TIBCO ActiveSpaces® Transactions uses a quorum mechanism to detect, and optionally, prevent partitions from becoming active on multiple nodes. When a partition is active on multiple nodes a multiple master, or split-brain, scenario has occurred. A partition can become active on multiple nodes when connectivity between one or more nodes in a cluster is lost, but the nodes themselves remain active. Connectivity between nodes can be lost for a variety of reasons, including network router, network interface card, or cable failures.
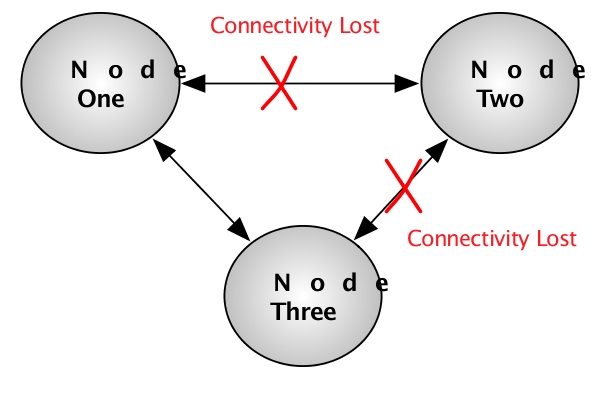
Figure 7.8, “Multi-master scenario” shows a situation where
a partition may be active on multiple nodes if partitions exist that have
all of these nodes in their node list. In this case, Node
Two assumes that Node One and Node
Three are down, and makes itself the active node for these
partitions. A similar thing happens on Node One and
Node Three - they assume Node Two is
down and take over any partitions that were active on Node
Two. At this point these partitions have multiple active nodes
that are unaware of each other.
The node quorum mechanism provides these mutually exclusive methods to determine whether a node quorum exists:
When using the minimum number of active remote nodes to determine a node quorum, the node quorum is not met when the number of active remote nodes drops below the configured minimum number of active nodes.
When using voting percentages, the node quorum is not met when the percentage of votes in a cluster drops below the configured node quorum percentage. By default each node is assigned one vote. However, this can be changed using configuration. This allows certain nodes to be given more weight in the node quorum calculation by assigning them a larger number of votes.
When node quorum monitoring is enabled, high-availability services
are Disabled if a node quorum is not met. This ensures
that partitions can never be active on multiple nodes. When a node quorum
is restored, by remote nodes being rediscovered, the node state is set to
Partial or Active depending on the
number of active remote nodes and the node quorum mechanism being used.
See the section called “Node quorum states” for complete details on
node quorum states.
See the TIBCO ActiveSpaces® Transactions Administration Guide for details on designing and configuring node quorum support.
The valid node quorum states are defined in Table 7.3, “Node quorum states”.
Table 7.3. Node quorum states
Figure 7.9, “Quorum state machine - minimum number of active remote nodes” shows the state machine that controls the transitions between all of these states when node quorum is using the minimum number of active nodes method to determine whether a quorum exists.
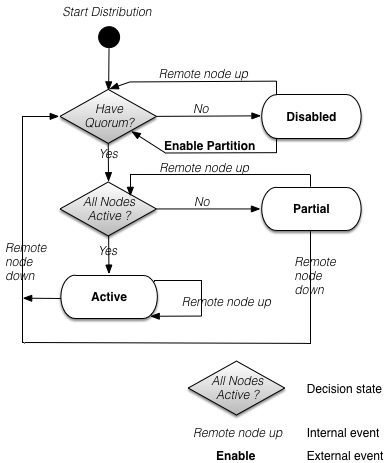
Figure 7.10, “Quorum state machine - voting” shows the state machine that controls the transitions between all of these states when node quorum is using the voting method to determine whether a quorum exists.
