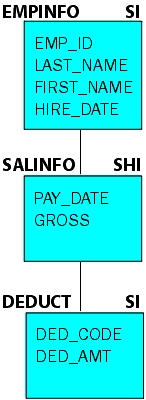
In order to use NEXT through several segments, specify
all the segments in one NEXT command or use several NEXT commands.
If all of the segments are placed into one NEXT command, there is
no way to know when data is retrieved from a parent segment and
when it is retrieved from a child. To have control over when each
segment is retrieved, each segment should have a NEXT command of
its own. In this way, the first NEXT establishes the position for
the second NEXT.
A NEXT command following a MATCH command works in a similar way.
The first command (MATCH) establishes the data source position.
In the following example, the REPOSITION command places the position
in the EmpInfo segment and all of its children to the beginning
of the chain. Both NEXT commands move forward to the first instance
in the appropriate segment:
REPOSITION Emp_ID;
NEXT Emp_ID;
NEXT Pay_Date;
If one of the NEXT commands uses the FOR prefix, it works the
same as described above, but rather than moving forward only one
segment instance, NEXT moves forward however many records the FOR
specifies. For example, the following retrieves the first instance
in the EmpInfo segment and the next three instances of the SalInfo
segment. All three records are for only one employee because the
first NEXT establishes the position:
REPOSITION Emp_ID;
NEXT Emp_ID;
FOR 3 NEXT Pay_Date INTO Stemp;
After this code is executed, the stack contains data from the
following segments:
- Emp_ID instance
1 and Pay_Date instance 1
- Emp_ID instance
1 and Pay_Date instance 2
- Emp_ID instance
1 and Pay_Date instance 3
Every NEXT command that uses a FOR prefix does so independent
of any other NEXT command. If there are two NEXT commands, the first
executes. When it is complete, the position is the last instance
retrieved. The second NEXT command then executes and retrieves data
from within the parent established by the first NEXT. In the following
example, the first NEXT retrieves the first two instances from the
EmpInfo segment and places the instances into the stack. The second
NEXT retrieves the next three instances of the SalInfo segment.
Note its parent instance is the second EmpInfo segment instance.
The stack variable FocCount indicates the number of rows currently
in the stack. The prefix Stemp is needed to indicate the stack.
STACK CLEAR Stemp;
REPOSITION Emp_ID;
FOR 2 NEXT Emp_ID INTO Stemp(1);
FOR 3 NEXT Pay_Date INTO Stemp(Stemp.FocCount);
The stack contains data from the following segments after the
first NEXT is executed:
- Emp_ID instance
1
- Emp_ID instance
2
The stack contains data from the following segments after the
second NEXT is executed:
- Emp_ID instance
1
- Emp_ID instance
2 and Pay_Date instance 1
- Emp_ID instance
2 and Pay_Date instance 2
- Emp_ID instance
2 and Pay_Date instance 3
The row in the INTO stack that the output is placed in is specified
by supplying the row number after the stack name. When two NEXT
commands are used in a row for the same stack, care must be taken
to ensure that data is written to the appropriate row in the stack. If
a stack row number is not specified for the second NEXT command,
data is placed into the last row written to by the first NEXT, and
existing data is overwritten. In order to place data in a different
row, a row number or an expression to calculate the row number can
be used. For example, the second NEXT command specifies the row
after the last row by adding one to the variable FocCount:
FOR 2 NEXT Emp_ID INTO Stemp(1);
FOR 3 NEXT Pay_Date INTO Stemp(Stemp.FocCount+1);
The stack now appears as follows. Notice that there is a new
row 2:
- Emp_ID instance
1
- Emp_ID instance
2
- Emp_ID instance
2 and Pay_Date instance 1
- Emp_ID instance
2 and Pay_Date instance 2
- Emp_ID instance
2 and Pay_Date instance 3
If a WHERE phrase is specified, the NEXT moves forward as many
times as necessary to retrieve one record that satisfies the selection
criteria specified in the WHERE phrase. For instance, the following
retrieves the next record where the Gross field of the child segment
is greater than 1,000. Like the previous example, the data retrieved
is only for the employee that the first NEXT retrieves:
NEXT Emp_ID;
NEXT Pay_Date WHERE Gross GT 1000;
If both a FOR prefix and a WHERE phrase are specified, the NEXT
moves forward as many times as necessary to retrieve the number
of records specified in the FOR prefix that satisfy the selection
criteria specified in the WHERE phrase.
For example, the following syntax retrieves the next three records
where the Gross field of the child segment is greater than 1,000.
As above, the data retrieved is only for the employee that the first
NEXT retrieves:
NEXT Emp_ID;
FOR 3 NEXT Pay_Date INTO Stemp WHERE Gross GT 1000;