Describing a Unique Join: SEGTYPE = KU
|
How to: |
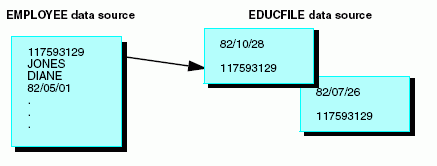
In the EMPLOYEE data source, there is a field named JOBCODE in the PAYINFO segment. The JOBCODE field contains a code that specifies the employee job.
The complete description of the job and other related information is stored in a separate data source named JOBFILE. You can retrieve the job description from JOBFILE by locating the record whose JOBCODE corresponds to the JOBCODE value in the EMPLOYEE data source, as shown in the following diagram:
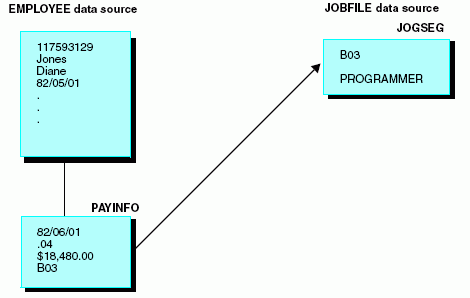
Using a join in this situation saves you the trouble of entering and revising the job description for every record in the EMPLOYEE data source. Instead, you can maintain a single list of valid job descriptions in the JOBFILE data source. Changes need be made only once, in JOBFILE, and are reflected in all of the corresponding joined EMPLOYEE data source records.
Implementing the join as a static join is most efficient because the relationship between job codes and job descriptions is not likely to change.
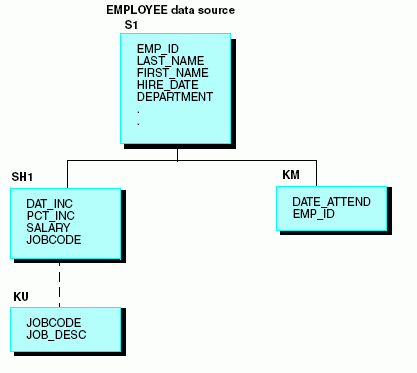
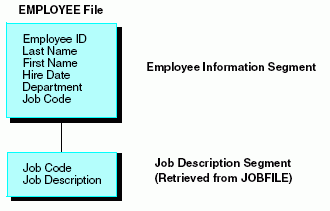
Although the Employee Information and Job Description segments are stored in separate data sources, for reporting purposes the EMPLOYEE data source is treated as though it also contains the Job Description segment from the JOBFILE data source. The actual structure of the JOBFILE data source is not affected.
The EMPLOYEE data source is viewed as follows:
Syntax: How to Specify a Static Unique Join
SEGNAME = segname, SEGTYPE = KU, PARENT = parent, CRFILE = db_name, CRKEY = field, [CRSEGNAME = crsegname,] [DATASET = physical_filename,] $
where:
- segname
-
Is the name by which the cross-referenced segment will be known in the host data source. You can assign any valid segment name, including the original name of the segment in the cross-referenced data source.
- parent
-
Is the name of the host segment.
- db_name
-
Is the name of the cross-referenced data source. You can change the name without rebuilding the data source.
- field
-
Is the common name (field name or alias) of the host field and the cross-referenced field. The field name or alias of the host field must be identical to the field name of the cross-referenced field. You can change the field name without rebuilding the data source as long as the SEGTYPE remains the same.
Both fields must have the same format type and length.
The cross-referenced field must be indexed (FIELDTYPE=I or INDEX=I).
- crsegname
-
Is the name of the cross-referenced segment. If you do not specify this, it defaults to the value assigned to SEGNAME. After data has been entered into the cross-referenced data source, you cannot change the crsegname without rebuilding the data source.
- physical_filename
-
Optionally, is the platform-dependent physical name of the data source for the CRFILE.
The SEGTYPE value KU stands for keyed unique.
Example: Creating a Static Unique Join
SEGNAME = JOBSEG, SEGTYPE = KU, PARENT = PAYINFO, CRFILE = JOBFILE, CRKEY = JOBCODE, $
The relevant sections of the EMPLOYEE Master File follow (nonessential fields and segments are not shown):
FILENAME = EMPLOYEE, SUFFIX = FOC, $ SEGNAME = EMPINFO, SEGTYPE = S1, $ . . . SEGNAME = PAYINFO, SEGTYPE = SH1, PARENT = EMPINFO, $ FIELDNAME = JOBCODE, ALIAS = JBC, FORMAT = A3, $ . . . SEGNAME = JOBSEG, SEGTYPE = KU, PARENT = PAYINFO, CRFILE = JOBFILE, CRKEY = JOBCODE, $
Note that you only have to give the name of the cross-referenced segment. The fields in that segment are already known from the cross-referenced data source Master File (JOBFILE in this example). Note that the CRSEGNAME attribute is omitted, since in this example it is identical to the name assigned to the SEGNAME attribute.
The Master File of the cross-referenced data source, as well as the data source itself, must be accessible whenever the host data source is used. There does not need to be any data in the cross-referenced data source.