Descriptive Statistics - Robust Tab
Select the Robust tab of the Descriptive Statistics dialog box to access options to calculate robust estimates of location that are insensitive to outliers in the data.
Summary: statistics
Click this button to produce a spreadsheet containing the statistics selected in the Location group box of this tab.
Robust statistics, such as those calculated here, can give useful results even when certain model assumptions (such as normality) are not met. Because they are insensitive to extreme values in the data, robust location statistics should be used when outliers are present in the data.
Trimmed mean
Select this check box and enter a percentage value to use in calculating the trimmed mean.
Unlike the Winsorized mean (which replaces a percentage of values from the top and bottom of the data set), the Trimmed mean is calculated by removing a percentage of values from both ends of the data set. A trimmed mean, therefore, is the arithmetic average after x-percentage of values has been removed from the highest and lowest ends of the data set.
Winsorized mean
Select this check box and enter a percentage value to use in calculating the Winsorized mean.
The Winsorized mean is the mean computed after the x-percentage highest and lowest values are replaced by the next adjacent value in the distribution. For example, consider an ordered data set with 100 observations: x1, x2, x3, ... x98, x99, x100. If you specify a Winsorized mean with 5%, the bottom five percent of values (x1, x2, x3, x4 and x5) are replaced with the next adjacent value in the distribution (x6). Likewise, the top five percent (x96, x97, x98, x99, x100) are replaced with x95.
When the data are taken from a symmetric distribution, the Winsorized mean is an unbiased estimate of the population mean. However, the Winsorized mean does not have a normal distribution even if the data are normally distributed.
Grubbs test for outliers
Select this check box to include the results for Grubbs outlier test (Grubbs 1969; Stefansky 1972) in the robust statistics spreadsheet.
Based on the assumption of normality, this test can be used to detect a single outlier at a time. It is not recommended for use on samples with less than 7 observations.
Grubbs test statistic (G) is calculated as the ratio of the largest absolute deviation from the sample mean to the sample standard deviation. That is,
![]() is the outlier if G is greater than the critical value,
is the outlier if G is greater than the critical value,
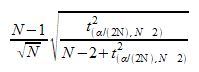
Where:
![]() is the sample mean
is the sample mean
s is the sample standard deviation
N is the sample size, and
is the critical value from a t distribution with N-2 degrees of freedom and a significance level of ![]() .
.