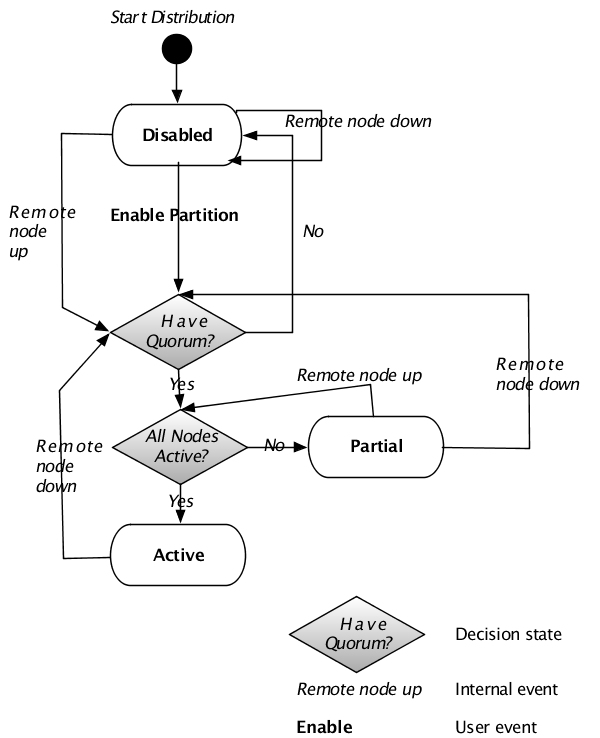
The external events in the state machines map to an API call or an administrator command. The internal events are generated as part of node processing.
There are cases where disabling node quorum is desired. Examples are:
Network connectivity and external routing ensures that requests are always targeted at the same node if it is available.
Geographic redundancy, where the loss of a WAN should not bring down the local nodes.
To support these cases, the node quorum mechanism can be
disabled using configuration (see the TIBCO ActiveSpaces® Transactions
Administration Guide). When node
quorum is disabled, high availability services will never be disabled on
a node because of a lack of quorum. With the node quorum mechanism
disabled, a node can only be in the Active or
Partial node quorum states defined in Table 7.3, “Node quorum states” - it never transitions to the
Disabled state. Because of this, it is possible that
partitions may have multiple active nodes simultaneously.
This section describes how to restore a cluster following a multi-master scenario. These terms are used to describe the roles played by nodes in restoring after a multi-master scenario:
source - the source of the object data. The object data from the initiating node is merged on this node. Installed compensation triggers are executed on this node.
initiating - the node that initiated the restore operation. The object data on this node will be replaced with the data from the source node.
To recover partitions that were active on multiple nodes, support is provided for merging objects using an application implemented compensation trigger. If a conflict is detected, the compensation trigger is executed on the source node to allow the conflict to be resolved.
The types of conflicts that are detected are:
Instance Added - an instance exists on the initiating node, but not on the source node.
Key Conflict - the same key value exists on both the initiating and source nodes, but they are different instances.
State Conflict - the same instance exists on both the initiating and source nodes, but the data is different.
The application implemented compensation trigger is always executed on the source node. The compensation trigger has access to data from the initiating and source nodes.
Figure 7.11, “Active cluster” shows an example cluster
with a single partition, P, that has node
A as the active node and node B as
the replica node.
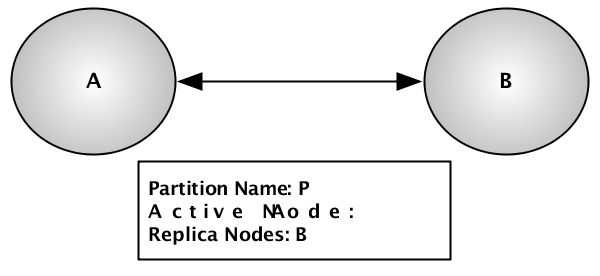
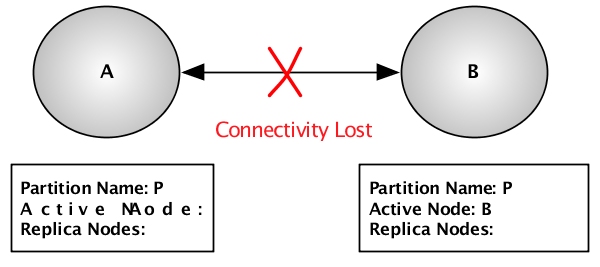
Figure 7.12, “Failed cluster” shows the same cluster after
connectivity is lost between node A and node
B with node quorum disabled. The partition
P definition on node A has been
updated to remove node B as a replica because it is
no longer possible to communicate with node B. Node
B has removed node A from the
partition definition because it believes that node A
has failed so it has taken over responsibility for partition
P.
