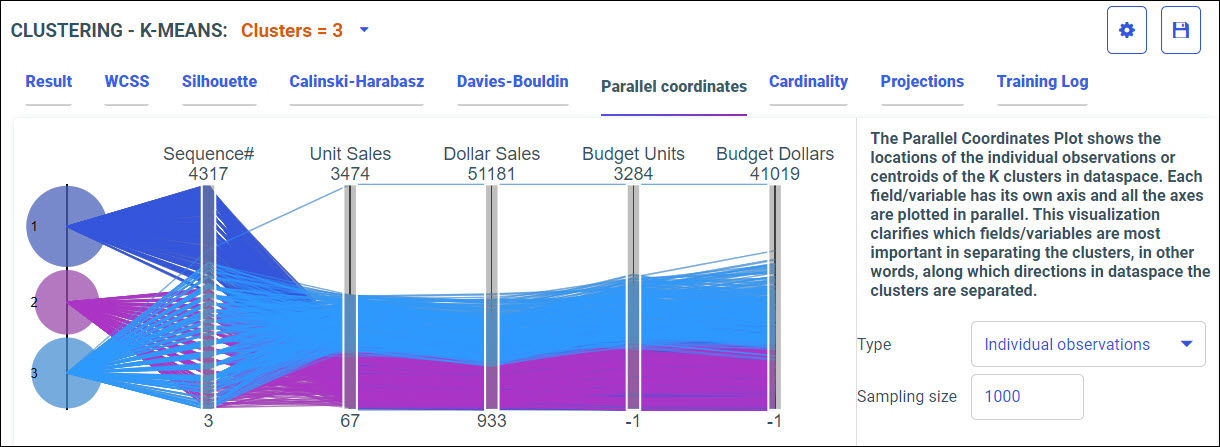
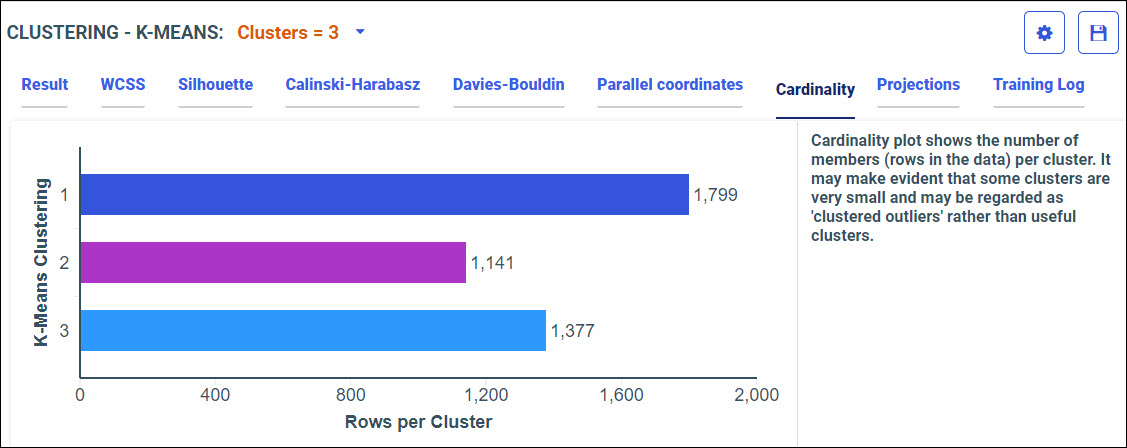
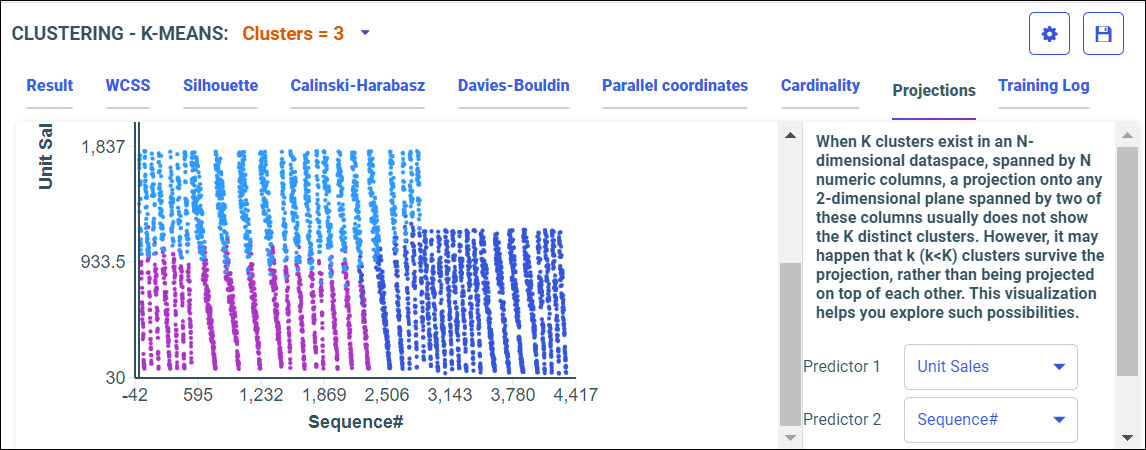
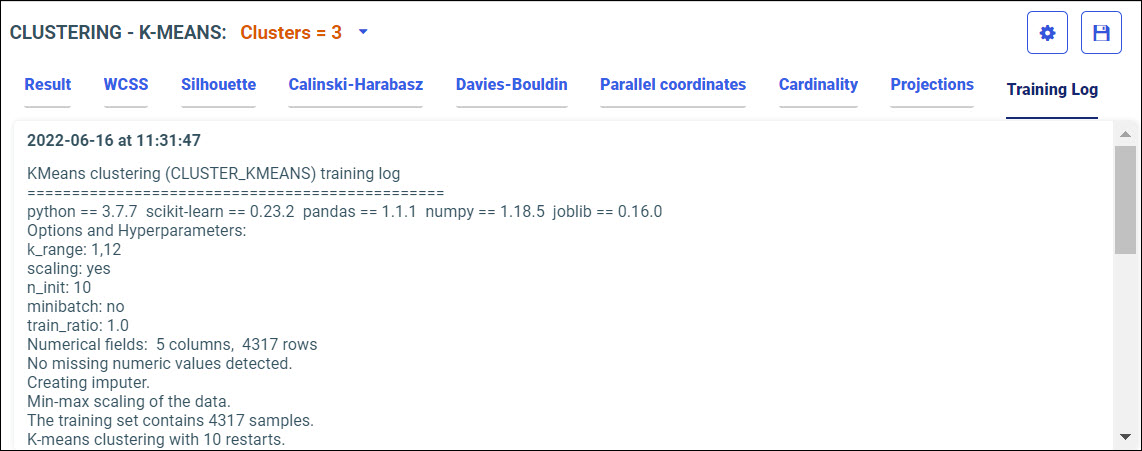
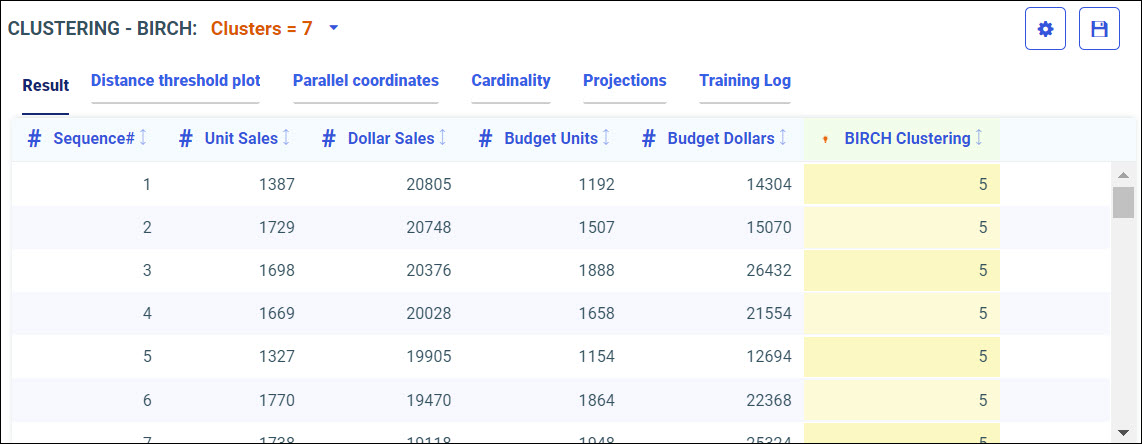
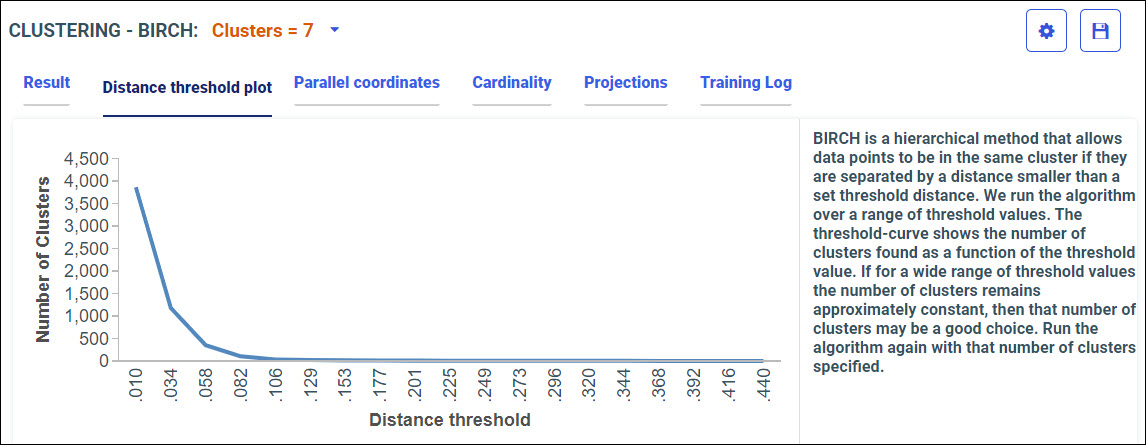
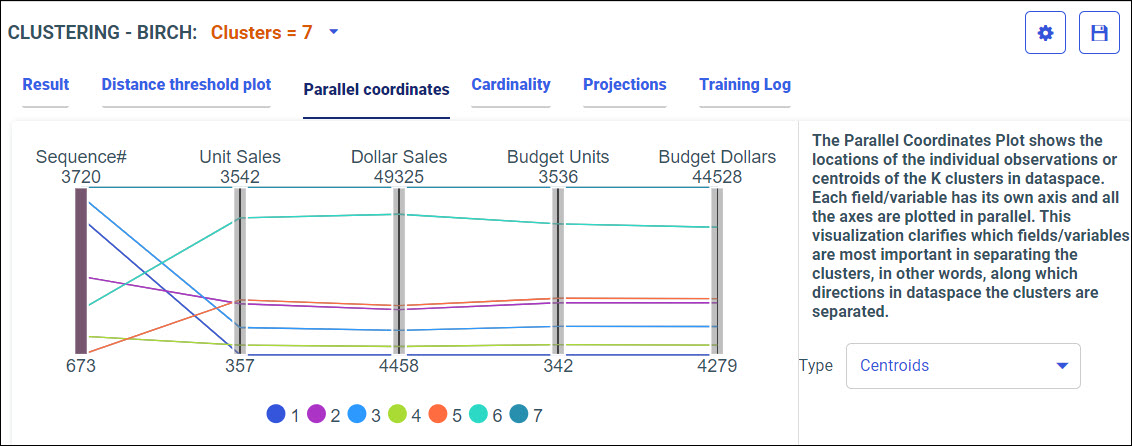
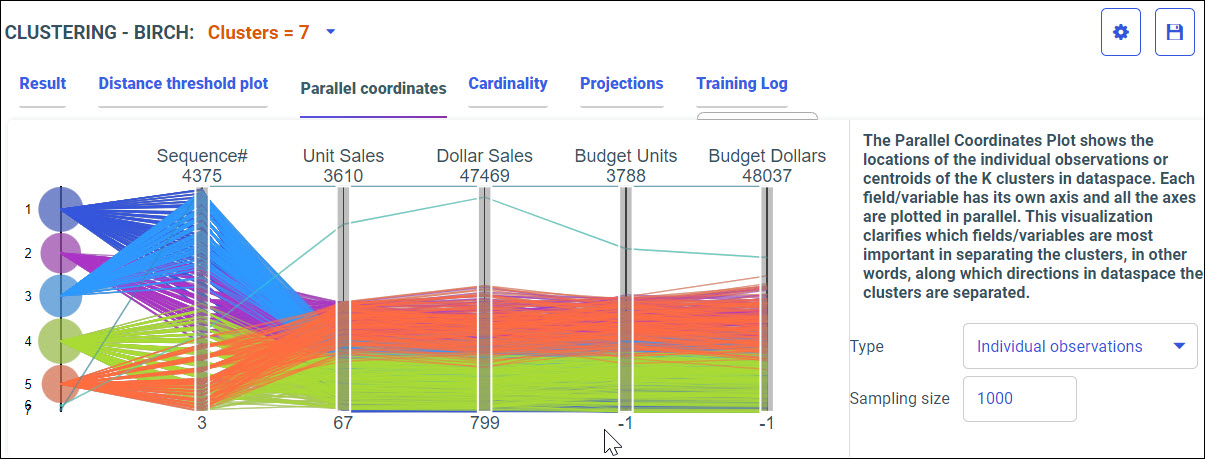
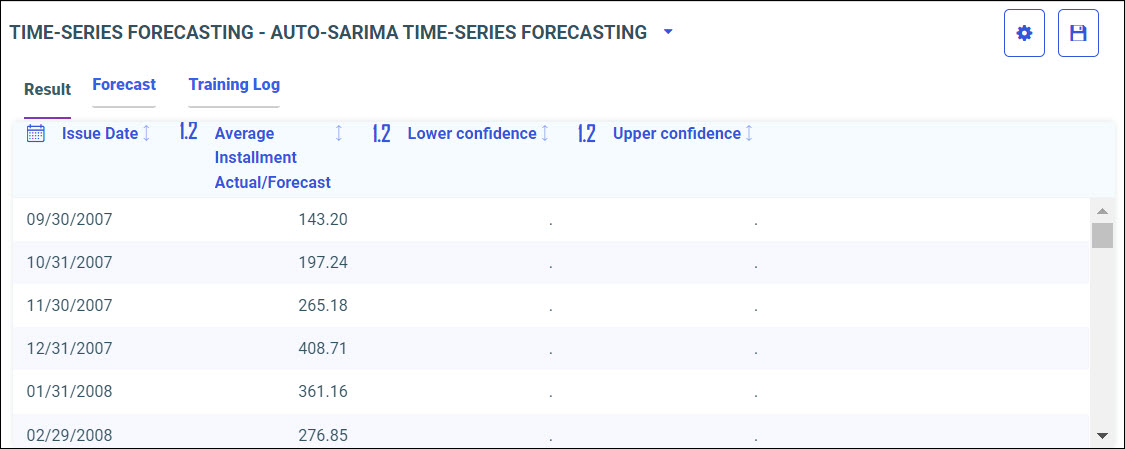
