The Client-Server Version of Statistica Data Miner and Data Mining via Statistica Enterprise Server
In the desktop version of Statistica Data Miner, all computations are performed on the local computer, and resources of other computers are used only in the case when the Streaming Database Connector to external databases is established. Streaming database connector is a technology that reads data asynchronously directly from remote database servers (using distributed processing if supported by the server), and bypassing the need to import data and create a local copy of the data set. Records of data are retrieved and sent to the Statistica computer asynchronously by the CPU of the database server, while Statistica simultaneously processes them using the CPU of the local computer.
The client-server architecture
When a Client-Server version of Statistica Data Miner is used, the local computer drives only the user interface of Data Miner, and all calculations are performed on the server. The client-server architecture offers obvious advantages when your data mining projects are large ( such as computationally intensive or involving processing of extremely large data sets), and thus when they can be offloaded to the servers, freeing your local computer to perform other jobs.
Statistica Enterprise Server Data Miner technology
Many additional advantages are offered by the specific implementation of the client-server architecture in Statistica Data Miner, which is based on the Statistica Enterprise Server technology. The Statistica Enterprise Server platform is built on advanced distributed processing and multithreading technology to support optimal management of large computational loads. This technology enables rapid processing of even very large and computationally intensive projects, taking full advantage of the multiple CPUs on the server, or even multiple servers working in parallel. The illustration below shows a project running on a quad processor server, along with the server performance monitor, demonstrating the full utilization of the resources of all four CPUs executing in the multithreading mode a single, computationally intensive Statistica Data Miner project.
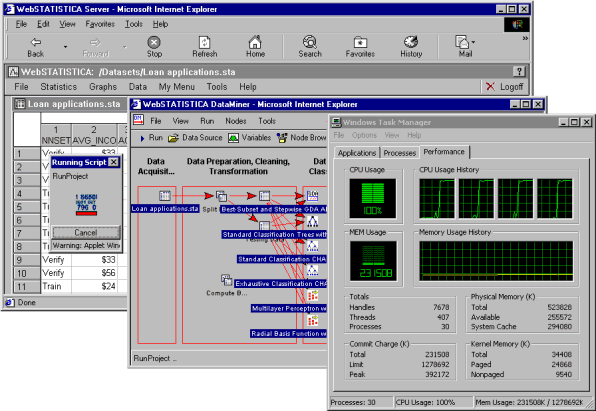
Statistica Enterprise Server Data Miner User Interface
With the Statistica Enterprise Server implementation of Statistica Data Miner, users can design, modify, and edit data mining projects on a client machine in a Web browser interface that is essentially identical to that available for the desktop installation. Therefore, the client side of the application (the front end) can be run on any computer (even a light-weight laptop) as long as it is connected to the Internet. However, the actual computations and other operations performed on the data will remain on the (remote) server with its usually more powerful processors and storage resources (and they will be managed using the optimized, multithreading and distributed processing architecture of the system for maximum performance).
When properly licensed and installed, the user-interface aspects of Statistica Data Miner can be run by one or multiple users via a browser, while the server performs all computations and data operations, enforcing the proper security and access privileges applicable to the respective projects and classes of users, as designed by the network administrator.
Statistica Enterprise Server Data Miner and the Enterprise-Wide Data Warehouse
In addition to ensuring greater processing speed (multithreading, distributed processing) as well as security of data and results, the Statistica Enterprise Server client-server platform offers numerous advantages in an enterprise-wide computing environment. As mentioned, this ultimate enterprise system supports management of access privileges of virtually any complexity (including workgroups and sub-workgroups with many levels of access), thus allowing you to manage analytic projects of any size and with virtually any number of authorized users. Also, the platform independence of this system offers additional benefits. For example, you can design and/or request certain (data mining) analyses via Statistica Enterprise Server Data Miner, submit the request to the server, and then continue with other work on the local computer ( notebook computer while in-flight). When the requested tasks have been completed by the server, you will automatically be notified via e-mail, and can retrieve the results of the analyses via a Web browser by clicking on the link (included in the e-mail) to the repository holding the results.
Integration of Client-Server and Desktop Data Mining
The Statistica Enterprise Server based client-server implementation of Statistica Data Miner is fully integrated with the desktop version, and both can be used simultaneously. For example, you can "delegate" certain computationally intensive tasks to the server in order to (a) take advantage of its usually multiple-CPU hardware, which can be used optimally by Statistica Data Miner's multithreading and distributed processing architecture, and (b) free the local (client) computer to continue your work interactively using all its processing resources.
Also, if a properly licensed and configured desktop version of Statistica Data Miner is installed on the local client machine (your notebook computer that you use to connect to the Statistica Data Miner server), you can easily exchange all Statistica documents with the server installation. For example, you could apply an initial feature selection and screening data mining project to a (very large) remote database on a server. Then, after the requested (screened) subset of the data has been retrieved, you can quickly download the selected records and variables (data columns) to your local computer, perform various analyses locally, and then upload the results of your analyses (a list of the clients that should be contacted, a summary sales report with various tables, graphs, charts, etc.) to the server to make those results available to other individuals with access to the server.
You could also analyze data locally on your computer; for example, find a neural network architecture useful for predictive data mining, and then upload the fully trained network as a deployed project to the server, where it can be used by others running Statistica Data Miner in the client-server mode. In fact, because of the object (component) nature of the Statistica Data Miner architecture, you can even program custom-designed data analysis nodes or data screening/filtering nodes on your local computer, test run and debug those nodes locally, and then upload them to the server so that other users can use the new node (without having access to the source code you designed, if that is desired).