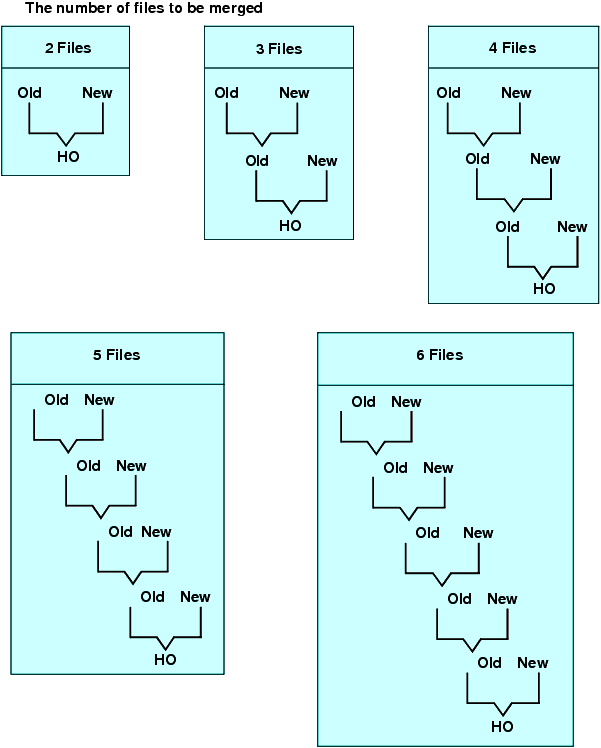
Reference: Usage Notes for Match Requests
- With ungrouped processing, you cannot specify a format for the HOLD file generated by MATCH. It will be created as a single-segment BINARY or ALPHA HOLD file, depending on the value of the HOLDFORMAT parameter. The merge process does not change the original data sources.
- Alias names are assigned sequentially (E01, E02, ...) in the
HOLD Master File that results from the MATCH request. When the same
field name is used mutliple times in the MATCH, users distinguish
between them in requests against the HOLD file by referencing these
alias names instead of the field names.
With grouped processing, fields are rearranged in the Master File, and this causes the alias names to represent different fields from the same alias names assigned with ungrouped processing. This can produce different results if you switch from one type of processing to the other.
To avoid using alias names, use the AS phrase in your MATCH request to create distinct field names (except for the common high-order BY fields, which have to be the same), and use those field names in requests against the HOLD file.
- The ACROSS, BY HIGHEST/LOWEST n, IN-GROUPS-OF, WHERE TOTAL, and IF TOTAL phrases, and the COMPUTE command, are not permitted in a MATCH request. You can, however, use the DEFINE command.
- Up to 128 BY phrases and the maximun
number of display fields can be used in each MATCH request. The
count of sort sets includes the number of common sort fields. The
maximum number of display fields is determined by a combination
of factors.
For details, see Displaying Report Data.
- You must specify at least one BY field for each file used in the MATCH request.
- When used with MATCH, the SET HOLDLIST parameter behaves as if HOLDLIST were set to ALL.
- The following prefix operators are not supported in MATCH requests: DST., DST.CNT., RNK., ST., and CT.
Example: Merging Data Sources
In the following request, the high-order sort field is the same for both files, so the result is the same using grouped and ungrouped processing.
MATCH FILE EDUCFILE SUM COURSE_CODE BY EMP_ID RUN FILE EMPLOYEE SUM LAST_NAME AND FIRST_NAME BY EMP_ID BY CURR_SAL AFTER MATCH HOLD OLD-OR-NEW END -****************************** -* PRINT CONTENTS OF HOLD FILE -****************************** TABLE FILE HOLD PRINT * END
The merge phrase used in this example was OLD-OR-NEW. This means that records from both the first (old) data source plus the records from the second (new) data source appear in the HOLD file.
The output is:
EMP_ID COURSE_CODE CURR_SAL LAST_NAME FIRST_NAME ------ ----------- -------- --------- ---------- 071382660 101 $11,000.00 STEVENS ALFRED 112847612 103 $13,200.00 SMITH MARY 117593129 203 $18,480.00 JONES DIANE 119265415 108 $9,500.00 SMITH RICHARD 119329144 $29,700.00 BANNING JOHN 123764317 $26,862.00 IRVING JOAN 126724188 $21,120.00 ROMANS ANTHONY 212289111 103 $.00 219984371 $18,480.00 MCCOY JOHN 315548712 108 $.00 326179357 301 $21,780.00 BLACKWOOD ROSEMARIE 451123478 101 $16,100.00 MCKNIGHT ROGER 543729165 $9,000.00 GREENSPAN MARY 818692173 302 $27,062.00 CROSS BARBARA
Example: Comparing Grouped and Ungrouped Processing
The following MATCH request has two SUM commands and one PRINT command for each file, with all sort fields common to both files. The SET MATCHCOLUMNORDER = UNGROUPED command is issued to invoke legacy processing.
SET MATCHCOLUMNORDER = UNGROUPED MATCH FILE GGSALES SUM DOLLARS BY ST SUM BUDDOLLARS BY ST BY CITY PRINT UNITS BY ST BY CITY BY CATEGORY RUN FILE GGSALES SUM DOLLARS BY ST SUM BUDDOLLARS BY ST BY CITY PRINT BUDUNITS BY ST BY CITY BY CATEGORY AFTER MATCH HOLD OLD-OR-NEW END TABLE FILE HOLD PRINT * ON TABLE SET PAGE NOLEAD ON TABLE SET STYLE * TYPE=REPORT, GRID=OFF, SIZE=9,$ ENDSTYLE END
The HOLD Master File follows. Since the sort fields are common to both files, the two files were merged based on those fields. However, note that the order of fields in the Master File follows the order in the request, the highest-level sort field followed by its display field, then the next sort field followed by its display fields, and so on.