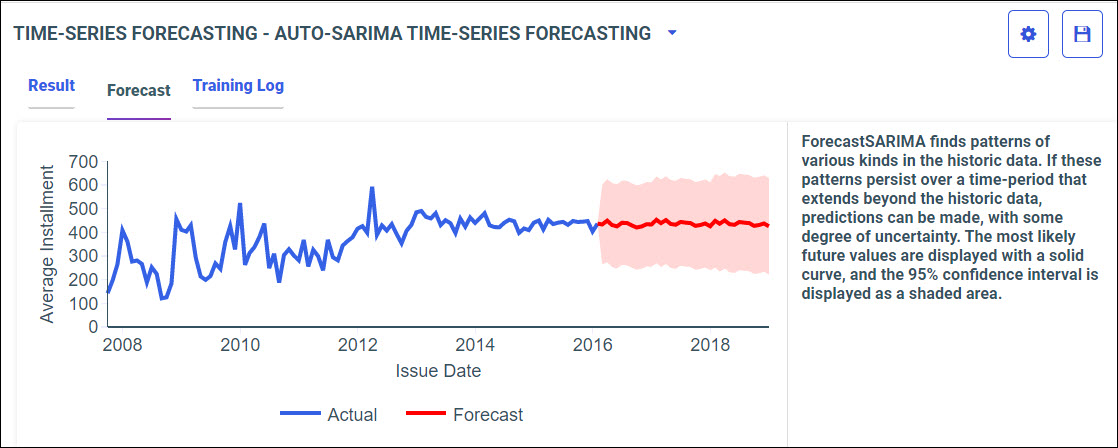
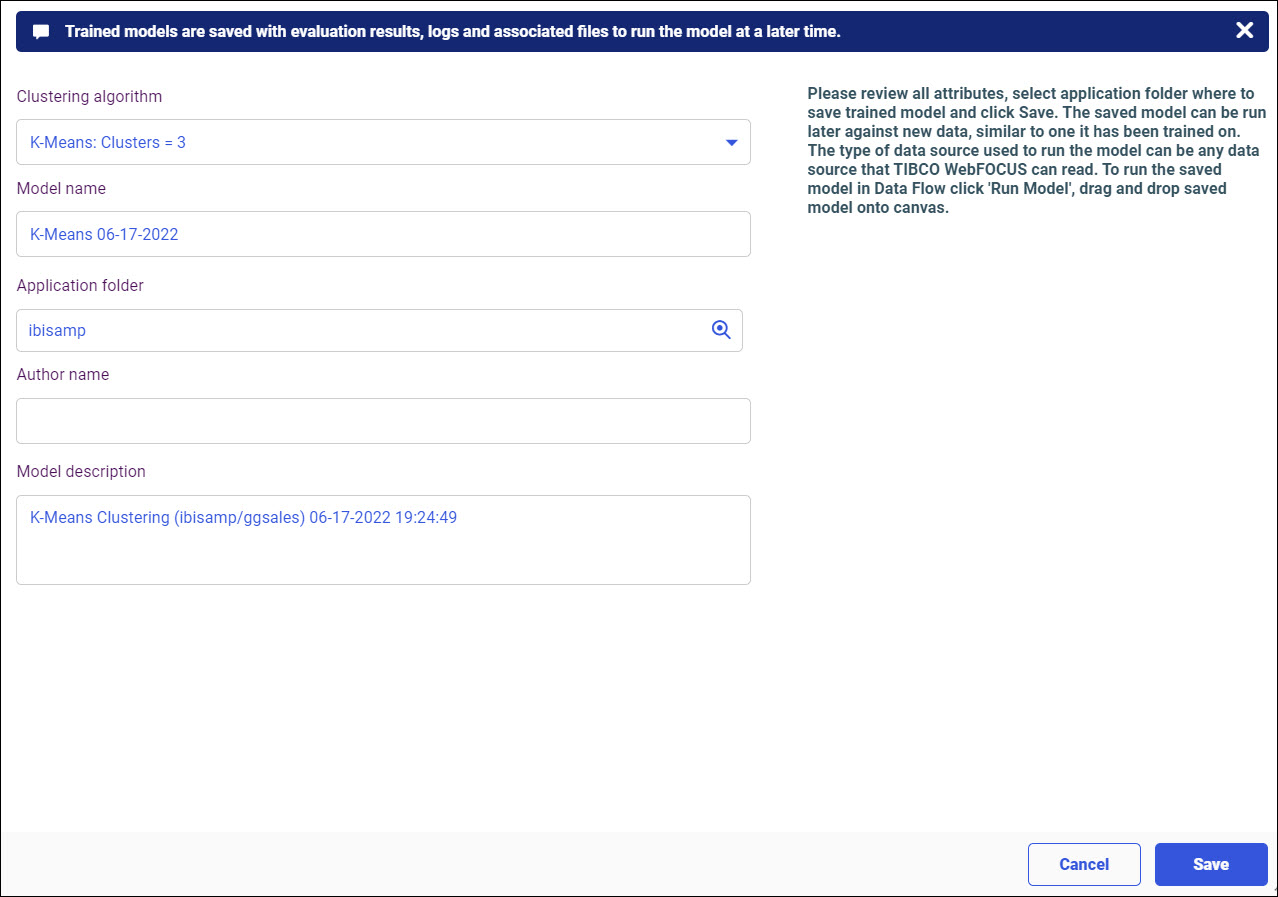
Procedure: How to Access Predictive Models
After you create a Data Flow, you can select from different model algorithms to run against your data set.
- From the WebFOCUS Hub, click the plus menu, and then click Create Data Flow. Or, from the WebFOCUS Hub, click Application Directories, click