Sequence, Association, & Link Analysis (SAL) Technical Notes
The goal of the techniques described in this topic is to detect relationships between specific values of items in large data sets. Items can be goods purchased in a supermarket or Web sites visited over a period of time. This is a common task in many data mining projects, and also in its subcategory text mining. These powerful exploratory techniques have a wide range of applications in many areas of business practice and research - from the analysis of consumer preferences or human resource management, to the history of language. They enable analysts and researchers to uncover hidden patterns in large data sets, such as "customers who order product A often also order product B or C" or "employees who said positive things about initiative X also frequently complain about issue Y but are happy with issue Z." The implementation of Sequence, Association and Link Analysis in Statistica enables you to process rapidly huge data sets for such rules.
The purpose of the analysis is to find associations between the items that were purchased, i.e., to derive association rules that identify the items and co-occurrences of different items that appear with greatest frequencies. For example, you want to learn which books are likely to be purchased by a customer who you know already purchased (or is about to purchase) a particular title. This type of information could then quickly be used to suggest to the customer those additional titles. You may already be familiar with the results of these types of analyses if you are a customer of various online (Web-based) retail businesses; many times when making a purchase online, the vendor will suggest similar items at the time of "check-out," based on rules such as "customers who buy book title A are also likely to purchase book title B," and so on.
To summarize, you can use the Sequence, Association and Link Analysis module of Statistica to find rules of the kind If X then (likely) Y where X and Y can be single values, items, words, etc., or conjunctions of values, items, words, etc. [e.g., if (Car=Porsche and Gender=Male and Age<20) then (Risk=High and Insurance=High)]. The program can be used to analyze simple dichotomous variables and/or multiple response variables. Also possible is the use of continuous variables, which are divided into segments for rule extraction. The algorithm will determine the rules (association and/or sequence) without requiring the user to specify the number of distinct categories present in the data, or any prior knowledge regarding the maximum factorial degree or complexity of the important rules. Hence, this technique is particularly well suited for data and text mining of huge databases.
Computational Procedures and Terminology
Sequence, Association and Link Analysis is an implementation of a unique and fast algorithm that uses the powerful a priori algorithm (see Agrawal and Swami, 1993; Agrawal and Srikant, 1994; Han and Lakshmanan, 2001; see also Witten and Frank, 2000) together with a tree structured procedure that only requires one pass through data. Hence, it is fast and efficient and is particularly suitable for huge data sets for which other methods can be extremely slow.
| Transactions | Items Bought |
| 1 | A, B, D |
| 2 | A, C |
| 3 | A, E |
| 4 | B, E, F |
From the table of transactions shown above, we can drive a list of frequencies for the itemsets (an itemset contains one or more items).
| Itemsets | Frequency |
| (A) | 3 |
| (B) | 2 |
| (C) | 1 |
| (D) | 1 |
| (E) | 2 |
| (F) | 1 |
| (A, B) | 1 |
| (A, C) | 1 |
The frequency of an itemset is defined as the relative frequency of transactions containing that particular itemset, either as a whole or as a subset. The itemset (A), for example, occurs in transactions 1, 2, and 3. Thus, its relative frequency is 3. Similarly, the itemset (B) has a frequency of 2. The itemset (A, C) has the lowest frequency, 1. More complex itemsets such (A, B, C, F) do not occur (in this example). This is because, as a general rule, the more complex the itemset is (i.e., the larger the number of items it contains), the less likely to occur. In other words, complicated rules (see If Body then Head above) are harder to observe.
The support for an itemset is simply given by proportion of records in the transactions data set that have the itemset. Thus, for the itemset (A) we can write:
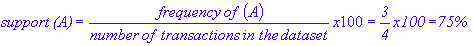
Similarly, we can calculate the support value for the rule "if A then C", (A, C) as:
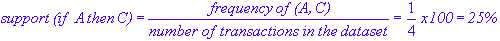
Thus, support is the probability that transactions containing A will also contain C. On the other hand, the confidence is defined as:
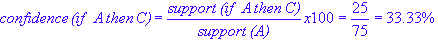
which is simply the conditional probability of transactions containing A will also contain C. Being a conditional probability, the confidence for "if A then C" is not necessarily the same as the confidence for "if C then A."
The support and confidence are then combined to define lift for a rule. For example, the lift value for if A then C is given by: