Computational Formulas
In STATISTICA General Classification and Regression Trees, estimates of accuracy are computed by different formulas for categorical and continuous dependent variables (classification and regression-type problems). For classification-type problems (categorical dependent variable) accuracy is measured in terms of the true classification rate of the classifier, while in the case of regression (continuous dependent variable) accuracy is measured in terms of mean squared error of the predictor.
In addition to measuring accuracy, the following measures of node impurity are used for classification problems: The Gini measure, generalized Chi-square measure, and generalized G-square measure. The Chi-square measure is similar to the standard Chi-square value computed for the expected and observed classifications (with priors adjusted for misclassification cost), and the G-square measure is similar to the maximum-likelihood Chi-square (as for example computed in the Log-Linear module). The Gini measure is the one most often used for measuring purity in the context of classification problems, and it is described below.
For continuous dependent variables (regression-type problems), the least squared deviation (LSD) measure of impurity is automatically applied.
Estimation of Accuracy in Classification
In classification problems (categorical dependent variable), three estimates of the accuracy are used: resubstitution estimate, test sample estimate, and v-fold cross-validation. These estimates are defined here.
- Resubstitution estimate
- Resubstitution estimate is the proportion of cases that are misclassified by the classifier constructed from the entire sample. This estimate is computed in the following manner:
where X is the indicator function;
X = 1, if the statement
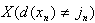 is true
is true
X = 0, if the statement
is false
and d (x) is the classifier.
The resubstitution estimate is computed using the same data as used in constructing the classifier d .
- Test sample estimate
- The total number of cases are divided into two subsamples Z1 and Z2. The test sample estimate is the proportion of cases in the subsample Z2, which are misclassified by the classifier constructed from the subsample Z1. This estimate is computed in the following way.
Let the learning sample Z of size N be partitioned into subsamples Z1 and Z2 of sizes N and N2, respectively.
where Z2 is the sub sample that is not used for constructing the classifier.
- v-fold cross-validation
- The total number of cases are divided into v sub samples Z1, Z2, ..., Zv of almost equal sizes. v-fold cross validation estimate is the proportion of cases in the subsample Z that are misclassified by the classifier constructed from the subsample Z - Zv. This estimate is computed in the following way.
Let the learning sample Z of size N be partitioned into v sub samples Z1, Z2, ..., Zv of almost sizes N1, N2, ..., Nv, respectively.
where
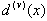 is computed from the sub sample Z - Zv .
is computed from the sub sample Z - Zv .
Estimation of Accuracy in Regression
In the regression problem (continuous dependent variable) three estimates of the accuracy are used: resubstitution estimate, test sample estimate, and v-fold cross-validation. These estimates are defined here.
- Resubstitution estimate
- The resubstitution estimate is the estimate of the expected squared error using the predictor of the continuous dependent variable. This estimate is computed in the following way.
where the learning sample Z consists of (xi,yi),i = 1,2,...,N. The resubstitution estimate is computed using the same data as used in constructing the predictor d .
- Test sample estimate
- The total number of cases are divided into two subsamples Z1 and Z2. The test sample estimate of the mean squared error is computed in the following way:
Let the learning sample Z of size N be partitioned into subsamples Z1 and Z2 of sizes N and N2, respectively.
where Z2 is the sub-sample that is not used for constructing the predictor.
- v-fold cross-validation
- The total number of cases are divided into v sub samples Z1, Z2, ..., Zv of almost equal sizes. The subsample Z - Zv is used to construct the predictor d. Then v-fold cross validation estimate is computed from the subsample Zv in the following way:
Let the learning sample Z of size N be partitioned into v sub samples Z1, Z2, ..., Zv of almost sizes N1, N2, ..., Nv, respectively.
where
 is computed from the sub sample Z - Zv .
is computed from the sub sample Z - Zv .
Estimation of Node Impurity: Gini Measure
The Gini measure is the measure of impurity of a node and is commonly used when the dependent variable is a categorical variable, defined as:
if costs of misclassification or unequal prior probabilities are not specified,
if costs of misclassification or unequal prior probabilities are specified,
where the sum extends over all k categories. p( j / t) is the probability of category j at the node t and C(i / j ) is the probability of misclassifying a category j case as category i.
Note: the specification of equal or unequal prior probabilities can greatly affect the accuracy of the final tree model for predicting particular classes. For details, see Prior Probabilities, the Gini Measure of Node Impurity, and Misclassification Cost.Estimation of Node Impurity: Least-Squared Deviation
Least-squared deviation (LSD) is used as the measure of impurity of a node when the response variable is continuous, and is computed as:
where Nw(t) is the weighted number of cases in node t, wi is the value of the weighting variable for case i, fi is the value of the frequency variable, yi is the value of the response variable, and y(t) is the weighted mean for node t.