an application, then right-click a data set, and select Flow. Or, from the WebFOCUS Reporting Server browser interface, click an application, then right-click a data set, and select
Flow.
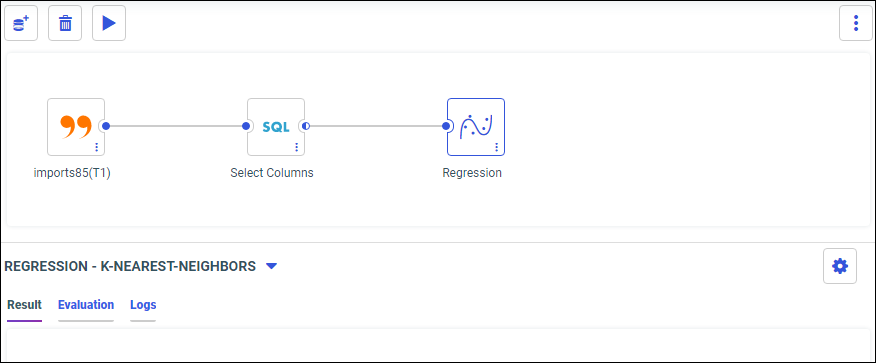
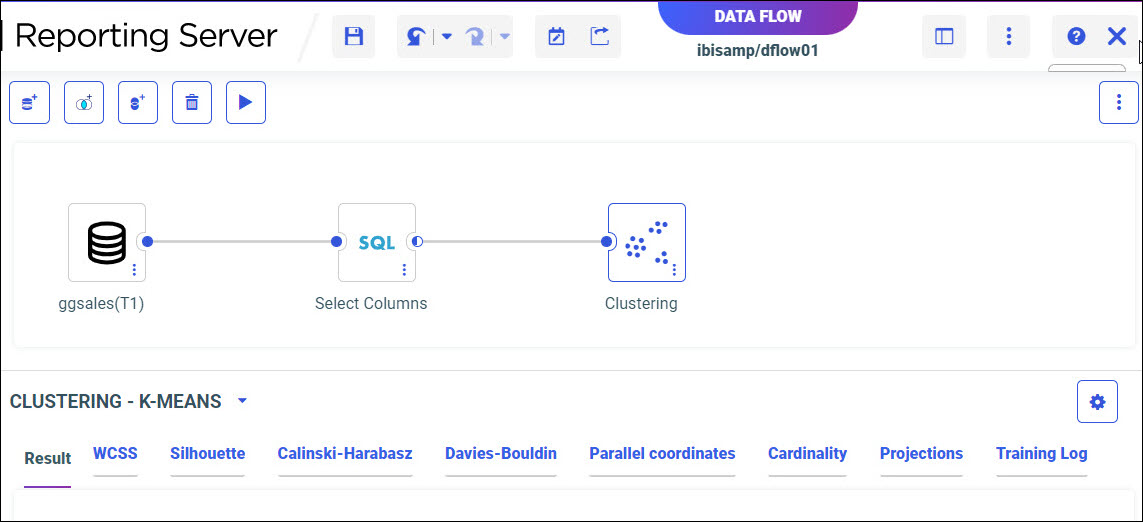
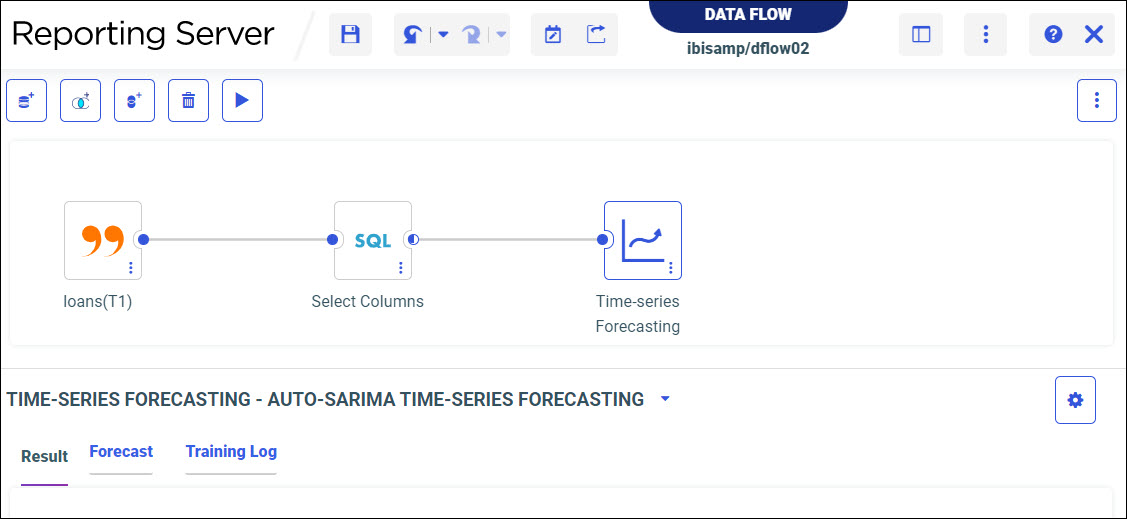
The Data Flow page opens, as shown in the following image.
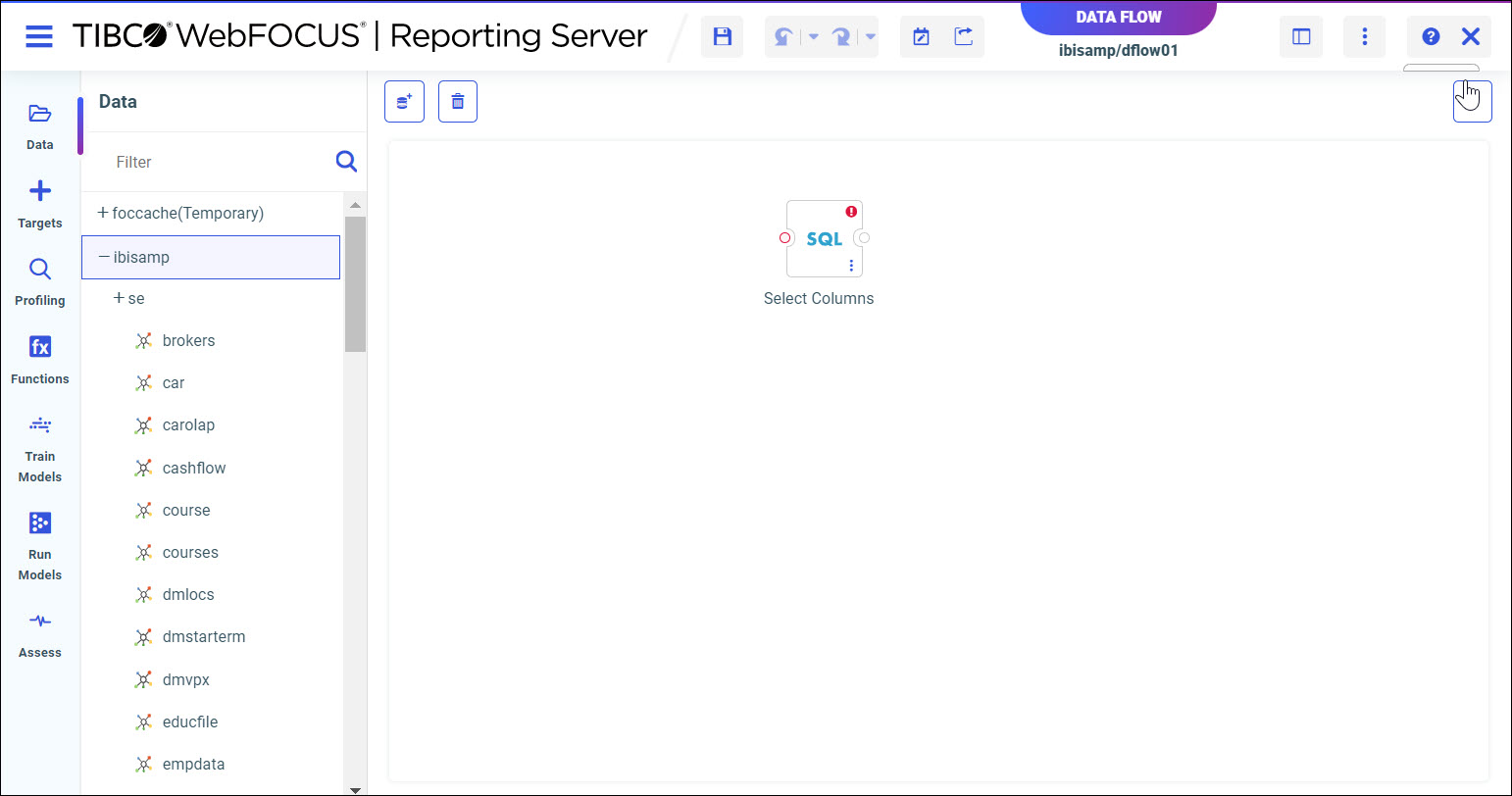
- From the Data panel, drag a data source onto the canvas, as shown in the following image.
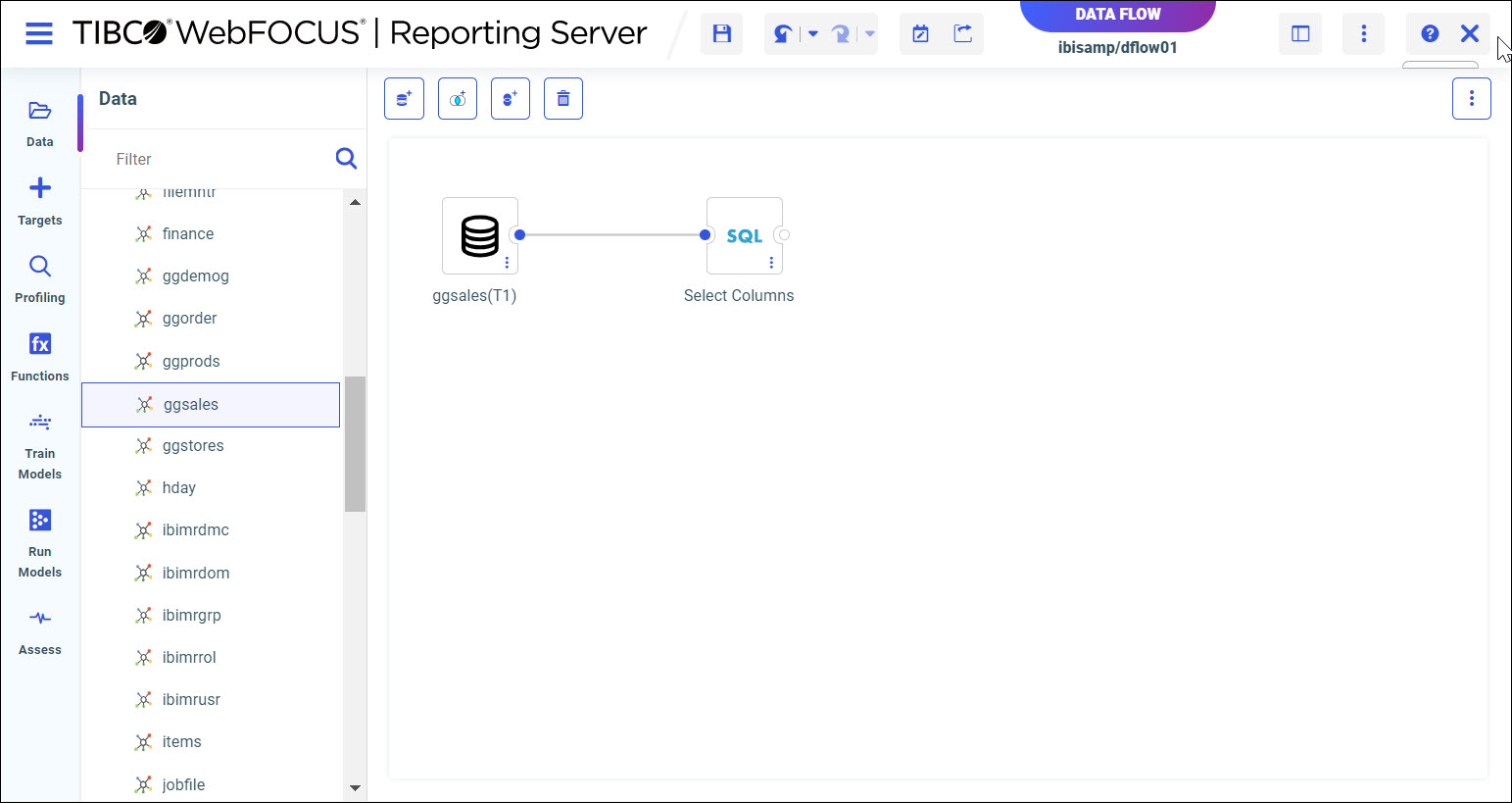
Note: Double-click a data source to display sample data.
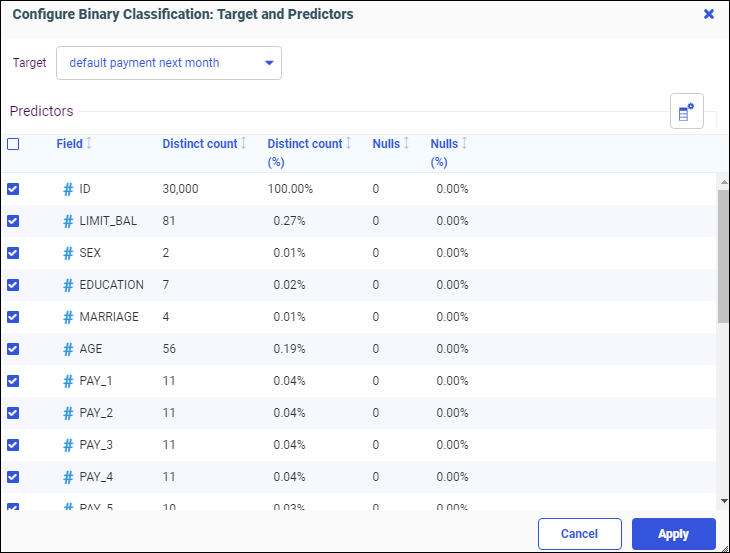
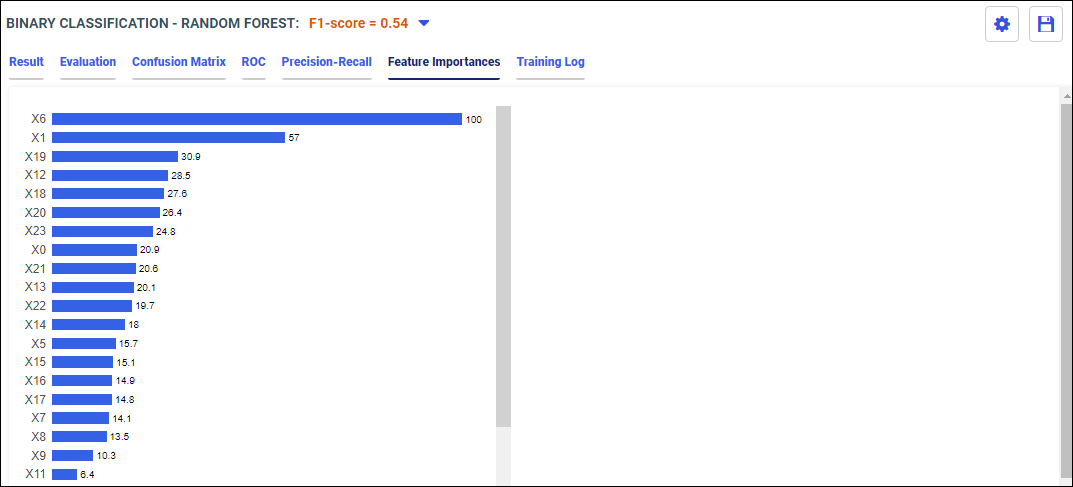
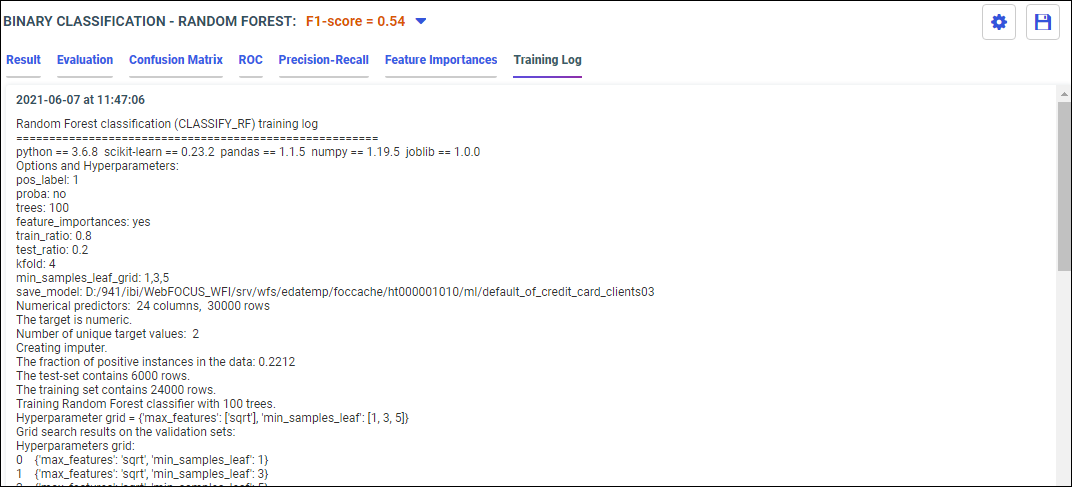
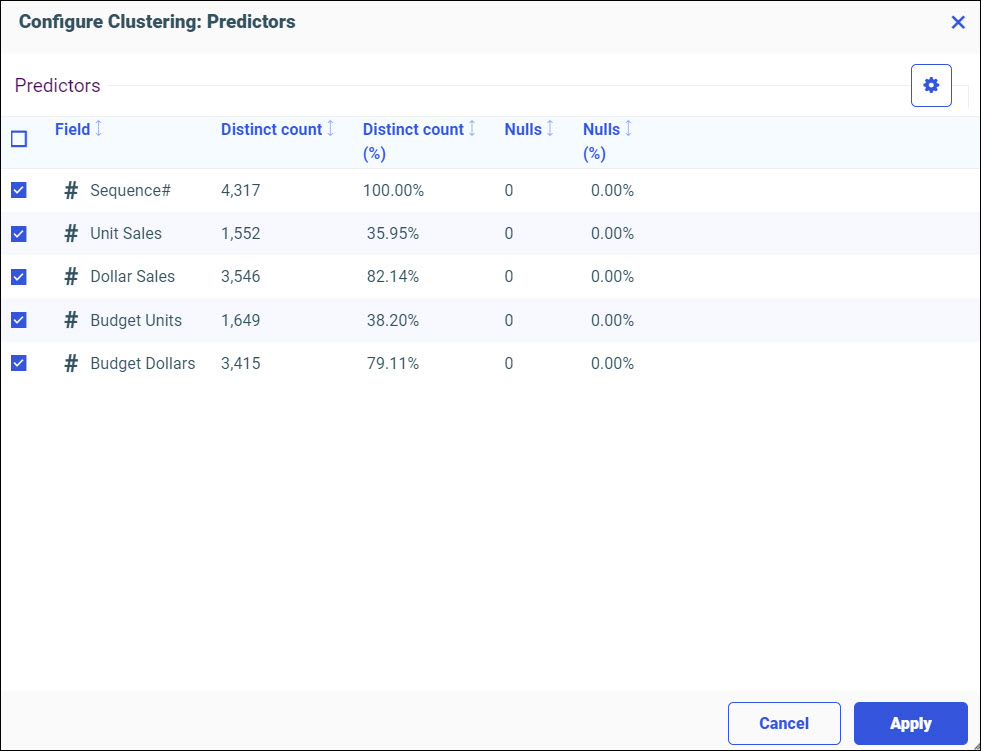
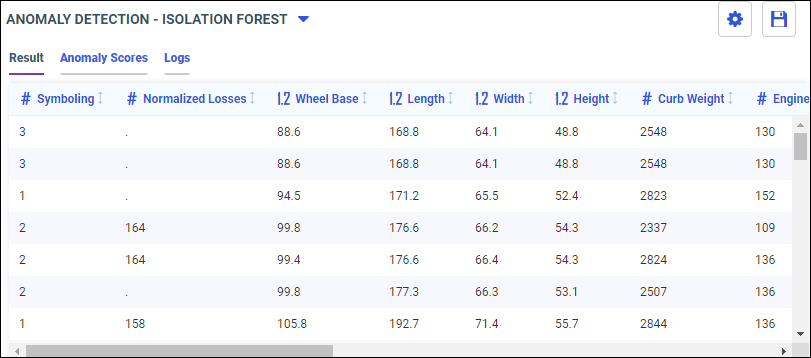
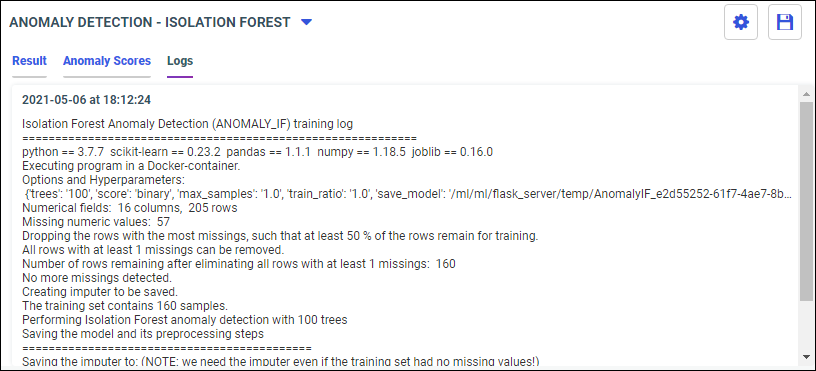
- From the side panel, click Train Models.
