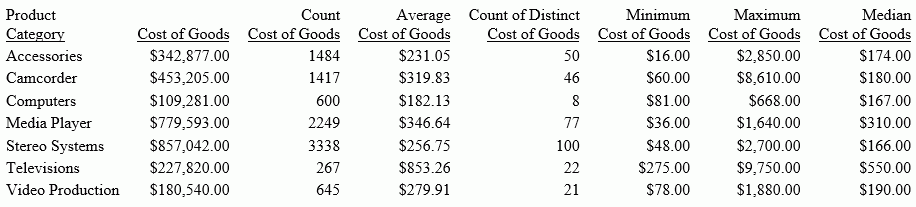
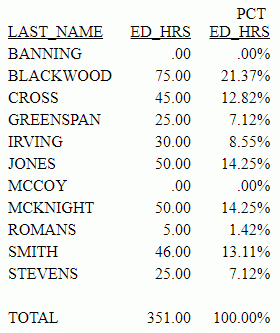
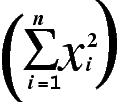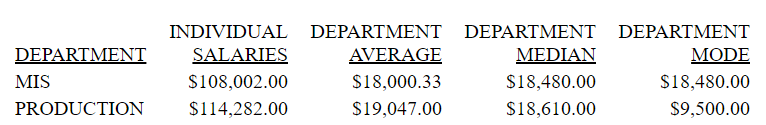In a PRINT command, COMPUTE expression,
or IF/WHERE TOTAL expression :
RNK.field ...
where:
- field
- Is a vertical (BY) sort field in the request.
Example: Ranking Within Sort Groups
The following request ranks years of
service within department and ranks salary within years of service
and department. Note that years of service depends on the value
of TODAY. The output for this example was valid when run in September,
2006:
DEFINE FILE EMPDATA
TODAY/YYMD = &YYMD;
YRS_SERVICE/I9 = DATEDIF(HIREDATE,TODAY,'Y');
END
TABLE FILE EMPDATA
PRINT SALARY
RNK.YRS_SERVICE AS 'RANKING,BY,SERVICE'
RNK.SALARY AS 'SALARY,RANK'
BY DEPT
BY HIGHEST YRS_SERVICE
BY HIGHEST SALARY NOPRINT
WHERE DEPT EQ 'MARKETING' OR 'SALES'
ON TABLE SET PAGE NOPAGE
ENDThe output is:
RANKING
BY SALARY
DEPT YRS_SERVICE SALARY SERVICE RANK
---- ----------- ------ ------- ------
MARKETING 17 $55,500.00 1 1
$55,500.00 1 1
16 $62,500.00 2 1
$62,500.00 2 1
$62,500.00 2 1
$58,800.00 2 2
$52,000.00 2 3
$35,200.00 2 4
$32,300.00 2 5
15 $50,500.00 3 1
$43,400.00 3 2
SALES 17 $115,000.00 1 1
$54,100.00 1 2
16 $70,000.00 2 1
$43,000.00 2 2
15 $43,600.00 3 1
$39,000.00 3 2
15 $30,500.00 3 3
Example: Using RNK. in a WHERE TOTAL Test
The following request displays only
those rows in the highest two salary ranks within the years of service
category. Note that years of service depends on the value of TODAY. The
output for this example was valid when run in September, 2006:
DEFINE FILE EMPDATA
TODAY/YYMD = &YYMD;
YRS_SERVICE/I9 = DATEDIF(HIREDATE,TODAY,'Y');
END
TABLE FILE EMPDATA
PRINT LASTNAME FIRSTNAME RNK.SALARY
BY HIGHEST YRS_SERVICE BY HIGHEST SALARY
WHERE TOTAL RNK.SALARY LE 2
END
The output is:
RANK
YRS_SERVICE SALARY LASTNAME FIRSTNAME SALARY
----------- ------ -------- --------- ------
17 $115,000.00 LASTRA KAREN 1
$80,500.00 NOZAWA JIM 2
16 $83,000.00 SANCHEZ EVELYN 1
$70,000.00 CASSANOVA LOIS 2
15 $62,500.00 HIRSCHMAN ROSE 1
WANG JOHN 1
$50,500.00 LEWIS CASSANDRA 2
Example: Using RNK. in a COMPUTE Command
The following request sets a flag to Y for
records in which the salary rank within department is less than
or equal to 5 and the rank of years of service within salary and
department is less than or equal to 6. Otherwise, the flag has the
value N. Note that the years of service depends
on the value of TODAY. The output for this example was valid when
run in September, 2006:
DEFINE FILE EMPDATA
TODAY/YYMD = &YYMD;
YRS_SERVICE/I9 = DATEDIF(HIREDATE,TODAY,'Y');
END
TABLE FILE EMPDATA
PRINT RNK.SALARY RNK.YRS_SERVICE
COMPUTE FLAG/A1 = IF RNK.SALARY LE 5 AND RNK.YRS_SERVICE LE 6
THEN 'Y' ELSE 'N';
BY DEPT BY SALARY BY YRS_SERVICE
WHERE DEPT EQ 'MARKETING' OR 'SALES'
ON TABLE SET PAGE NOPAGE
ENDThe output is:
RANK RANK
DEPT SALARY YRS_SERVICE SALARY YRS_SERVICE FLAG
---- ------ ----------- ------ ----------- ----
MARKETING $32,300.00 16 1 1 Y
$35,200.00 16 2 1 Y
$43,400.00 15 3 1 Y
$50,500.00 15 4 1 Y
$52,000.00 16 5 1 Y
$55,500.00 17 6 1 N
6 1 N
$58,800.00 16 7 1 N
$62,500.00 16 8 1 N
8 1 N
8 1 N
SALES $30,500.00 15 1 1 Y
$39,000.00 15 2 1 Y
$43,000.00 16 3 1 Y
$43,600.00 15 4 1 Y
$54,100.00 17 5 1 Y
$70,000.00 16 6 1 N
$115,000.00 17 7 1 N