FILENAME=HOLD, SUFFIX=FIX , IOTYPE=BINARY, $
SEGMENT=HOLD, SEGTYPE=S1, $
FIELDNAME=ST, ALIAS=E01, USAGE=A02, ACTUAL=A04, $
FIELDNAME=DOLLARS, ALIAS=E02, USAGE=I08, ACTUAL=I04, $
FIELDNAME=CITY, ALIAS=E03, USAGE=A20, ACTUAL=A20, $
FIELDNAME=BUDDOLLARS, ALIAS=E04, USAGE=I08, ACTUAL=I04, $
FIELDNAME=CATEGORY, ALIAS=E05, USAGE=A11, ACTUAL=A12, $
FIELDNAME=UNITS, ALIAS=E06, USAGE=I08, ACTUAL=I04, $
FIELDNAME=DOLLARS, ALIAS=E07, USAGE=I08, ACTUAL=I04, $
FIELDNAME=BUDDOLLARS, ALIAS=E08, USAGE=I08, ACTUAL=I04, $
FIELDNAME=BUDUNITS, ALIAS=E09, USAGE=I08, ACTUAL=I04, $The partial output is shown in the following image.
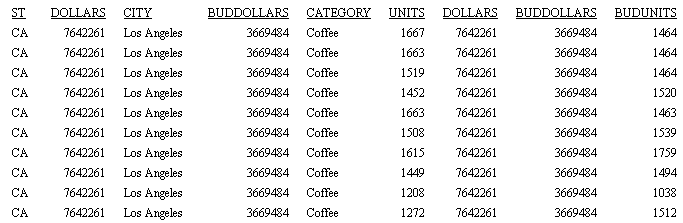
Changing the UNGROUPED setting to GROUPED produces the following Master File. The fields that have the same common sort fields from both files are moved to be under those sort fields in the Master File.
FILENAME=HOLD, SUFFIX=FIX , IOTYPE=BINARY, $
SEGMENT=HOLD, SEGTYPE=S1, $
FIELDNAME=ST, ALIAS=E01, USAGE=A02, ACTUAL=A04, $
FIELDNAME=DOLLARS, ALIAS=E02, USAGE=I08, ACTUAL=I04, $
FIELDNAME=DOLLARS, ALIAS=E03, USAGE=I08, ACTUAL=I04, $
FIELDNAME=CITY, ALIAS=E04, USAGE=A20, ACTUAL=A20, $
FIELDNAME=BUDDOLLARS, ALIAS=E05, USAGE=I08, ACTUAL=I04, $
FIELDNAME=BUDDOLLARS, ALIAS=E06, USAGE=I08, ACTUAL=I04, $
FIELDNAME=CATEGORY, ALIAS=E07, USAGE=A11, ACTUAL=A12, $
FIELDNAME=UNITS, ALIAS=E08, USAGE=I08, ACTUAL=I04, $
FIELDNAME=BUDUNITS, ALIAS=E09, USAGE=I08, ACTUAL=I04, $The partial output is shown in the following image.

For the request that uses the GROUPED value for MATCHCOLUMNORDER, you can change the HOLD command to produce a FORMAT FOCUS output file, as follows.
AFTER MATCH HOLD FORMAT FOCUS OLD-OR-NEW
The following hierarchical multi-segment Master File is generated.
FILENAME=HOLD , SUFFIX=FOC , $
SEGMENT=SEG01, SEGTYPE=S1, $
FIELDNAME=ST, ALIAS=E01, USAGE=A02,
TITLE='State', DESCRIPTION='State', $
FIELDNAME=DOLLARS, ALIAS=E02, USAGE=I08,
TITLE='Dollar Sales', DESCRIPTION='Total dollar amount of reported sales', $
FIELDNAME=DOLLARS, ALIAS=E03, USAGE=I08,
TITLE='Dollar Sales', DESCRIPTION='Total dollar amount of reported sales', $
SEGMENT=SEG02, SEGTYPE=S1, PARENT=SEG01, $
FIELDNAME=CITY, ALIAS=E04, USAGE=A20,
TITLE='City', DESCRIPTION='City', $
FIELDNAME=BUDDOLLARS, ALIAS=E05, USAGE=I08,
TITLE='Budget Dollars', DESCRIPTION='Total sales quota in dollars', $
FIELDNAME=BUDDOLLARS, ALIAS=E06, USAGE=I08,
TITLE='Budget Dollars', DESCRIPTION='Total sales quota in dollars', $
SEGMENT=SEG03, SEGTYPE=S2, PARENT=SEG02, $
FIELDNAME=CATEGORY, ALIAS=E07, USAGE=A11,
TITLE='Category', DESCRIPTION='Product category', $
FIELDNAME=FOCLIST, ALIAS=E08, USAGE=I5, $
FIELDNAME=UNITS, ALIAS=E09, USAGE=I08,
TITLE='Unit Sales', DESCRIPTION='Number of units sold', $
SEGMENT=SEG04, SEGTYPE=S1, PARENT=SEG03, $
FIELDNAME=FOCLIST, ALIAS=E10, USAGE=I5, $
FIELDNAME=BUDUNITS, ALIAS=E11, USAGE=I08,
TITLE='Budget Units', DESCRIPTION='Number of units budgeted', $