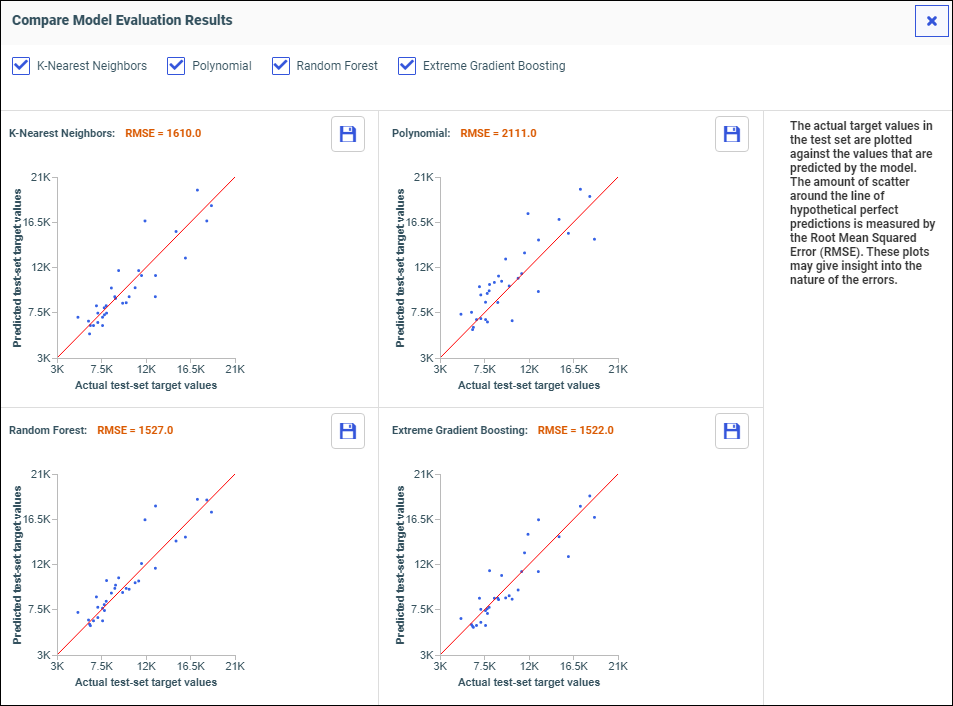
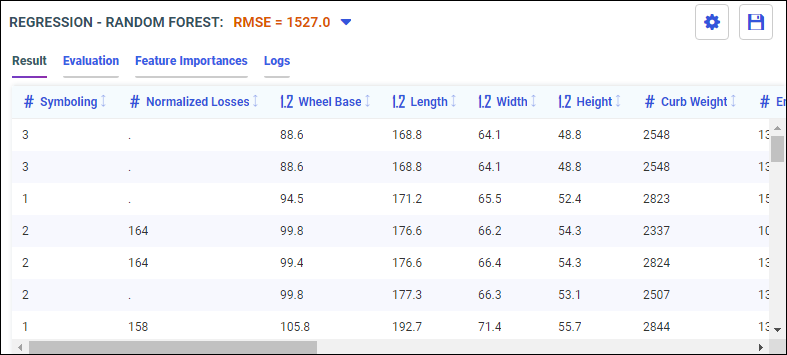
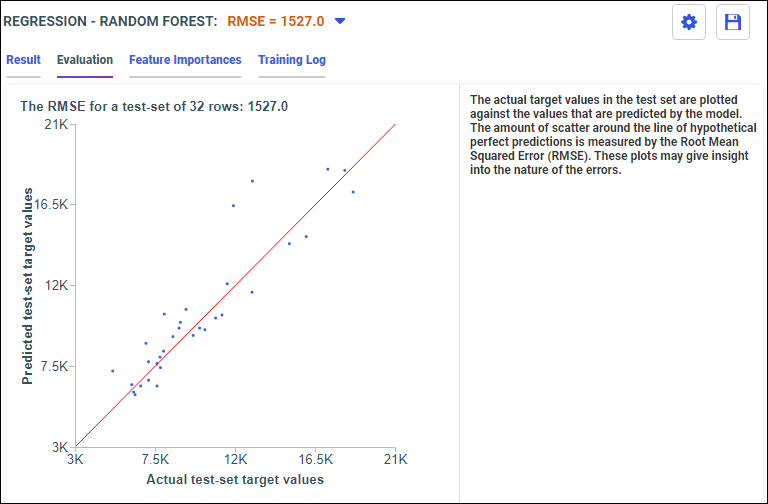
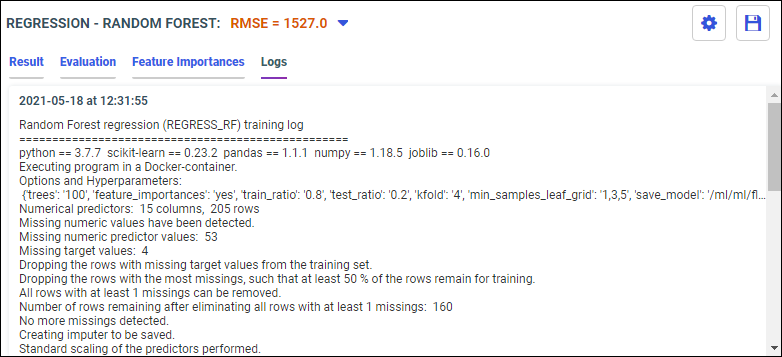
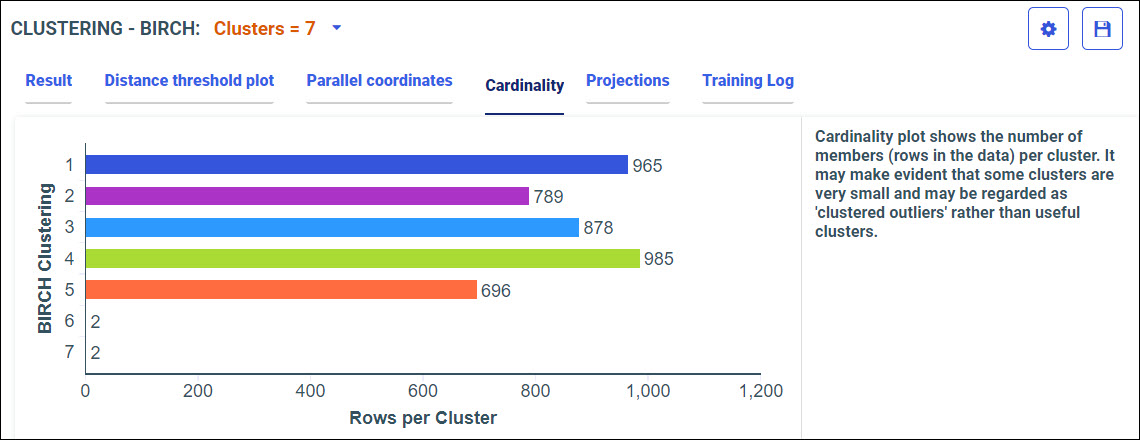
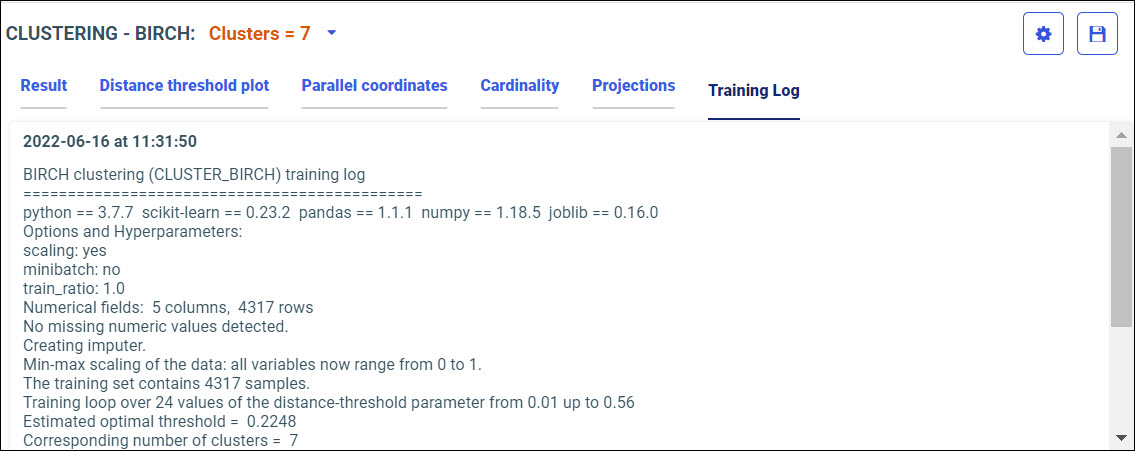
The Train Models panel opens, as shown in the following image.
