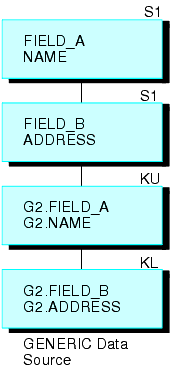
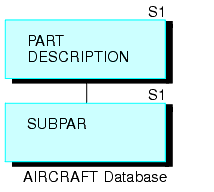
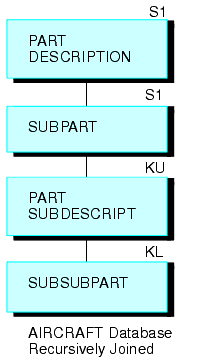
|
In this section: |
|
Reference: |
When you join two data sources, some records in one of the files may lack corresponding records in the other file. When a report omits records that are not in both files, the join is called an inner join. When a report displays all matching records, plus all records from the host file that lack corresponding cross-referenced records, the join is called a left outer join. When a report displays all matching records plus all records from both files that lack corresponding records in the other file, the join is called a full outer join. Full outer joins are supported for relational data sources only.
The SET ALL command globally determines how all joins are implemented. If the SET ALL=ON command is issued, all joins are treated as outer joins. With SET ALL=OFF, the default, all joins are treated as inner joins.
Each JOIN command can specify explicitly which type of join to perform, locally overruling the global setting. This syntax is supported for FOCUS, XFOCUS, Relational, VSAM, IMS, and Adabas. If you do not specify the type of join in the JOIN command, the ALL parameter setting determines the type of join to perform.
You can also join data sources using one of two techniques for determining how to match records from the separate data sources. The first technique is known as an equijoin and the second is known as a conditional join. When deciding which of the two join techniques to use, it is important to know that when there is an equality condition between two data sources, it is more efficient to use an equijoin rather than a conditional join.
You can use an equijoin structure when you are joining two or more data sources that have two fields, one in each data source, with formats (character, numeric, or date) and values in common. Joining a product code field in a sales data source (the host file) to the product code field in a product data source (the cross-referenced file) is an example of an equijoin. For more information on using equijoins, see Creating an Equijoin.
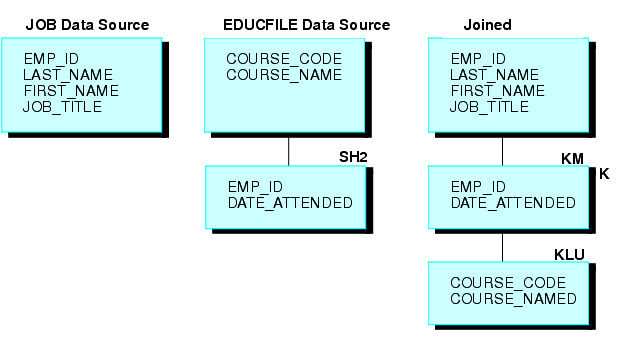
The conditional join uses WHERE-based syntax to specify joins based on WHERE criteria, not just on equality between fields. Additionally, the host and cross-referenced join fields do not have to contain matching formats. Suppose you have a data source that lists employees by their ID number (the host file), and another data source that lists training courses and the employees who attended those courses (the cross-referenced file). Using a conditional join, you could join an employee ID in the host file to an employee ID in the cross-referenced file to determine which employees took training courses in a given date range (the WHERE condition). For more information on conditional joins, see Using a Conditional Join.
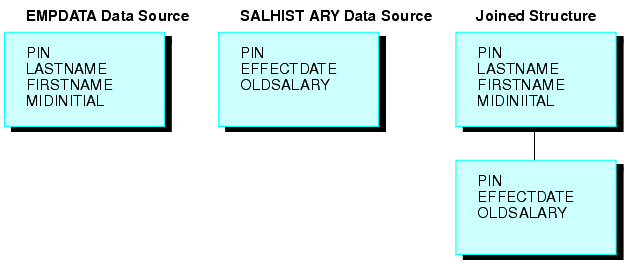
Joins can also be unique or non-unique. A unique, or one-to-one, join structure matches one value in the host data source to one value in the cross-referenced data source. Joining an employee ID in an employee data source to an employee ID in a salary data source is an example of a unique equijoin structure.
A non-unique, or one-to-many, join structure matches one value in the host data source to multiple values in the cross-referenced field. Joining an employee ID in a company's employee data source to an employee ID in a data source that lists all the training classes offered by that company results in a listing of all courses taken by each employee, or a joining of the one instance of each ID in the host file to the multiple instances of that ID in the cross-referenced file.
For more information on unique and non-unique joins, see Unique and Non-Unique Joined Structures.
Example: Joined Data Structure
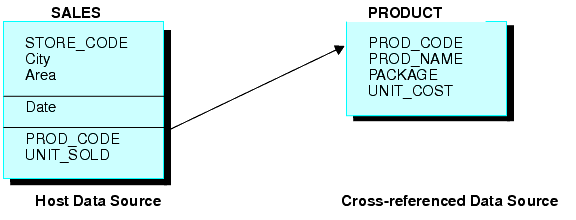
Consider the SALES and PRODUCT data sources. Each store record in SALES may contain many instances of the PROD_CODE field. It would be redundant to store the associated product information with each instance of the product code. Instead, PROD_CODE in the SALES data source is joined to PROD_CODE in the PRODUCT data source. PRODUCT contains a single instance of each product code and related product information, thus saving space and making it easier to maintain product information. The joined structure, which is an example of an equijoin, is illustrated below: