Fault Tolerance
Fault tolerance is the ability of the system to continue processing requests when an unexpected failure occurs on one of the AppNodes in the AppSpace.
- Distributes the incoming request load among other AppNodes in the AppSpace.
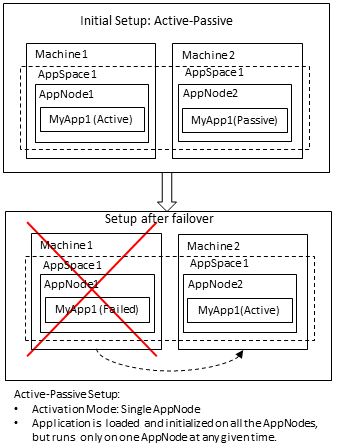
- If an AppNode that has an application in active state fails, another AppNode that has an application in the passive (stand-by) state takes over and starts processing requests.
- The check-pointed job data from an application in the failed AppNode can be recovered by another AppNode.
- If an application is in the standby or disabled mode, the status in the Components tab in Admin UI changes to Stopped, and the starter state displayed in the command line changes to Not Active. For more information on retrieving the list of components, see Retrieving list of components in an Application.
ActiveMatrix BusinessWorks fault tolerance feature can be classified into two types: Managed Fault Tolerance and Non-Managed Fault Tolerance.
Managed Fault Tolerance
In managed fault tolerance, when an AppNode fails, the application on another AppNode takes over automatically. The AppNodes in an AppSpace are aware of each other’s existence and the engines collaborate to provide fault tolerance.
- The engine persistence mode (bw.engine.persistenceMode) to be set to type group. The persistence mode of type group requires both database and group provider configurations. See Engine Persistence Modes for details.
- A minimum of two AppNodes in an AppSpace.
The managed fault tolerance configuration supports both the application activation modes - Single AppNode and Multiple AppNodes. See Application Activation Modes for details. The following table lists the managed fault tolerance features available for each of the activation modes.
| Single AppNode (Active-Passive) | Multiple AppNode (Active-Active) |
|---|---|
| The incoming requests are only processed by an AppNode where the application is in an active state. | The incoming requests can be processed by any AppNode since the application is active in all AppNodes. |
| On failure of an AppNode that has the application in an active state will automatically enable the application in another AppNode to take over and start processing requests. | On failure of an AppNode, other AppNodes will continue to process new requests. |
| The check pointed data from an application in the failed AppNode can be recovered by the application that is automatically enabled in another AppNode. | The check pointed data from an application in the failed AppNode can be automatically recovered by another AppNode. |
Non-managed Fault Tolerance
In non-managed fault tolerance, the AppNodes in an AppSpace are not aware of each other's existence and there is no collaboration between the engines. Consequently, if an AppNode fails, then another AppNode in the AppSpace will not take over.
- The engine persistence mode (bw.engine.persistenceMode) to be set to type datastore. The persistence mode of type datastore requires database configurations. See Engine Persistence Modes for details.
- If there are multiple AppNodes in the AppSpace, then each AppNode must be configured with a unique database configuration. An AppNode specific database configuration is stated through the AppNode config.ini file.
- The incoming requests can be processed by any AppNode since the application is active in all AppNodes.
- On failure on an AppNode, other AppNodes will continue to process new requests.
- An application can have checkpoint; however on failure of an AppNode; other AppNode will not recover the check-pointed data.