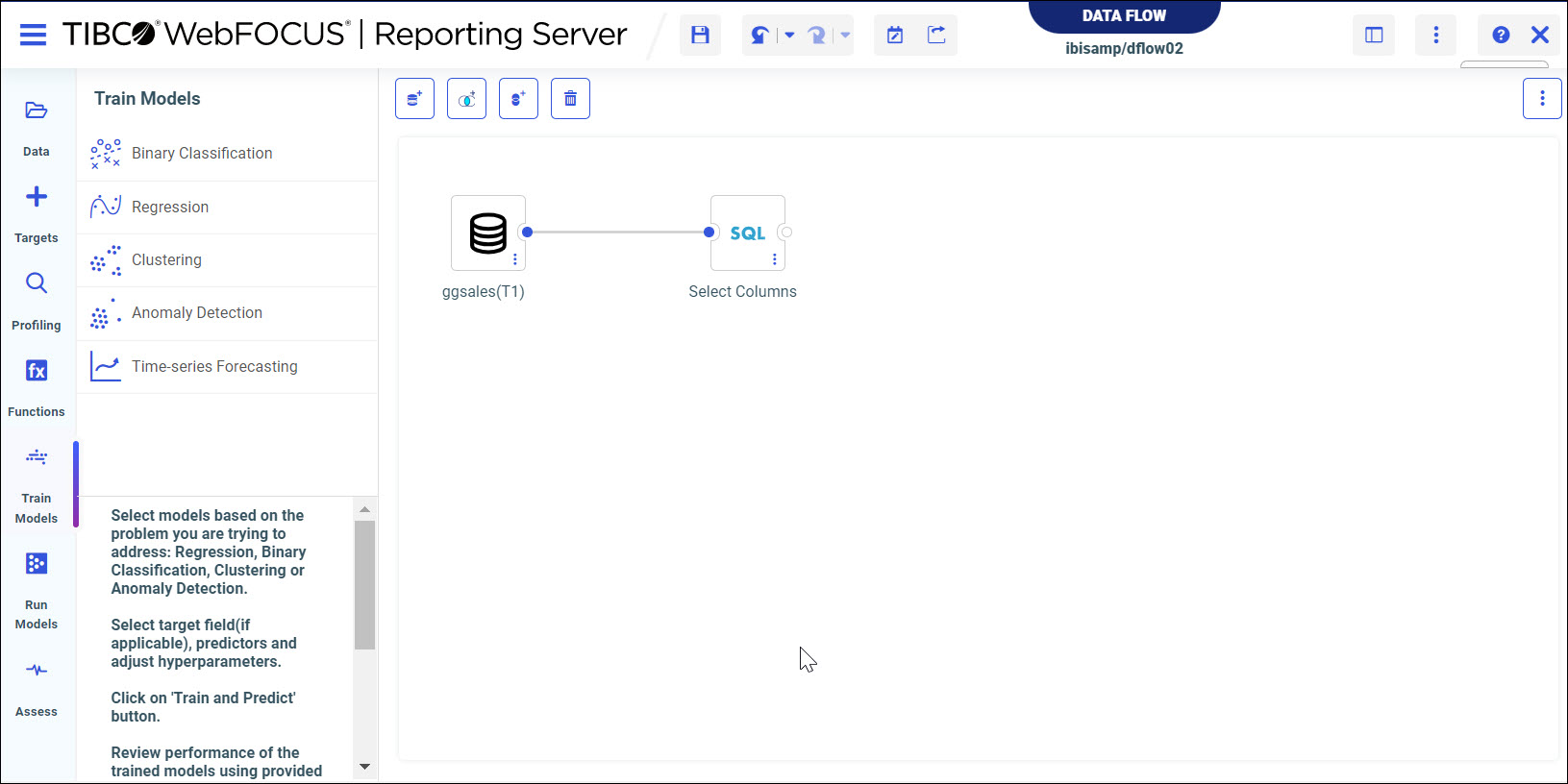
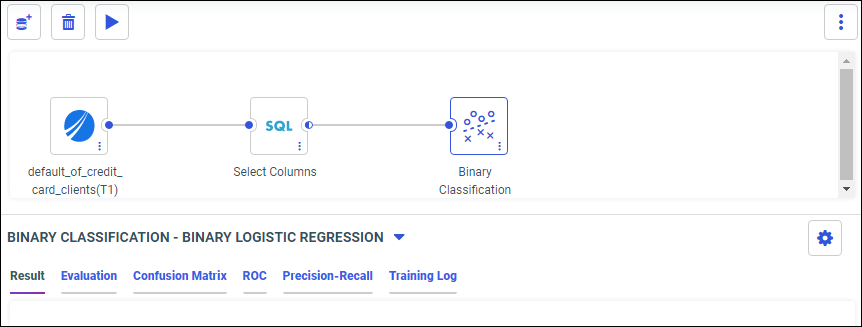
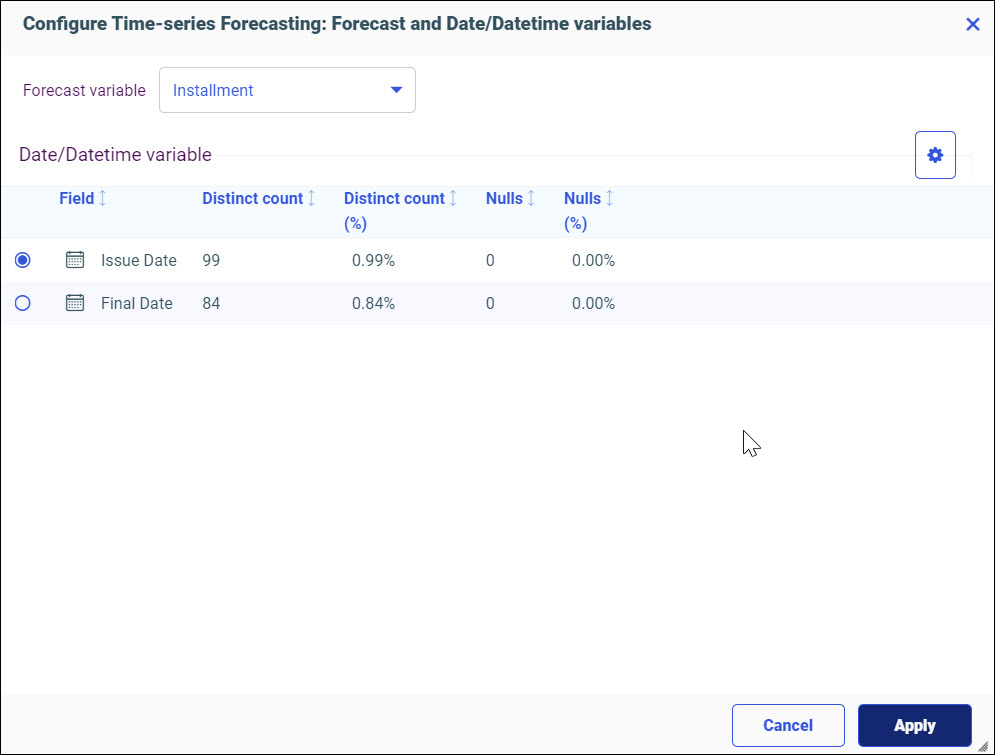
The following models display within the Train Models panel:
- Binary Classification
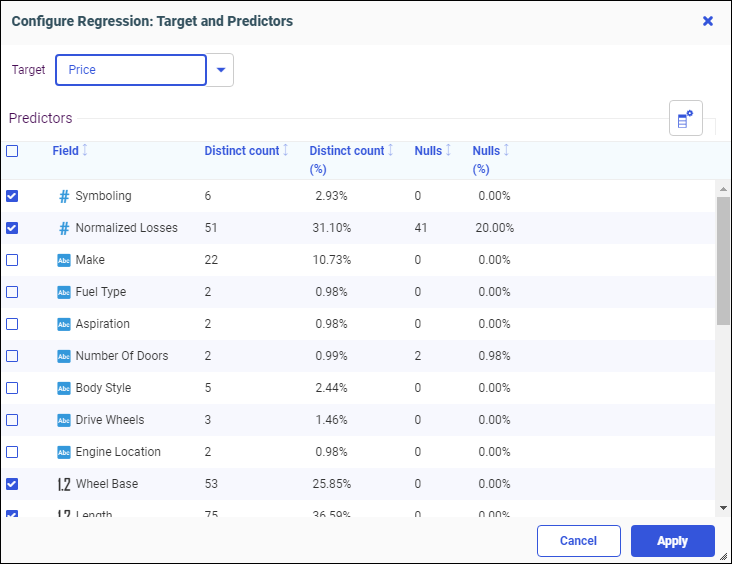
- Regression
- Clustering
