Bulk Retrieval With Salesforce.com
When working with Salesforce.com, there are various settings that you can set that will allow you to query large data sets and reduce the number of API requests.
These settings can be accessed from the Change Settings dialog for Salesforce.com. To open this dialog, from the ibi Data Migrator desktop interface, expand the Adapters folder, right-click Salesforce.com, and click Change Settings.
The Change Settings dialog opens, as shown in the following image.
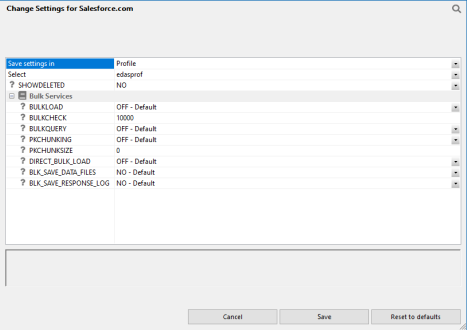
The following Bulk Services options are available:
Enables the use of Extended Bulk Load. The default value is OFF.
The row interval to commit or write transactions to the database. The default value is 10000. If the value is set to 0, the commit is issued when the job is completed.
Enables Bulk Query for data retrieval. The default value is OFF. When this option is selected, queries that meet the Salesforce.com requirements, such as no aggregation, will use bulk query.
You can also use the following command to enable or disable Bulk Query:
ENGINE SFDC SET BULKQUERY {ON|_OFF_}
Enables bulk query Primary Key chunking for data retrieval. The default value is OFF. When this option is enabled, extremely large data sets can be extracted. The Primary Key of the object is used to retrieve data in chunks, which allows for retrieval of larger data values.
You can also use the following command to extract extremely large data sets:
ENGINE SFDC SET PKCHUNKING {ON|_OFF_}
Enables the bulk query Primary Key chunk size for data retrieval. The default value is 0. When this value is not set, or set to 0, Salesforce.com will use the default chunk size of 100000. The maximum chunk size is 250000.
You can also use the following command to enable the bulk query chunk size:
ENGINE SFDC SET PKCHUNKSIZE {0..250000}
When enabled, it shortens load times when a source file is in the expected format of the bulk load program for the database to be loaded. The faster load times result from loading the file directly, without creating an intermediate file. Direct Bulk Load can be enabled as an adapter setting, meaning that all flows using that adapter use it.
When set to Yes, retains an intermediate file that is created, as well as the log (response) file. The default value is No.
The files are saved in the same application directory as the flow. Each is generated with a synonym that you can use for reporting. The file type of the intermediate HTML file is .ftm and the response file is .log. You can use these files in conjunction with the batch results to see which records were loaded successfully (with the internal ID for those records), and which were not (with the error message for those records).
When set to Yes, saves the response log file. The log file will automatically be saved if BLK_SAVE_DATA_FILES is set to Yes. The default value is No. The file is saved in the same application as the flow and has the file type .log.