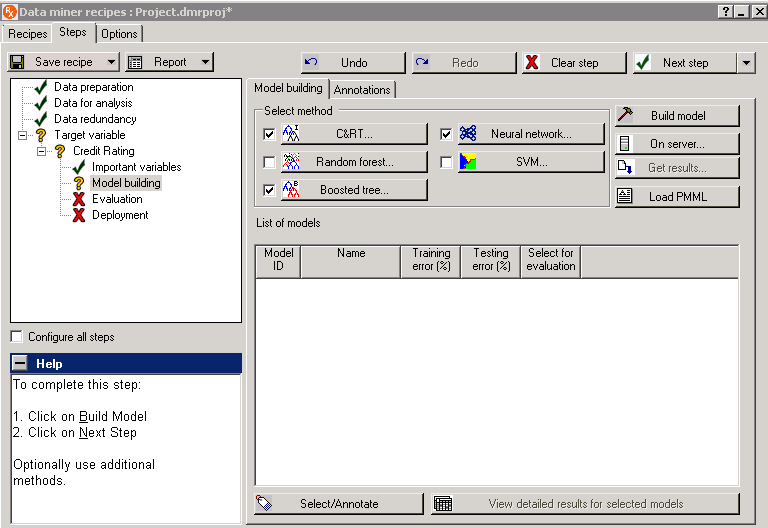
| Select method
|
Use the options in this group box to select the methods to use in building predictive models. You can select any combination of the five methods. Clicking the button for a selected method displays a dialog box with advanced options.
- C&RT: Select this check box to create standard regression or classification trees (depending on the type of target) for continuous and categorical predictors.
When this check box is selected, click the
C&RT button to display the
C&RT dialog box and specify advanced options.
- Random forest: Select this check box to create random forests (regression or classification) for continuous and categorical predictors.
When this check box is selected, click the
Random forests button to display the
Random forests
dialog box and specify advanced options.
- Boosted tree: Select this check box to create boosting trees (regression or classification) for continuous and categorical predictors.
When this check box is selected, click the
Boosting trees button to display the
Boosting trees dialog box and specify advanced options.
- Neural network: Select this check box to use the automatic network search engine to build predictive models for either regression or classification problems.
When this check box is selected, click the
Neural networks button to display the
Neural networks dialog box and specify advanced options.
- SVM: Select this check box to use a full-featured implementation of Support Vector Machines (SVM) for regression or classification problems.
When this check box is selected, click the
SVM button to display the
SVM dialog box and specify advanced options.
|
| Build model
|
Initiates the model building algorithm. When the computation is finished, a list of models (one for each selected method) is displayed in the
List of models data grid.
|
| On server
|
Off-loads the model building task to a remote server. When you off-load computationally demanding tasks to the server, upon completion of those tasks, the immediate results generated by the job off-loaded to Statistica Enterprise Server can also be reviewed from within Statistica Enterprise Server. This is a convenient feature to check periodically and quickly on the progress and results of such computations.
|
| Get results
|
When off-loading a model building task to a remote server, the results reside locally unless retrieved. Click the
Get results button to retrieve the optimization results from the off-loading remote server.
|
| Load PMML
|
Loads PMML files for analytic models produced outside of Statistica Data Miner Recipes.
|
| List of models
|
This data grid provides you with a quick view of the models you have created for relating the input variables to the target data.
A model might be active depending on whether it matches the selection criteria. You can, however, turn a model active by using the
Select/Annotate button of this tab to display the Select/Annotate Models dialog box where you can change the status of the existing models.
- Model ID: All Data Miner models have a unique identity number. This enables you to quickly recognize and uniquely identify the individual models in the latter stages of the Data Miner analysis.
- Name: Each model has a name depending on its type. These include Random forest, Boosted tree, C&RT, SVM, and Neural network.
- Training Residual (Mean sum of square): This column displays the error of the model on the subsets used during training.
- Correlation Coefficient (Training): This column displays the correlation between Observed and Predicted values.
- Select for evaluation: This column displays True for selected models and False for unselected models. To change the status of existing models, click the
Select/Annotate button to display the
Select and Annotate Models dialog. In the Select for evaluation column of that dialog, you can clear the check boxes of models you do not want to evaluate and select the check boxes of models you do want to evaluate.
|
| Select/Annotate
|
Displays the
Select/Annotate models dialog box, which shows a data grid containing the same information displayed on the
list of models located on this tab. Using that dialog, you can select and annotate models.
|
| View detailed results for selected models
|
Generates a Statistica workbook containing various spreadsheets and graphs pertaining to a number of properties and performance of the models you have selected including model predictions, statistics summary of the targets and their predictions and goodness of fit.
Note: At least one model must be selected in order to use this functionality.
|