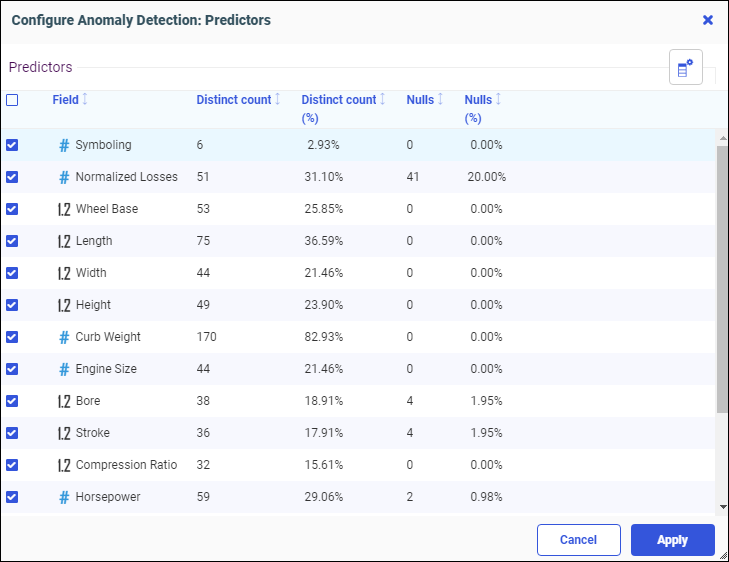
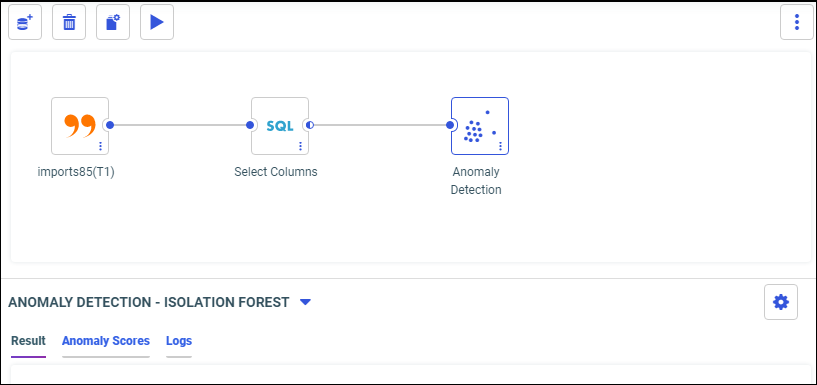
- Anomaly Detection
- Time-series Forecasting
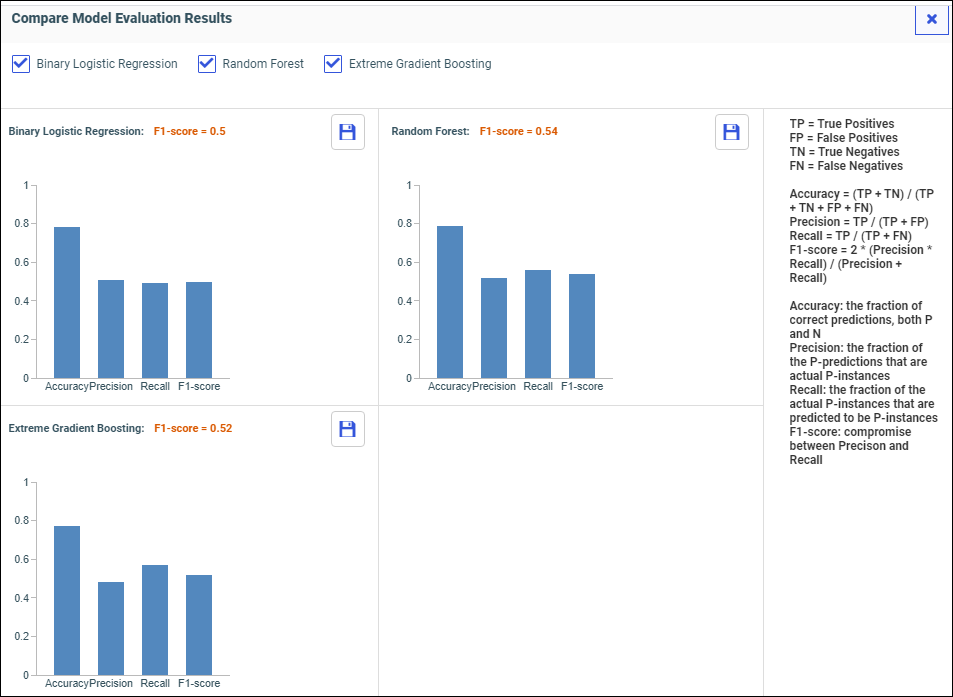
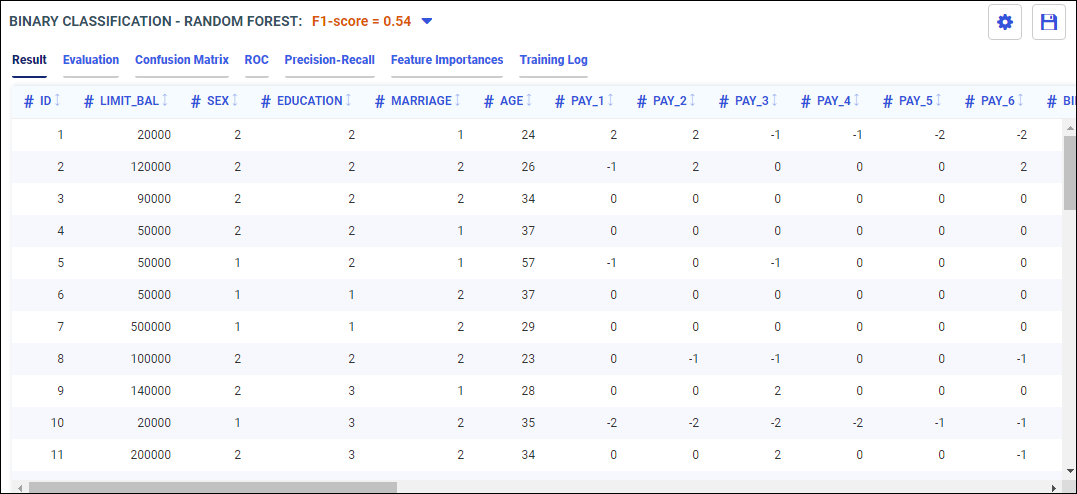
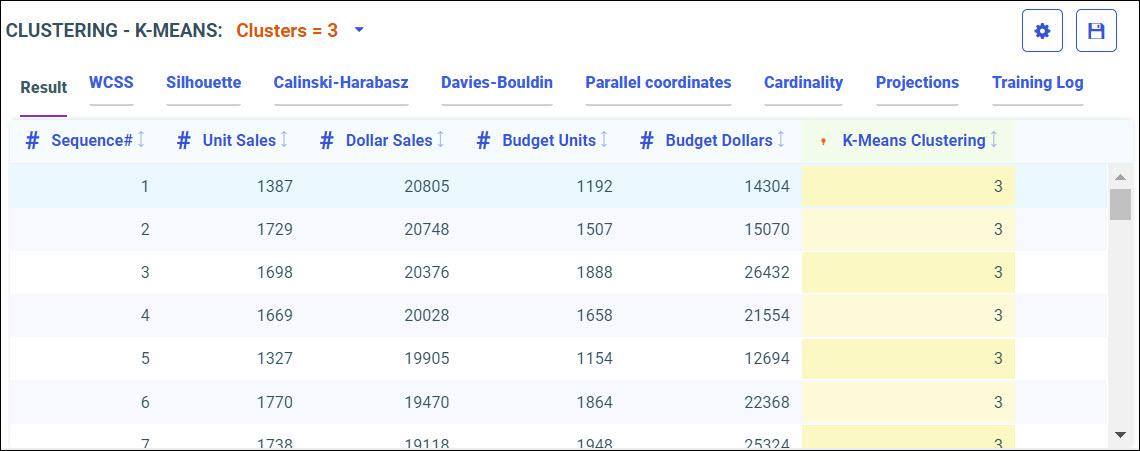
Now you can select a model to train and run against your data.