particular, in order to obtain a Chi-square statistic, the assumption of multivariate normality of the observed variables is required. The estimates obtained are "maximum normal likelihood" estimates, rather than "maximum Wishart likelihood" estimates, as in standard covariance structure models.
The extended SEPATH model has the same form as the model in Equation 36, except the variables mx, mn, lx, and ln are replaced in s1 and s2 by
![]() (158)
(158)
![]() (159)
(159)
![]() (160)
(160)
![]() (161)
(161)
where tx, tn, kx, and kn are constants, sometimes referred to as "intercept terms" in the model.
Under these conditions, the observed manifest variables ![]() and
and ![]() will no longer have zero means, but rather will have expected values that are a straightforward function of the model parameters in B, G, tx, tn, kx, and kn. Define
will no longer have zero means, but rather will have expected values that are a straightforward function of the model parameters in B, G, tx, tn, kx, and kn. Define
![]() (162)
(162)
![]() (163)
(163)
and
![]() (164)
(164)
If the population distribution is multivariate normal, then sample means and covariances are statistically independent, and two following discrepancy functions are of particular interest.
The Maximum Normal Likelihood (ML) discrepancy function is
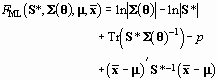 (165)
(165)
where ![]() is a vector of sample means, and
is a vector of sample means, and
![]() (166)
(166)
is the (biased) maximum normal likelihood estimate of the covariance matrix. The Normal Theory Generalized Least Squares (GLS) discrepancy function is
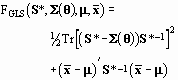 (167)
(167)
Some straightforward algebra shows how the mathematics developed for covariance structure models can be employed to fit models for mean and covariance structures. Specifically, if one uses the standard ML discrepancy function in Equation 56, but replaces S with the augmented moment matrix MA, and S with
![]() (168)
(168)
one obtains a result identical to the discrepancy function in Equation 165. A similar result holds for the GLS discrepancy functions
For a set of p variables, the augmented moment matrix MA is a (p+1)x(p+1) square matrix. The first p rows and columns contain the matrix of moments about zero, while the last row and column contain the sample means for the p variables. The matrix is therefore of the form:
![]() (169)
(169)
where M is a matrix with element
![]() (170)
(170)
and ![]() is a vector with the means of the variables.
is a vector with the means of the variables.