Independent Component Analysis Overview
Statistica Independent Component Analysis (ICA), part of the Data Mining suite of analyses, is designed for signal separation using a well established and reliable statistical method known as Independent Component Analysis.
Signal separation is a frequently occurring problem and is central to Statistical Signal Processing, which has a wide range of applications in many areas of technology ranging from Audio and Image Processing to Biomedical Signal Processing, Telecommunications, and Econometrics.
Imagine being in a room with a crowd of people and two speakers giving presentations at the same time. The crowd is making comments and noises in the background. We are interested in what the speakers say and not the comments emanating from the crowd. There are two microphones at different locations, recording the speakers' voices as well as the noise coming from the crowd. Our task is to separate the voice of each speaker while ignoring the background noise (see illustration below).
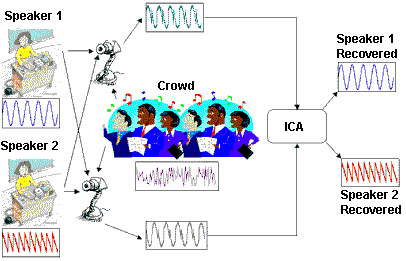
This is a classic example of the Independent Component Analysis, a well established stochastic technique with applications in many areas of technology including Audio and Image Processing, Biomedical Signal Processing, Telecommunications, and Econometrics. ICA can be used as a method of Blind Source Separation, meaning that it can separate independent signals from linear mixtures with virtually no prior knowledge on the signals. An example is decomposition of Electro or Magnetoencephalographic signals. In computational Neuroscience, ICA has been used for Feature Extraction, in which case it seems to adequately model the basic cortical processing of visual and auditory information. New application areas are being discovered at an increasing pace.
Statistica Fast Independent Component Analysis (FICA)
Statistica ICA uses state-of-the-art methods for implementing the Independent Component Analysis algorithm to virtually any practical problem requiring separation of mixed signals into their original components. These methods include Simultaneous Extraction and Deflation techniques. Other features supported in the program include data pre-processing and case selection. The program also supports the implementation of the ICA methods to either new analyses (for example, model creation) or the deployment of existing models that have been previously prepared and saved. Thus, while you can use the Statistica ICA module for creating new models, you can also re-run existing models for deployment and further analysis.
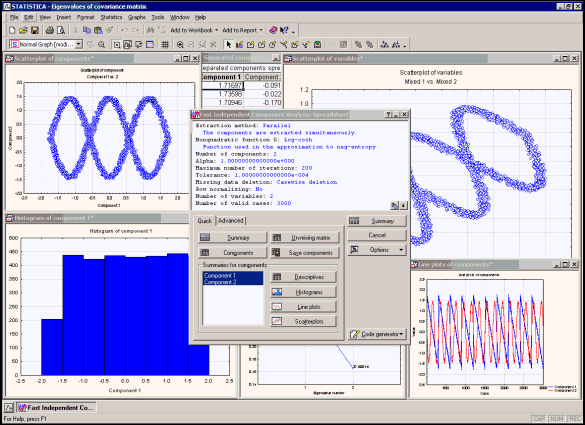
A large number of graphs and spreadsheets can be computed to evaluate the quality the ICA models to aid with the interpretation of results and conclusions. Various code generator options are available for saving estimated (fully parameterized) models for deployment in C/C++/C#, Visual Basic, or PMML. (See also, Using C/C++ Code for Deployment.) Statistica ICA is also a fully automated module that can used be used within the Statistica Data Miner environment.