Once connectivity has been restored between all nodes in the
cluster, and the nodes have discovered each other, the operator can
initiate the restore of the cluster. The restore (see the section called “Restore”) is initiated on the
initiating node which is node A
in this example. All partitions on the initiating
node are merged with the same partitions on the
source nodes on which the partitions are also
active. In the case where a partition was active on multiple remote
nodes, the node to merge from can be specified per partition, when the
restore is initiated. If no remote node is specified for a partition,
the last remote node to respond to the Is partition(n) active?
request (see Figure 7.13, “Merge operation - using broadcast partition discovery”)
will be the source node.
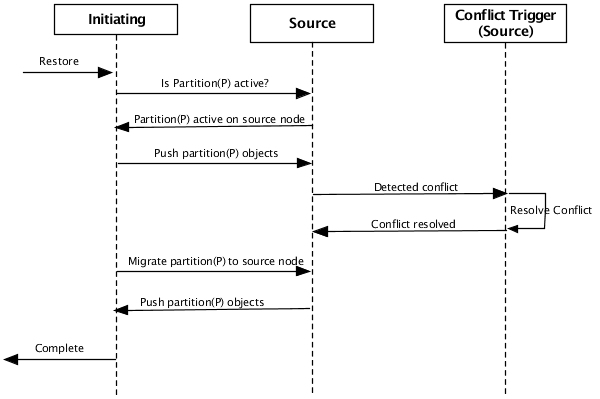
Figure 7.13, “Merge operation - using broadcast partition discovery” shows the steps
taken to restore the nodes in Figure 7.12, “Failed cluster”. The
restore command is executed on node A which is acting
as the initiating node. Node
B is acting as the source
node in this example.
The steps in Figure 7.13, “Merge operation - using broadcast partition discovery” are:
Operator requests restore on
A.Asends a broadcast to the cluster to determine which other nodes have partitionPactive.Bresponds that partitionPis active on it.Asends all objects in partitionPtoB.Bcompares all of the objects received fromAwith its local objects in partitionP. If there is a conflict, any application reconciliation triggers are executed. See the section called “Default conflict resolution” for default conflict resolution behavior if no application reconciliation triggers are installed.AnotifiesBthat it is taking over partitionP. This is done since nodeAshould be the active node after the restore is complete.Bpushes all objects in partitionPtoAand sets the new active node for partitionPtoA.The restore command completes with
Aas the new active node for partitionP(Figure 7.11, “Active cluster”).
The steps to restore a node, when the restore from node was specified in the restore operation are very similar to the ones above, except that instead of a broadcast to find the source node, a request is sent directly to the specified source node.
The example in this section has the A node as the final active node for the partition. However, there is no requirement that this is the case. The active node for a partition could be any other node in the cluster after the restore completes, including the source node.
Figure 7.14, “Split cluster” shows another possible multi-master scenario where the network outage causes a cluster to be split into multiple sub-clusters. In this diagram there are two sub-clusters:
Sub-cluster one contains nodes A and B
Sub-cluster two contains nodes C and C
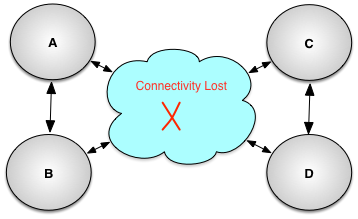
To restore this cluster, the operator must decide which sub-cluster nodes should be treated as the initiating nodes and restore from the source nodes in the other sub-cluster. The steps to restore the individual nodes are identical to the ones described above.
![[Note]](images/note.png) | |
There is no requirement that the initiating and source nodes have to span sub-cluster boundaries. The source and initiating nodes can be in the same sub-clusters. |
The default conflict resolution behavior if no compensation triggers are installed is: