Refining Automatic Text Classification with Synonyms and Phrases
This example expands on the first Text Mining example, Automatic Text Classification, using synonyms and phrases to aid in extracting concepts. Synonyms and phrases tend to be domain specific. In general, these lists should be compiled by subject matter experts. These experts must decide what words to group as synonyms and if any phrases are appropriate.
The documents in this example are on a variety of subjects, some of which are about financial earnings. The goal is to classify documents in terms of their subject matter, related to financial earnings or not. The phrase balance sheet is a financial term. It is a financial statement listing a company’s assets, liabilities, and equity. The terms used separately can have different meanings, unrelated to financial earnings. Using balance sheet as a phrase in Text Mining allows for better distinction between the phrase and the separate terms, potentially giving the predictive model better accuracy.
Data File with File References - Overview
The purpose of this analysis is to derive a model that will enable us to automatically determine whether a document is relevant to the Earnings category. Synonyms and phrases will be used to improve the quality of the Text Mining output. The example data file Reuters.sta is used.
The variable File Name contains the actual file names to be explored. The second variable, Topic: Earnings?, is how the experts classified each document (as relevant or not relevant to Earnings). Also, there is a variable called Training that will be used later during cross-validation of the final model to evaluate its predictive validity and accuracy.
Specifying the Analysis
Open the example data file Reuters.sta and launch Statistica Text Miner.
Ribbon bar: Select the Home tab. In the File group, click the Open arrow and select Open Examples to display the Open a Statistica Data File dialog box. Open the Datasets folder. The Reuters.sta data file is located in the TextMiner folder. Select the Data Mining tab. In the Text Mining group, click Text Mining to display the Text Mining dialog box.Classic menus: From the File menu, select Open Examples to display the Open a Statistica Data File dialog box. Open the Datasets folder. The Reuters.sta data file is located in the TextMiner folder. From the Data Mining menu, select Text & Document Mining to display the Text Mining dialog box.
- On the Quick tab, specify the source of text data (e.g., from spreadsheet cases, from files, or from a file in locations specified by a spreadsheet column): select the Files option button, and select the Paths in spreadsheet check box.
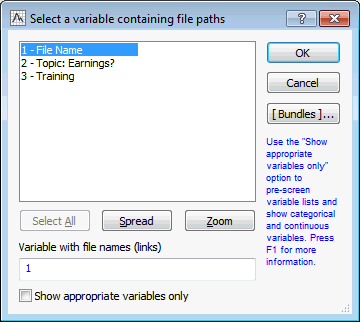
- Click the Document paths button to display a variable selection dialog box. Select the variable File Name [which is the variable containing the complete references to the input document (.xml) files].
- Click the OK button to close the variable selection dialog box and return to the Text Mining dialog box.
- Select the Advanced tab. In the % of files where word occurs box, enter 3 in order to filter out infrequent words.
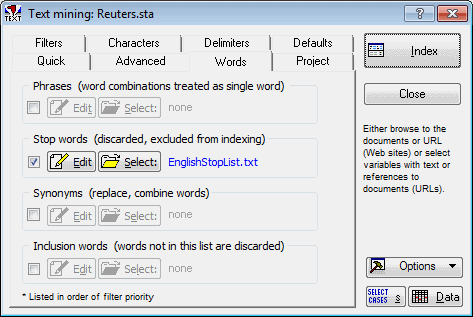
- Select the Words tab. Ensure that the Stop words (discarded, excluded from indexing) check box is selected.
- Click the adjacent Select button to display the Open Stop-Word (Text) File dialog box. Select the EnglishStoplist.txt file (which is in the TextMiner subdirectory of the Statistica Text Mining and Document Retrieval installation)
- Click the Open button to load that file as the default stop list, i.e., the words and terms contained in that stop list will be excluded from the indexing that occurs during the processing of the documents. Refer also to the Introductory Overview for details.
- Specify a list of phrases. Select the Phrases (word combinations treated as single word) check box.
- Click the adjacent Edit button to display the Phrase editor. Type in appropriate phrase terms for this project: balance sheet, board of directors, fiscal year, corporate tax rate, cash flow, stock holders, and net loss.
- Click the Save As button and name the file Phrases. Close the Phrase Editor.
-
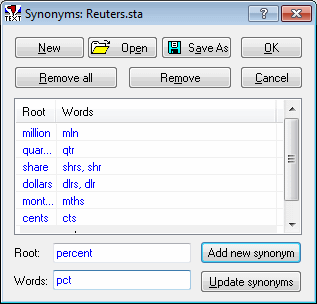
The financial earnings documents use some abbreviations. Not all texts, however, use these abbreviations. To specify the complete word to be the same as the abbreviation, use a synonyms list. Select the Synonyms (replace, combine words) check box. Click the adjacent Edit button to display the Synonyms dialog box.
Synonyms for this example are: million, mln; quarter, qtr; share, shrs, shr; dollars, dlrs, dlr; months, mths; cents, cts; and percent, pct.
- Type in the term that will represent the synonym words in the Root field and synonyms (abbreviations) for that word in the Words field, and then click the Add new synonym button. Continue with each word and its abbreviations in the above list
- Click OK to save the synonyms file and close the dialog box.

Processing the Data Analysis
- Click the Index button in the Text Mining dialog box to begin the processing of the documents.
-
The Results dialog box is displayed.
Saving the extracted word frequencies to the input file
Continuing with the goal to build a predictive model, the indexed terms are needed.
- Select the
Save results tab, and click the
Generate a new spreadsheet with current results button.
The Add selected input variables to output dialog box is displayed.
- Select Topic: Earnings? and Training.
- Click OK to generate the spreadsheet.

These results can be used to build predictive models for Topic: Earnings? similar to the first example (Example 1: Automatic Text Classification) using Feature Selection and Variable Screening and Classification and Regression Trees. Using the steps in Example 1, perform Feature Selection and Classification and Regression Trees and compare the results.
Different variables are selected as the 20 most important in Feature Selection and a different classification tree is built in Classification and Regression Trees. The accuracy rate turns out to be the same at 94%.
Conclusion
This example illustrates how specifying synonyms and phrases in Statistica Text Mining and Document Retrieval can improve the quality of the results. Both synonym and phrase lists are specific to the application, but they can be reused in similar domains. Using synonyms and phrases helps to more accurately capture meaning in unstructured text.